本文汇总了AnalyticDB for MySQL中监控的常见问题及解决方法。
当常见问题场景中未明确产品系列时,表明该问题仅适用于AnalyticDB for MySQL数仓版。
常见问题概览
如何监控数仓版预留集群的磁盘水位?
为防止磁盘使用率超过磁盘安全水位,需要配置监控报警,提前发出报警通知,让您及时知晓磁盘水位并管理磁盘空间,保证业务正常运行。
企业版、基础版及湖仓版集群无需配置磁盘监控告警。
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
在左侧导航栏单击监控报警。
在监控信息页面,单击查询和写入页签,查看磁盘使用量。
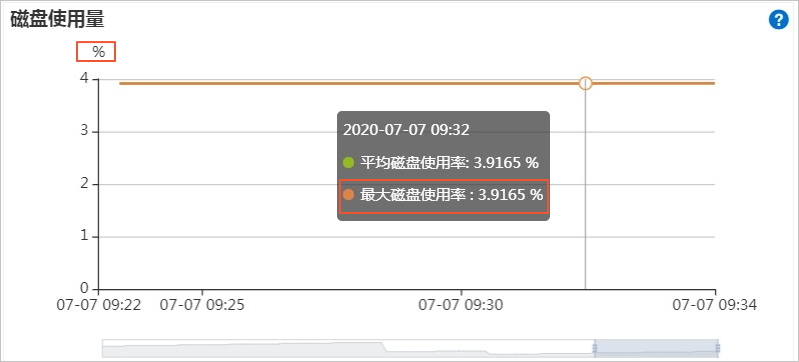
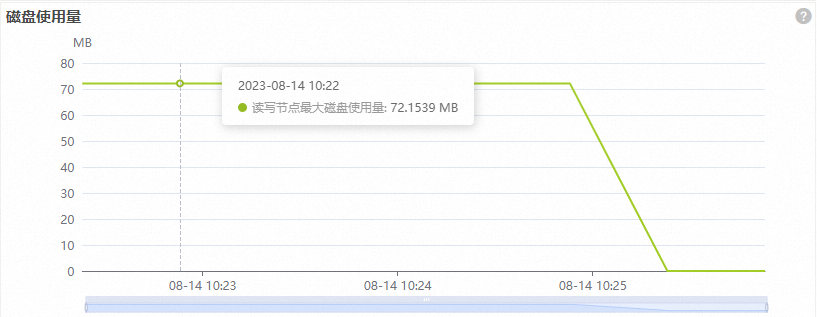
预留模式下,磁盘使用量以百分比形式显示;弹性模式下显示读写节点磁盘的绝对使用量。
预留模式
 说明
说明最大磁盘使用率是指集群实例若干台机器中,磁盘使用量最多的一台,如果该值大于或者等于90%,磁盘将会被锁定。您需要重点关注最大磁盘使用率的值。
弹性模式
 说明
说明磁盘使用量是指单个读写节点的最大磁盘使用量,如果该值大于或等于8 TB,集群将无法写入数据。您需要重点关注磁盘使用量的值。
在报警规则列表页面,单击创建报警规则。
在创建报警规则页面,按照页面提示进行参数配置。
参数
说明
资源范围
报警规则的作用范围,取值说明:
全部资源:表示该规则作用在用户名下对应产品的全部实例上。例如:您设置了全部资源粒度的云原生数据仓库 AnalyticDB MySQL 版磁盘使用率大于或等于80%报警,则只要用户名下有云原生数据仓库 AnalyticDB MySQL 版资源范围选择全部资源时,报警的资源最多1000个,超过1000个可能会导致达到阈值不报警的问题,建议您使用应用分组按业务划分资源后再设置报警。
应用分组:报警规则作用于指定云产品的指定应用分组内的全部资源上。
实例:表示该规则只作用于指定云产品的指定实例上。例如您如果设置了实例粒度的磁盘使用率大于或等于80%报警,则当该实例磁盘使用率大于或者等于80%时,会发送报警通知。
规则描述
报警规则的主体。当监控数据满足报警条件时,触发报警规则。 规则描述的设置方法如下:
单击添加规则。
在添加规则描述面板,设置规则名称、指标类型、监控指标、阈值及报警级别和监控图表预览等。
单击确定。
通道沉默周期
报警发生后未恢复正常,间隔多久重复发送一次报警通知。取值:5分钟、15分钟、30分钟、60分钟、3小时、6小时、12小时和24小时。某监控指标达到报警阈值时发送报警,如果监控指标在通道沉默周期内持续超过报警阈值,在通道沉默周期内不会重复发送报警通知;如果监控指标在通道沉默周期后仍未恢复正常,则云监控再次发送报警通知。
生效时间
报警规则的生效时间,报警规则只在生效时间内才会检查监控数据是否需要报警。
重要磁盘水位报警每个报警联系人一天最多被通知4次,超过4次将被静默。
报警联系人组
发送报警的联系人组。
应用分组的报警通知会发送给该报警联系人组中的报警联系人。报警联系人组是一组报警联系人,可以包含一个或多个报警联系人。关于如何创建报警联系人和报警联系人组,请参见创建报警联系人或报警联系人组。
报警回调
填写公网可访问的URL,云监控会将报警信息通过POST请求推送到该地址,目前仅支持HTTP协议。关于如何设置报警回调,请参见使用阈值报警回调。
说明单击高级设置,可设置该参数。
弹性伸缩
如果您打开弹性伸缩开关,当报警发生时,会触发相应的伸缩规则。您需要设置弹性伸缩的地域、弹性伸缩组和弹性伸缩规则。
说明单击高级设置,可设置该参数。
日志服务
如果您打开日志服务开关,当报警发生时,会将报警信息写入日志服务。您需要设置日志服务的地域、Project和Logstore。
关于如何创建Project和Logstore,请参见快速入门:使用Logtail采集ECS文本日志并分析。
说明单击高级设置,可设置该参数。
轻量消息队列(原 MNS)— topic
如果您打开轻量消息队列(原 MNS)— topic开关,当报警发生时,会将报警信息发送至消息服务的主题。您需要设置消息服务的地域和主题。
关于如何创建主题,请参见创建主题。
无数据报警处理方法
无监控数据时报警的处理方式。取值:
不做任何处理(默认值)
发送无数据报警
视为恢复
说明单击高级设置,可设置该参数。
标签
报警标签会添加到报警内容中。标签名称和标签值是一一对应的,可以设置多对标签。
完成上述参数配置后,单击确认即可。
如何查看热数据和冷数据占用了多少存储空间?
登录云原生数据仓库AnalyticDB MySQL控制台,在监控信息页面查看热数据使用量和冷数据使用量。
如何检查表的大小等信息?
登录云原生数据仓库AnalyticDB MySQL控制台,在集群监控信息页的表信息统计页签下查看表大小等信息。
监控信息页面看到热数据使用量比总数据使用量还多,是什么原因?
AnalyticDB for MySQL集群中包含多个存储节点,磁盘数据使用量是指单个读写节点的最大磁盘使用量,热数据使用量是指所有读写节点的磁盘数据使用量之和。
预留模式跨规格变配为弹性模式后,监控界面看到CPU平均使用率增大,是什么原因?
预留模式C32规格变配为弹性模式,单个节点会降低到8核,Build任务默认占用3核,此时会导致CPU平均使用率增大。CPU平均使用率增大但未影响业务时,您无需关注;若已影响业务的正常运行,请进行升配操作或提交工单联系技术支持。关于Build任务的详细信息,请参见BUILD。
监控信息页面看到有较长的查询响应耗时,但在诊断与优化页面未找到相同耗时的SQL,是什么原因?
监控信息页面的查询响应时间和诊断与优化页面的总耗时的计算方式不同。与诊断与优化页面的总耗时相比,监控信息页面的查询响应时间还包括结果集缓存耗时。因此当查询返回的结果集较大,产生结果集缓存耗时后,监控信息页面显示的查询响应耗时比诊断与优化页面的总耗时长。您可以通过SQL审计页面查询响应时间长的SQL。
SQL耗时的具体说明如下:
SQL在提交至AnalyticDB for MySQL后,首先会在队列中排队,查询并发数较大时,会产生较长的排队时间;查询出队列后,进入执行引擎,解析查询语句,生成执行计划,产生较长的执行计划耗时;执行计划生成后,子任务会在存储节点和计算节点执行,会产生执行耗时;查询结束后,如果返回结果数据量大,会在前端节点缓存返回结果,产生结果集缓存耗时。SQL耗时如下图所示:
