基于节点池管理共享GPU能够为您提供更加灵活的GPU共享调度和显存隔离策略。本文通过在专有版GPU集群中创建两个含标签的节点池示例,介绍如何基于节点池管理共享GPU的调度能力和显存隔离能力。
适用场景
本文所描述的组件,仅支持专有版GPU集群,不支持托管版GPU集群。
若您想在ACK Pro版集群安装共享GPU组件,请参考安装共享GPU调度组件。
前提条件
您已完成以下操作:
规划节点池。
节点池名称可自定义,本文以cgpu和cgpu-no-isolation为例进行阐述。
节点池名称
共享调度
显存隔离
标签
cgpu
是
是
cgpu=true
cgpu.disable.isolation=false
cgpu-no-isolation
是
否
cgpu=true
cgpu.disable.isolation=true
背景信息
在阿里云容器服务Kubernetes版ACK(Container Service for Kubernetes)上使用GPU共享调度时,您可能会遇到以下场景:
训练任务A在代码中已经配置该任务可使用的GPU显存大小,此时集群只需要提供GPU共享调度能力即可,不需要提供GPU显存隔离能力。
训练任务B在代码中没有配置该任务可使用的GPU显存大小,此时集群不仅需要提供GPU共享调度能力,而且还需要提供GPU显存隔离能力。
那如何在一个集群中同时支持这两种场景呢?
基于节点池管理共享GPU的方法同时支持这两种场景。您只需要创建两个节点池:
第一个节点池的节点只提供共享调度能力,不提供显存隔离能力,该节点池只适用于运行训练任务A。
第二个节点池的节点同时提供共享调度能力和显存隔离能力,该节点池只适用于运行训练任务B。
注意事项
在使用节点池管理共享GPU的过程中,需要注意以下两点:
用节点池管理共享GPU时,如果某个任务没有写nodeSelector,那么该任务的Pod可能被调度到任意一个节点池,容易造成结果错乱。
重要强烈建议给任务指定nodeSelector。
如果某个节点的特定标签发生变化(例如:cgpu.disable.isolation=false变为cgpu.disable.isolation=true),需要重启该节点的gpushare-device-plugin,显存隔离的配置才能生效。
重启策略是将旧的gpushare-device-plugin Pod删除后,ACK会自动创建一个新的Pod,具体操作如下:
执行以下命令,查询集群的gpushare-device-plugin Pod。
kubectl get po -n kube-system -l name=gpushare-device-plugin-ds -o wide预期输出:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES gpushare-device-plugin-ds-6r8gs 1/1 Running 0 18h 192.168.7.157 cn-shanghai.192.168.7.157 <none> <none> gpushare-device-plugin-ds-pjrvn 1/1 Running 0 15h 192.168.7.158 cn-shanghai.192.168.7.158 <none> <none>以cn-shanghai.192.168.7.157节点为例,执行以下命令,删除gpushare-device-plugin Pod。
kubectl delete po gpushare-device-plugin-ds-6r8gs -n kube-system
步骤一:创建节点池
登录容器服务管理控制台。
在控制台左侧导航栏,单击集群。
在集群列表页面,单击目标集群名称或者目标集群右侧操作列下的详情。
在集群管理页左侧导航栏,选择。
在节点池页面右上角,单击创建节点池。
在创建节点池页面,设置节点池的配置项。
有关配置项的详细说明,请参见创建Kubernetes托管版集群。部分配置说明如下:
数量:设置节点池初始节点数量。如不需要创建节点,可以填写为0。
操作系统:选择节点的操作系统,包括CentOS 7.x、Alibaba Cloud Linux 2.x。
节点标签:您可以为集群节点添加标签。
ECS标签:您可以为ECS实例添加标签。
自定义资源组:您可以指定节点池所扩容节点的资源组信息。
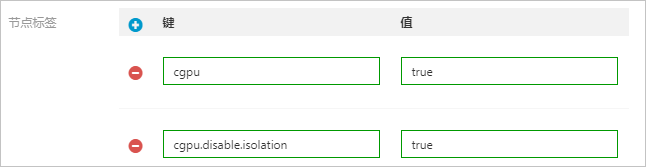
其中,在节点标签区域为每个节点池打上特定的标签。
节点池cgpu需要的特定标签:cgpu=true、cgpu.disable.isolation=false
节点池cgpu-no-isolation需要的特定标签:cgpu=true、cgpu.disable.isolation=true
以节点池cgpu-no-isolation为例:
单击确认配置。
在节点池页面,如果节点池状态显示初始化中,则说明节点池正在创建中。创建完成后,状态显示为已激活。
如果您需要增加GPU节点,可对该节点进行扩容。具体操作,请参见创建节点池。
步骤二:提交任务
提交cgpu-test和cgpu-test-no-isolation两个任务,在部署任务的YAML文件中均需要指定nodeSelector。
cgpu-test:该任务的代码中没有设置可用的GPU显存大小,需要借助共享的显存隔离能力才能正常运行。示例YAML配置如下:
apiVersion: batch/v1 kind: Job metadata: name: cgpu-test spec: parallelism: 1 template: metadata: labels: app: cgpu-test spec: nodeSelector: cgpu.disable.isolation: "false" # 添加nodeSelector,选择节点池cgpu。 containers: - name: cgpu-test image: registry.cn-hangzhou.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5 command: - python - tensorflow-sample-code/tfjob/docker/mnist/main.py - --max_steps=100000 - --data_dir=tensorflow-sample-code/data resources: limits: # 单位为GiB,该Pod总共申请了3 GiB显存。 aliyun.com/gpu-mem: 3 workingDir: /root restartPolicy: Never说明nodeSelector:指定节点池为cgpu。
cgpu.disable.isolation=false:表示将任务调度到节点池cgpu的节点上运行。
aliyun.com/gpu-mem:设置GPU显存大小。
cgpu-test-no-isolation:该任务的代码中设置了每个GPU可用显存大小,不需要借助cgpu的显存隔离能力。示例YAML配置如下:
apiVersion: batch/v1 kind: Job metadata: name: cgpu-test-no-isolation spec: parallelism: 1 template: metadata: labels: app: cgpu-test-no-isolation spec: nodeSelector: cgpu.disable.isolation: "true" # 添加nodeSelector,选择节点池cgpu-no-isolation。 containers: - name: cgpu-test-no-isolation image: registry.cn-hangzhou.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5 command: - python - tensorflow-sample-code/tfjob/docker/mnist/main.py - --max_steps=100000 - --data_dir=tensorflow-sample-code/data resources: limits: # 单位为GiB,该Pod总共申请了3 GiB显存。 aliyun.com/gpu-mem: 3说明nodeSelector:指定节点池为cgpu-no-isolation。
cgpu.disable.isolation=true:表示将任务调度到节点池cgpu-no-isolation的节点上运行。
aliyun.com/gpu-mem:设置GPU显存大小。
步骤三:查看执行结果
执行以下命令,查看任务状态。
kubectl get po预期输出:
NAME READY STATUS RESTARTS AGE cgpu-test-0 1/1 Running 0 5m55s cgpu-test-no-isolation-0 1/1 Running 0 6m42s在Pod cgpu-test-0(需要显存隔离的任务)执行命令
nvidia-smi,查看容器可使用的显存。kubectl exec cgpu-test-0 -- nvidia-smi预期输出:
Mon Nov 2 11:33:10 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:07.0 Off | 0 | | N/A 34C P0 54W / 300W | 3039MiB / 3226MiB | 1% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+容器可使用的显存为3226 MiB(该GPU卡的总显存为16 GiB),说明共享GPU的显存隔离能力已生效。
在Pod cgpu-test-no-isolation-0(不需要显存隔离的任务)执行
nvidia-smi,查看容器可使用的显存。kubectl exec cgpu-test-no-isolation-0 -- nvidia-smi预期输出:
Mon Nov 2 11:39:59 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:07.0 Off | 0 | | N/A 37C P0 56W / 300W | 1929MiB / 16130MiB | 1% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+容器可发现的显存为16130 MiB(该GPU卡的总显存为16 GiB),说明共享GPU的显存隔离能力已被关闭,此种情况下,容器中的应用程序需要通过以下环境变量获取自己能够使用的显存大小。执行以下命令,获取能够使用的显存大小。
kubectl exec cgpu-test-no-isolation-0 -- env | grep ALIYUN预期输出:
ALIYUN_COM_GPU_MEM_CONTAINER=3 # 在某张卡上,该容器被允许使用的显存大小,此处代表3 GiB。 ALIYUN_COM_GPU_MEM_DEV=15 # 这张卡的总显存大小。 ...对比在Pod cgpu-test-no-isolation-0和cgpu-test-0中执行
nvidia-smi的结果。cgpu-test-no-isolation-0显示整张GPU卡的显存,而cgpu-test-0只能显示申请的GPU显存大小,说明基于节点池可以有效管理共享GPU。