相容特徵及功能函數項
兼有功能及特徵函數的功能,可以同時在filter、sort及formula運算式中使用。
其中函數參數出現的文檔欄位需根據對應函數文檔提示,建立為索引或屬性.
tag_match : 用於對查詢語句和文檔做標籤匹配,使用匹配結果對文檔進行算分加權
1.情境概述:
涉及query和文檔匹配的很多需求都可以使用或者轉化為tag_match來滿足,對實現搜尋個人化需求尤其有用。例如優先出現使用者點贊過的店鋪,優先展現使用者喜歡的體育和娛樂類新聞等。tag_match最基本的功能是在文檔的某個ARRAY欄位中儲存一系列的key-value資訊。然後在查詢query中通過kvpairs子句傳遞對應的key-value資訊,tag_match就會去文檔中尋找查詢query中的key, 然後為每個匹配的key計算得到一個分數,再合并所有匹配的key的分數得到一個最終分。這個結果就可以用來做算分加權或者過濾。
計算過程如下:
2.詳細用法:
常見用法:
tag_match(query_key, doc_field, kv_op, merge_op)
進階用法:
tag_match(query_key, doc_field, kv_op, merge_op, has_default, doc_kv, max_kv_count)
3.參數:
query_key:指定查詢語句中用於匹配的欄位key-value值,該欄位需要通過kvpairs子句傳遞,key與value通過英文等號‘=’分隔,多個key-value通過英文冒號‘:’分隔,如: kvpairs=query_tags:10=0.67:960=0.85:1=48//表示參數query_tags中包含3個元素:10、960、1,其對應的value分別是:0.67、0.85、48。其中query也可以只為key的列表,如:kvpairs=cats:10:960:1。
doc_field:指定文檔中儲存key-value的欄位名,該欄位只支援整型【int_array】或者浮點型【float_array,double_array】數組欄位類型(如果是浮點型數組欄位類型,則key的值匹配的時強轉當int64來處理)。數組的奇數位置是key,下一個相鄰的偶數位置為key的value。即 [key0 value0 key1 value1 …]
kv_op:當query_key中的值與doc_field中的key匹配時對二者的value所採取的操作,目前支援的操作符如下:max(最大值)、min(最小值)、sum(求和)、avg(平均數)、mul(乘積)、query_value(query_key中該key對應的value值)、doc_value(文檔中該key對應的value值)、number(常數)。
merge_op:多個key匹配後會產生多個結果,merge_op指定了將這些結果進行如何操作,目前支援的操作類型如下:max(最大值)、min(最小值)、sum(求和)、avg(平均值)、first_match(取第一個kv_op的計算結果,忽略其他結果)。
has_default:預設是false,表示不啟動初始分值;為true時說明doc_field的第一個值為預設值,[init_score k0 v0 k1 v1…]。(類似base分值的概念)
doc_kv:預設是true。表明doc_field欄位中的值是以key-value對的形式存在;為false則表示doc_field中只包含key資訊。
max_kv_count:因為查詢中的key-value結構需要通過query傳遞,所有tag_match對query中能傳遞多少key-value有限制。預設為50,可以通過這個參數將這個限制調大,但是最大不能超過5120。
4.傳回值:
double,返回具體的分值,如果has_default為false並且沒有配額的內容則為0.如果需要返回int64的結果,需要使用int_tag_match,該函數功能與參數與int_tag_match完全一致,但int_tag_match不能在排序運算式中使用。
5.適用情境
情境1:一個大型的綜合性論壇,文章可以被打上各種各樣的標籤(搞笑,體育,新聞,音樂,科普..)。我們在推送給OpenSearch的文檔中,可以為每個標籤賦予一個標籤id(例如搞笑-1, 體育-5, 新聞-3, 音樂-6..), 然後通過一個tag欄位儲存這些標籤。 如果我們對文章做過預先處理,甚至能得到每個文章每個標籤的權重,例如一個搞笑體育新聞的文章可以得到搞笑的權重為0.5,體育的權重為0.5,新聞權重為0.1,則這個文章的tag欄位的值為[1 0.5 5 0.5 3 0.1]對會員使用者,通過長時間的積累,我們能獲知每個使用者的興趣標籤。
例如使用者nba_fans對體育和搞笑高度興趣,他對應的體育和搞笑標籤的權重分別為0.6和0.3。那麼這個使用者查詢時,我們就可以通過kv_pairs子句把這個資訊加到query裡面。假如這個kv_pairs子句名字為user_tag, 那麼nba_fans的user_tag的值5=0.6:1=0.3。這樣,我們只要在精排運算式中配置了tag_match(user_tag, tag, mul, sum), 我們就能夠實現對使用者感興趣的文章加權,把使用者更感興趣的文章排到前面。
例如nba_fans搜尋到上面那個文章時,搞笑和體育這兩個標籤能夠匹配到。通過指定kv_op參數為mul,我們會把query和doc中的值相乘,他們各自的計算分數分別為(體育:0.5 * 0.6 = 0.3, 搞笑:0.5 * 0.3 = 0.15)。通過指定merge_op參數為sum,我們會把體育和搞笑的分數加和(0.3+0.15 = 0.45),這個加和的分數會加到最終的排序分數上。這樣,我們就能夠實現了對這個使用者感興趣文章的排序加權。
情境2:
商品可以具有多個屬性標籤,如1表示年輕人(年齡)、2表示中年人(年齡)、3表示小清新(風格)、4表示時尚(風格)、5表示女性(性別)、6表示男性(性別)等。
假設我們只想表示商品有沒有某個標籤,不想區分哪個標籤更重要。這個標籤通過options欄位來儲存。那麼年輕時尚女性的衣服的options欄位可以表示為[1 4 5], 注意這裡只有標籤key,沒有value。使用者也都有自己的屬性標籤,和商品標籤對應。例如年輕女性使用者,歷史成交中多購買小清新風格衣服。這該使用者的查詢可以寫為user_options=1:3:5。注意這裡kv_pair中也是只有標籤key,沒有value的。
要實現對符合使用者標籤喜好的商品加權,我們可以在formula中使用tag_match(user_options, options, 10, sum, false, false)。這裡我們通過user_options和options指定了query和doc的標籤資訊。kv_op設為常數10,表示只要有標籤匹配到,那麼匹配的計算結果就是10。has_default為false,表示我們不需要初始值。doc_kv為false,表示我們doc中只儲存了key資訊,沒有value。
這樣,上面的年輕女使用者查詢到上面的衣服時,女性和年輕兩個標籤能夠匹配上,這兩個標籤的計算結果都是10。通過sum這個merge_op,能夠得到這件商品的最終加權分數為20。通過這種方式,即使我們沒有標籤的權重資訊,也能夠實現對匹配到的文檔做排序加權。
注意事項
函數參數依賴欄位需建立為屬性
如果是用在filter或者sort子句中,則query_key、kv_op、merge_op、has_default、doc_kv必須使用雙引號括起來,如:sort=-tag_match(“user_options”, options, “mul”, “sum”, “false”, “true”, 100)。
tag_match的key匹配都是通過整數比較來完成的。因此query和doc中的key都應該轉換為整數形式,如果是浮點類型,tag_match在比較時,會強制轉換為整數類型。
案例示範
假設文檔內容共有如下10類型的標籤:
1-財經
2-科技
3-體育
4-娛樂
5-時尚
6-教育
7-旅遊
8-遊戲
9-科普
10-醫學案例1:關鍵詞相同,但是標籤不同的title:
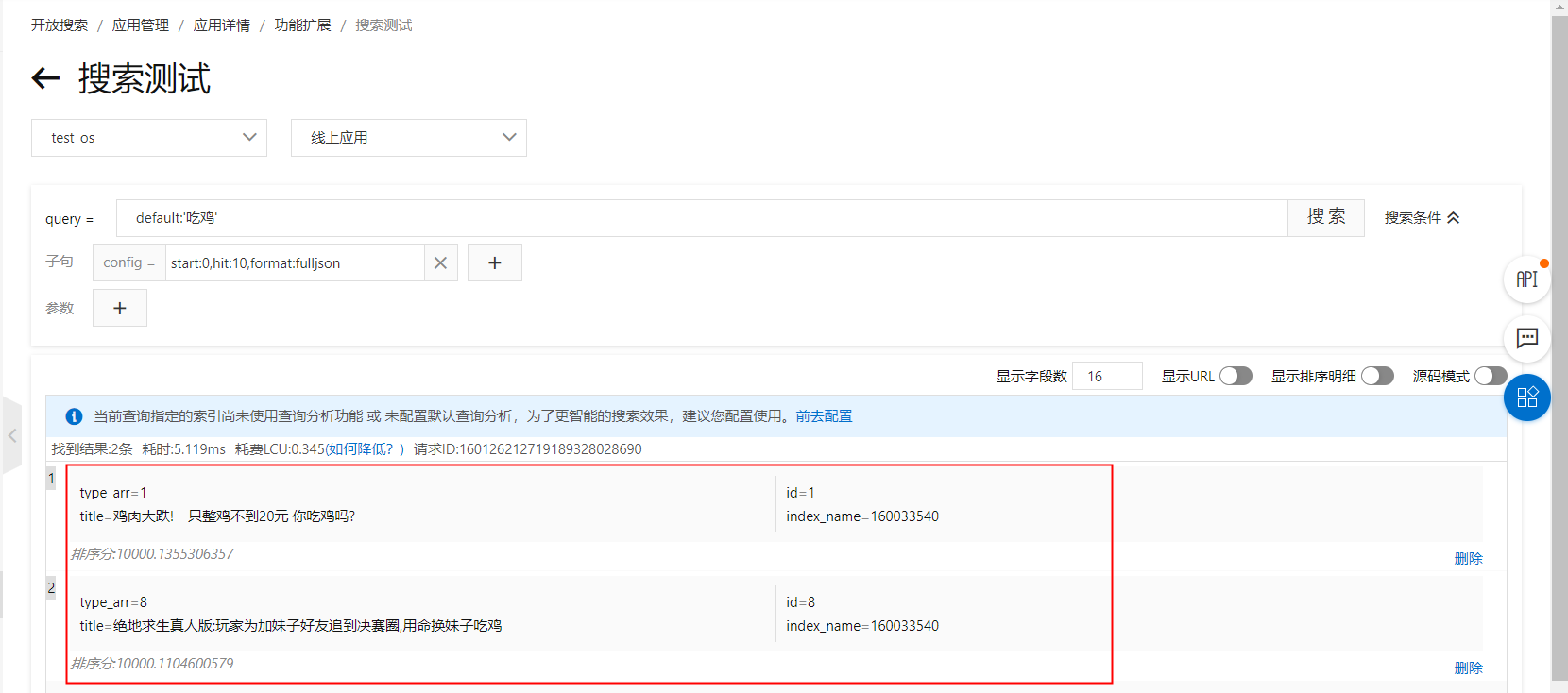 如上圖所示,搜尋“吃雞”出現兩篇doc,但是二者的類型不同,分別是1-財經、8-遊戲,如果想將“遊戲”標籤的文檔在前面展示,可設定tag_match函數,以下分別示範配置在排序運算式和sort子句中的方法:
如上圖所示,搜尋“吃雞”出現兩篇doc,但是二者的類型不同,分別是1-財經、8-遊戲,如果想將“遊戲”標籤的文檔在前面展示,可設定tag_match函數,以下分別示範配置在排序運算式和sort子句中的方法:
kvpairs:type:8
排序運算式:tag_match(type, type_arr, 10, max,false,false)
sort子句:tag_match("type", type_arr, 10, "max","false","false")排序運算式展示的結果: sort子句展示的結果:
sort子句展示的結果: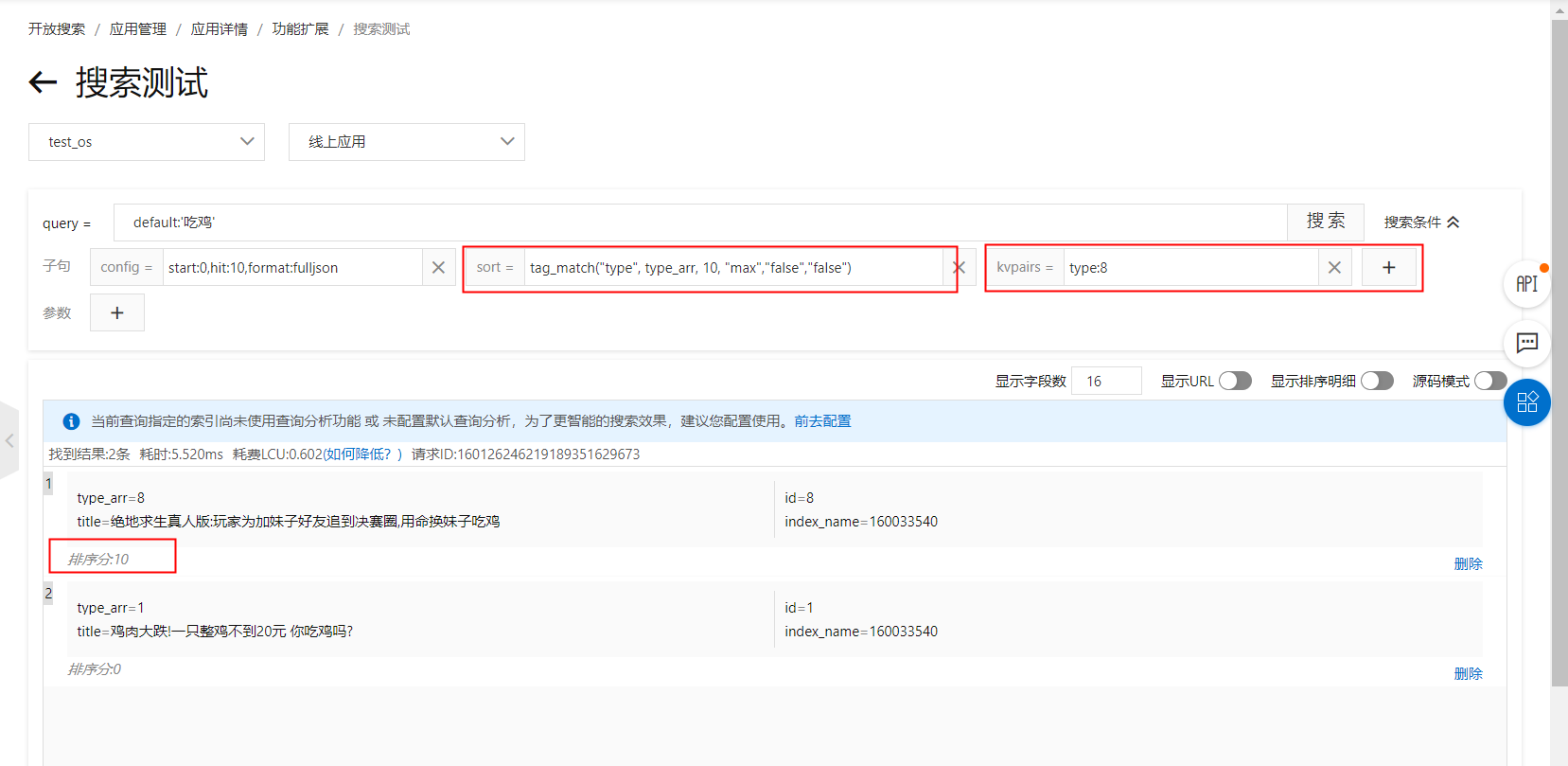
案例2:多標籤綜合得分展示(可針對使用者的個人化推薦)
 如圖,在一級標籤相同的情況下,需要匹配二級標籤的得分,以下分別示範配置在排序運算式和sort子句中的方法:
如圖,在一級標籤相同的情況下,需要匹配二級標籤的得分,以下分別示範配置在排序運算式和sort子句中的方法:
kvpairs:type:3=2:10=1
排序運算式:tag_match(type, type_arr, 10, sum,false,true)
sort子句:tag_match("type", type_arr, 10, "sum","false","true")
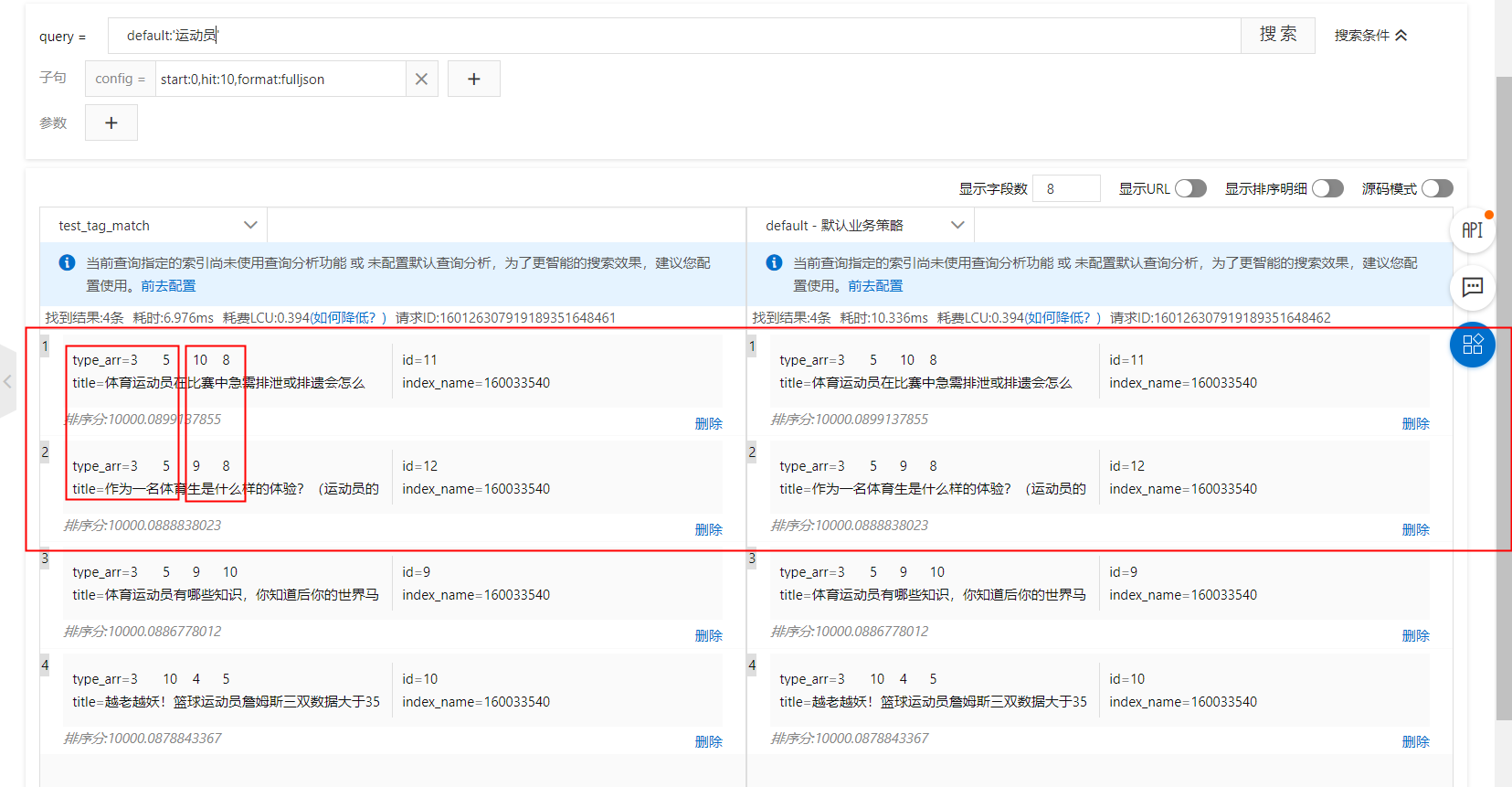
案例3:多標籤同類型,不同得分
 如圖,紅框展示的內容,都同屬於同樣的標籤,但是每個標籤的打分不同,以下分別示範配置在排序運算式和sort子句中的方法:
如圖,紅框展示的內容,都同屬於同樣的標籤,但是每個標籤的打分不同,以下分別示範配置在排序運算式和sort子句中的方法:
kvpairs:type:3=2:9=2
排序運算式:tag_match(type, type_arr, sum, sum,false,true)
sort子句:tag_match("type", type_arr, "sum", "sum","false","true")
Java sdk 樣本參考:Java sdk 搜尋Demo