當您的MongoDB執行個體中存在過多的庫表時,可能會遇到資料庫效能退化以及其他問題。
資料庫中常說的庫和表分別對應MongoDB中的資料庫(Database)和集合(Collection)。
在MongoDB中,WiredTiger儲存引擎會為每一張表都建立對應的磁碟檔案,每一個單獨的索引也會成為一個新的磁碟檔案。WiredTiger引擎中每一個開啟的資源(比如檔案系統對象)都會有一個對應的dhandle資料結構,儲存了包括checkpoint資訊、會話的引用計數、指向記憶體B+樹結構的指標、統計資料資訊等等。
因此,MongoDB中庫表數量越多,WiredTiger引擎層開啟作業系統檔案對象的數量越多,相對應的記憶體dhandle資料結構也就越多。當大量的dhandle結構都存在記憶體中時,會出現相關鎖的爭搶,進而導致資料庫執行個體的效能退化。
可能遇到的問題
鎖(handleLock或者schemaLock)導致的慢查詢,請求延遲變大。
庫表數多導致的慢日誌可能如下:
2024-03-07T15:59:16.856+0800 I COMMAND [conn4175155] command db.collections command: count { count: "xxxxxx", query: { A: 1, B: 1 }, $readPreference: { mode: "secondaryPreferred" }, $db: "db" } planSummary: COLLSCAN keysExamined:0 keysExaminedBySizeInBytes:0 docsExamined:1 docsExaminedBySizeInBytes:208 numYields:1 queryHash:916BD9E3 planCacheKey:916BD9E3 reslen:185 locks:{ ReplicationStateTransition: { acquireCount: { w: 2 } }, Global: { acquireCount: { r: 2 } }, Database: { acquireCount: { r: 2 } }, Collection: { acquireCount: { r: 2 } }, Mutex: { acquireCount: { r: 1 } } } storage:{ data: { bytesRead: 304, timeReadingMicros: 4 }, timeWaitingMicros: { handleLock: 40, schemaLock: 134101710 } } protocol:op_query 134268ms上述慢日誌表示使用者對只有1條文檔的集合進行了簡單的Count操作,但是花費了很長時間。日誌的
timeWaitingMicros: { handleLock: 40, schemaLock: 134101710 } } protocol:op_query 134268ms部分表示讀請求受到庫表數量太多的影響,在等待擷取底層儲存的handleLock和schemaLock上花費了過多時間。添加新節點時在初始化同步階段OOM。
執行個體的啟動時間變長。
資料同步時間變長。
備份恢復變長。
物理備份失敗率提升。
故障恢復變長。
庫表數量多不一定會出現問題,是否出現問題與業務模型和負載等因素也有關係。例如以下兩種業務情境,資料庫規格相同且都有1萬的庫表數和10萬的總檔案數,但面臨的問題完全不一樣:
會計軟體系統:訪問具備明顯的聚集性特徵,大多數庫表只作為冷資料存放區,經常訪問的庫表只有近期的一小部分。
多租戶管理系統:租戶之間用表隔離,幾乎所有的表都會被訪問或使用。
最佳化方法
移除不需要的集合
查詢資料庫中哪些集合是可以刪除的(例如已到期或業務不再使用的集合),通過dropCollection命令直接刪除這些無用表。關於刪除命令的介紹,請參見dropCollection()。
在執行刪除操作前,請確保您有一個可用的全量備份。
查看資料庫和集合資訊的命令如下:
執行以下命令查看資料庫中集合的數量。
db.getSiblingDB(<dbName>).getCollectionNames().length執行以下命令查看關於資料庫的具體資訊,包括集合的數量,索引的數量,文檔條數,總資料量大小等資訊。
//查看某個庫的統計資訊 db.getSiblingDB(<dbName>).stats()執行以下命令查看某個集合的具體資訊。
//查看某個表的統計資訊 db.getSiblingDB(<dbName>).<collectionName>.stats()
移除不需要的索引
降低索引的數量也可以減少WiredTiger儲存引擎層維護的磁碟檔案以及相應的dhandle結構,同樣有助於緩解本問題。
索引最佳化的一些基本原則如下:
避免無用索引
查詢根本不會訪問到的欄位,索引也自然不會命中,屬於無用索引,可以刪除。
索引的首碼匹配規則
例如
{a:1}和{a:1,b:1}兩個索引,前者就屬於首碼匹配的冗餘索引,可以刪除。等值查詢時的索引欄位順序
例如
{a:1,b:1}和{b:1,a:1}兩個索引,在等值匹配中,順序並不會有影響,可以刪除其中叫用次數更少的一個。範圍查詢時參考ESR規則
根據實際的業務範圍查詢,按照
quality, Sort, Range的順序來構造最優的複合索引。更多資訊,請參見The ESR Rule。review叫用次數低的索引
叫用次數低的索引基本上都和另外一個高效索引存在一定的重複,需要結合業務的所有查詢模式來判斷是否可以刪除。
您可以通過MongoDB的$indexStats彙總階段來查看某個表中所有索引的統計資訊。請在確保有相關許可權的前提下,執行下面的命令。
//查看某個表的索引統計資訊
db.getSiblingDB(<dbName>).<collectionName>.aggregate({"$indexStats":{}})返回樣本如下。
{
"name" : "item_1_quantity_1",
"key" : { "item" : 1, "quantity" : 1 },
"host" : "examplehost.local:27018",
"accesses" : {
"ops" : NumberLong(1),
"since" : ISODate("2020-02-10T21:11:23.059Z")
}
}返回資訊參數說明如下。
欄位 | 描述 |
name | 索引名稱。 |
key | 索引鍵詳細資料。 |
accesses.ops | 使用了該索引的運算元,相當於索引命中的次數。 |
accesses.since | 開始收集統計資訊的時間(執行個體重啟或者索引重建會導致該欄位以及ops欄位重設)。 |
如果觀察到索引叫用次數很少(例如樣本中的accesses.ops為1),則很大機率該索引是冗餘索引或無用索引,可以考慮刪除。如果您的MongoDB執行個體版本為4.4及以上,為了進一步降低刪除索引的風險,您可以在dropIndex之前通過hiddenIndex命令先隱藏對應索引,確認一段時間內業務無異常後再進行索引刪除的操作。
樣本
假設一個遊戲玩家集合,規則為“每當玩家收集了20個coins,則轉換成1個stars”,集合中的文檔如下:
// players collection
{
"_id": "ObjectId(123)",
"first_name": "John",
"last_name": "Doe",
"coins": 11,
"stars": 2
}目前表裡的索引包括下面5個,覆蓋了所有欄位:
_id(預設索引){ last_name: 1 }{ last_name: 1, first_name: 1 }{ coins: -1 }{ stars: -1 }
索引最佳化邏輯如下:
業務查詢不會訪問
coins欄位,因此{ coins: -1 }是無用索引。根據前面提到的索引首碼匹配規則,
{ last_name: 1, first_name: 1 }包含了{ last_name: 1 },因此可以刪除{ last_name: 1 }索引。通過
$indexStats命令觀察到{ stars: -1 }的叫用次數很低,但考慮到業務上一整輪遊戲結束時需要按照玩家的stars數量進行逆序排序來展示結算熱門排行榜,因此儘管並不常用,{ stars: -1 }也需要保留來避免掃描所有文檔。
最佳化後,集合中還剩下3個索引:
_id{ last_name: 1, first_name: 1 }{ stars: -1 }
最佳化後的收益如下:
儲存空間下降。
寫入效能提升。
如果您還有關於索引最佳化的更多問題,請提交工單聯絡阿里雲支援人員協助解決。
整合多表資料
將多個集合中的資料整合到單個集合中以減少集合數量。
例如,資料庫中有一個temperatures庫,用來儲存從感應器獲得的所有溫度資料。感應器從上午10點工作到晚上10點,每半小時讀取一次當時的溫度資料並儲存在資料庫中。每一天的溫度資料存放在一個單獨的以日期為命名的集合中。
以下展示了2個集合(分別是temperatures.march-09-2020和temperatures.march-10-2020)的部分資料的內容。
集合
temperatures.march-09-2020{ "_id": 1, "timestamp": "2020-03-09T010:00:00Z", "temperature": 29 } { "_id": 2, "timestamp": "2020-03-09T010:30:00Z", "temperature": 30 } ... { "_id": 25, "timestamp": "2020-03-09T022:00:00Z", "temperature": 26 }集合
temperatures.march-10-2020{ "_id": 1, "timestamp": "2020-03-10T010:00:00Z", "temperature": 30 } { "_id": 2, "timestamp": "2020-03-10T010:30:00Z", "temperature": 32 } ... { "_id": 25, "timestamp": "2020-03-10T022:00:00Z", "temperature": 28 }
隨著時間的推移,資料庫中的集合數量也在增加,由於MongoDB並沒有明確的集合數量上限,而且樣本中也並沒有明確的資料生命週期關係,因此資料庫所維護的集合數量及其相應索引數量不斷增長。
除了庫表數不斷上漲的問題,這種建模還不便於執行跨天查詢。若要查詢多天的資料以獲得較長時間內的溫度趨勢,您需要執行基於$lookup的查詢,其效能不如針對同一集合內的查詢。
更優的資料建模是將所有溫度讀數儲存在單個集合中,並將每天的溫度資料存放區在單個文檔中。最佳化後的樣本如下。
// temperatures.readings
{
"_id": ISODate("2020-03-09"),
"readings": [
{
"timestamp": "2020-03-09T010:00:00Z",
"temperature": 29
},
{
"timestamp": "2020-03-09T010:30:00Z",
"temperature": 30
},
...
{
"timestamp": "2020-03-09T022:00:00Z",
"temperature": 26
}
]
}
{
"_id": ISODate("2020-03-10"),
"readings": [
{
"timestamp": "2020-03-10T010:00:00Z",
"temperature": 30
},
{
"timestamp": "2020-03-10T010:30:00Z",
"temperature": 32
},
...
{
"timestamp": "2020-03-10T022:00:00Z",
"temperature": 28
}
]
}最佳化後的模式需要消耗的資源比原始模式少得多。現在,您不再需要根據每天讀取溫度的時間建立索引,集合上的預設索引_id有助於按日期進行查詢。同時也解決了庫表數不斷增長的問題。
時序資料您也可以考慮使用時序集合(Time Series Collections)功能來解決上述問題。
時序集合功能僅MongoDB 5.0及以上版本支援。
執行個體拆分
在MongoDB單一實例下總庫表數無法降低的情況下,可以考慮對該資料庫執行個體進行邏輯拆分並進行配套的業務整改。
可以分成以下兩種情境處理:
情境 | 拆分方案 | 注意事項 |
集合(collections)分布在多個庫(databases)中 | 如果庫之間的業務相互關聯性並不大(例如多個應用或服務共用使用同一個資料庫執行個體),可以通過ApsaraDB for MongoDB(複本集架構)遷移至ApsaraDB for MongoDB(複本集架構或分區叢集架構)將部分庫遷移到一個新的MongoDB執行個體。在遷移完成前,商務邏輯和訪問方式也需要配套進行拆分。 如果庫之間的業務關聯性比較大,請參考單庫情境的拆分方案。 |
|
集合(collections)集中在1個庫(database)中 | 需要業務側先判斷是否可以按某個維度對所有的表進行拆分,比如地區、城市、優先順序或其他任何業務上有意義的維度。 然後通過DTS將部分表遷移到一個或者多個新的MongoDB執行個體,完成1拆N的目的。在遷移完成前商務邏輯和訪問方式需要配套進行拆分。 |
|
樣本
某個多租戶管理平台系統使用了MongoDB資料庫,初期建模時以每一個租戶為一個單獨的集合。隨著業務不斷髮展,租戶的數量已達到了十萬以上的量級,資料庫整體的資料量也達到了TB級,執行個體經常出現資料庫訪問慢以及延遲高的問題。
業務側在拆分時選擇按照地區的維度,將國內的租戶分為了華北、東北、華東、華中、華南、西南、西北幾個地區。在對應的地區可用性區域分別建立全新的MongoDB執行個體並進行了多輪DTS遷移。同時,為了滿足業務側彙總分析的需求,建立了MongoDB執行個體到數倉的同步。
拆分完成後,單個MongoDB的庫表數大幅下降,執行個體規格也相應降低。同時,業務側按地區基於就近訪問原則,使得請求訪問延時縮短到ms層級,大幅提升了業務的產品使用體驗,後續的執行個體營運也變得更加簡單。
遷移到分區叢集執行個體並使用分區標籤(Shard Tag)來管理
如果所有的集合都集中在一個庫中,而且還希望通過一個邏輯上的資料庫執行個體來管理的話,您可以考慮將資料移轉到分區叢集架構並使用分區標籤(Shard Tag)來進行管理。shard tag管理方式稍微複雜一些,需要一些額外的營運操作(sh.addShardTag和sh.addTagRange),但所有的表依然由同一個MongoDB執行個體管理,業務上基本不需要改造,只需要將串連串替換為新的分區叢集執行個體的串連串即可。
假如您的執行個體中有10萬個活躍集合,可以新購一個10個Shard節點的分區叢集執行個體,通過以下流程完成設定並遷移資料,可實現每個Shard節點上各1萬個活躍集合。操作步驟如下:
新購一個分區叢集執行個體,本文以2個分區的執行個體為例。如何建立分區叢集,請參見建立分區叢集執行個體。
串連分區叢集執行個體的mongos節點,如何串連資料庫,請參見通過Mongo Shell串連MongoDB分區叢集執行個體。
執行如下命令為所有分區添加標籤(Shard Tag)。
sh.addShardTag("d-xxxxxxxxx1", "shard_tag1") sh.addShardTag("d-xxxxxxxxx2", "shard_tag2")說明執行相關命令前請確保您使用的賬戶具備相應的許可權。
DMS暫不支援
sh.addShardTag,建議您使用mongo shell或者mongosh串連執行個體執行相關命令。
為所有的分區表提前設定範圍的標籤分布規則。
use <dbName> sh.enableSharding("<dbName>") sh.addTagRange("<dbName>.test", {"_id":MinKey}, {"_id":MaxKey}, "shard_tag1") sh.addTagRange("<dbName>.test1", {"_id":MinKey}, {"_id":MaxKey}, "shard_tag2")樣本中選擇
_id作為分區鍵,實際使用時請按需選擇,確保所有的查詢操作都包含分區鍵欄位。分區鍵需要與下一個操作裡的欄位保持一致。同時需要使用[MinKey,MaxKey]的上下邊界,使得一個表的所有資料僅存在於單個分區上。對於所有的待遷移表都執行shardCollection操作。
sh.shardCollection("<dbName>.test", {"_id":1}) sh.shardCollection("<dbName>.test1", {"_id":1})通過
sh.status()命令來確認相關規則已生效。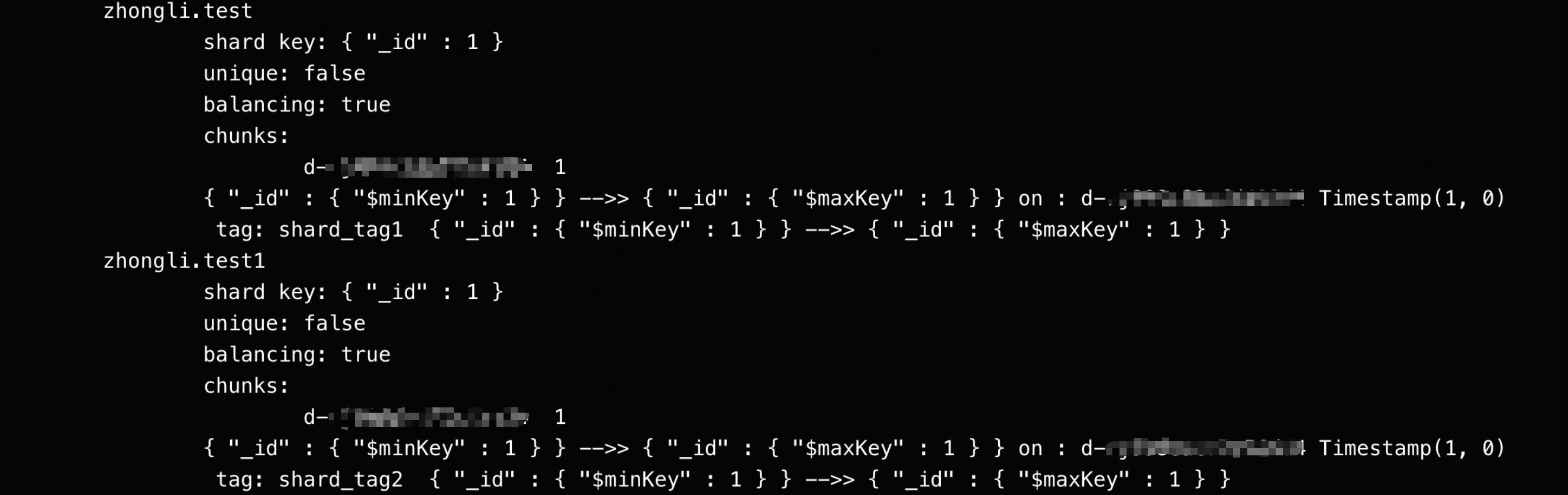
將資料從複本集執行個體遷移到分區叢集執行個體中。
說明由於已經在目標執行個體上進行了分區操作,所有庫表資訊已存在,因此需要配置目標已存在表的處理模式為忽略報錯並繼續執行。
資料校正一致後將業務切換到訪問新的分區叢集執行個體。
如果需要為執行個體增加分區,需要執行上述操作中的步驟3,為所有新增的分區添加標籤。
如果資料庫後續會持續新增集合,需要執行上述操作中的步驟4和步驟5。如果不執行這兩個步驟,庫表將只會存在主分區上,導致主分區上庫表數越來越多,然後再次遇到執行個體卡頓或異常的問題。
遷移到分區叢集執行個體並使用分區(Zones)來管理
本方法與使用分區標籤管理方法類似,不過使用的是MongoDB的分區(Zones)功能,需要額外的營運操作(分別為sh.addShardToZone()以及sh.updateZoneKeyRange())。
操作步驟如下:
新購一個分區叢集執行個體,本文以2個分區的執行個體為例。如何建立分區叢集,請參見建立分區叢集執行個體。
串連分區叢集執行個體的mongos節點,如何串連資料庫,請參見通過Mongo Shell串連MongoDB分區叢集執行個體。
執行如下命令為所有分區指定分區(Zones)。
sh.addShardToZone("d-xxxxxxxxx1", "ZoneA") sh.addShardToZone("d-xxxxxxxxx2", "ZoneB")說明執行相關命令前請確保您使用的賬戶具備相應的許可權。
DMS暫不支援
sh.addShardToZone,建議您使用mongo shell或者mongosh串連執行個體執行相關命令。
為所有的表提前設定範圍的分區分布規則。
use <dbName> sh.enableSharding("<dbName>") sh.updateZoneKeyRange("<dbName>.test", { "_id": MinKey }, { "_id": MaxKey }, "ZoneA") sh.updateZoneKeyRange("<dbNmae>.test1", { "_id": MinKey }, { "_id": MaxKey }, "ZoneB")樣本中選擇
_id為分區鍵,實際使用時請按需選擇,確保所有的查詢操作都包含分區鍵欄位。分區鍵需要跟下一個操作裡的欄位保持一致。同時需要使用[MinKey,MaxKey]的上下邊界,使得一個表的所有資料僅存在於單個分區上。對於所有的待遷移表都執行shardCollection操作。
sh.shardCollection("<dbName>.test", { _id: "hashed" }) sh.shardCollection("<dbName>.test1", { _id: "hashed" })通過
sh.status()命令來確認相關規則已生效。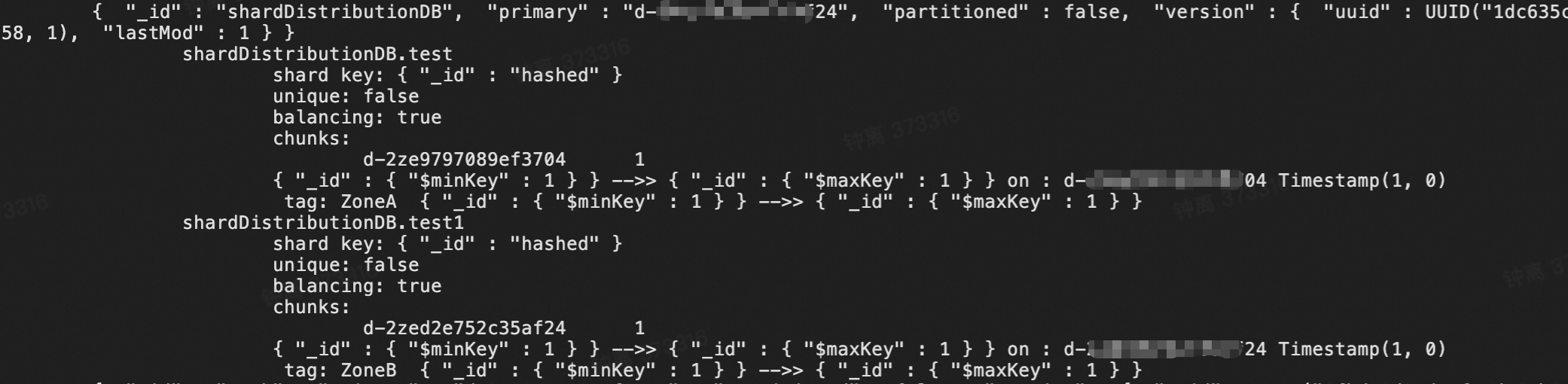
將資料從複本集執行個體遷移到分區叢集執行個體中。
說明由於已經在目標執行個體上進行了分區操作,所有庫表資訊已存在,因此需要配置目標已存在表的處理模式為忽略報錯並繼續執行。
資料校正一致後將業務切換到訪問新的分區叢集執行個體。
如果需要為執行個體增加分區,需要執行上述操作中的步驟3,為所有新增的分區指定分區。
如果資料庫後續會持續新增集合,需要執行上述操作中的步驟4和步驟5。如果不執行這兩個步驟,庫表將只會存在主分區上,導致主分區上庫表數越來越多,然後再次遇到執行個體卡頓或異常的問題。
風險提示
不建議您直接通過dropDatabase命令刪除擁有大量集合的庫。
執行dropDatabase命令後,WT引擎會非同步進行清理操作,逐個清理所有待刪除表相關的中繼資料和物理檔案。該操作可能會影響從節點的主從同步,導致複寫延遲不斷上漲;進而引起flowControl機制介入或者影響您所有{writeConcern:majority}的寫入操作。
您可以考慮採取以下方式來規避:
設定合理的間隔分批刪除庫中的集合,並在所有集合刪除完畢後最終執行
dropDatabase命令。使用DTS或者其他遷移工具將需保留的庫表遷移到新執行個體中,並在遷移割接完成後刪除舊執行個體。
無論如何,您都應該針對執行個體設定合理的主從延遲警示項。如果您的執行個體遇到了此問題,可以提交工單聯絡支援人員協助解決。
總結
盡量將一個複本集內的庫表總數控制在1萬以內。如果單個表裡的索引數量過多(>15),則該數值應適當下調。
如果因業務特性(例如多租戶系統按表隔離)需要存在很多的庫表數,請考慮拆分商務邏輯並使用分區叢集執行個體。
如果您的資料庫已被庫表數多的問題困擾,想要降低資料庫中的庫表數但不知道如何修改商務邏輯設計,您可以提交工單聯絡支援人員協助解決。