使用PyODPS DataFrame編寫資料應用時,代碼在不同位置執行可能導致問題。本文為您介紹如何確定代碼的執行環境,並提供解決方案。
概述
PyODPS是一個Python包而非Python Implementation,其運行環境均為標準的Python,因而並不會出現與正常Python解譯器不一致的行為。現通過以下程式碼範例分析其運行原理和運行環境。
程式碼範例
from odps import ODPS, options import numpy as np o = ODPS(...) df = o.get_table('pyodps_iris').to_df() coeffs = [0.1, 0.2, 0.4] def handle(v): import numpy as np return float(np.cosh(v)) * sum(coeffs) options.df.supersede_libraries = True val = df.sepal_length.map(handle).sum().execute(libraries=['numpy.zip', 'other.zip']) print(np.sinh(val))代碼執行系統
下圖展示了代碼執行時涉及的系統。代碼在MaxCompute外部執行。為了方便表述,下文統稱為本地。
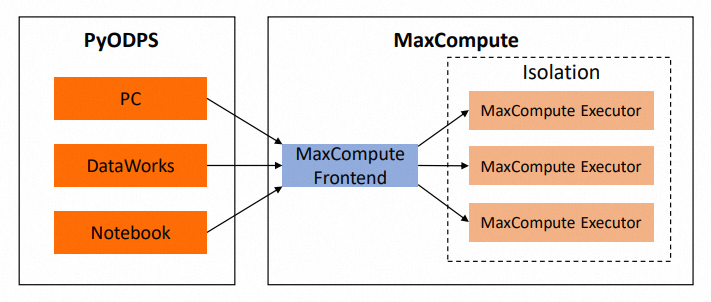
程式碼分析
引用第三方包
在本地執行的程式碼封裝括handle函數之外的部分(注意handle傳入map時僅傳入了函數本身而並未執行),行為與普通Python code的執行行為類似,匯入第三方包時引用的是本地的包。上述代碼中,
libraries=['numpy.zip', 'other.zip']中引用的other.zip並沒有在本地安裝,所以代碼中有諸如import other的語句,會導致執行報錯。即便other.zip已被上傳至MaxCompute資源也是如此,因為本地不存在other.zip包。理論上,本地代碼如果不涉及PyODPS包,則與PyODPS無關,執行報錯時您需要自行排查。handle函數
handle函數傳入map方法時,如果使用的後端是MaxCompute後端,會經歷以下幾個階段:
會先被cloudpickle模組提取閉包和位元組碼。
PyODPS DataFrame使用閉包和位元組碼產生一個Python UDF,提交至MaxCompute。
作業以SQL的形式在MaxCompute執行時,會調用已產生的Python UDF,其中的位元組碼和閉包內容會被unpickle(還原序列化),然後在MaxCompute Executor執行。
總結
handle函數體中的代碼都不會在本地執行,而是在MaxCompute Executor中執行。
handle函數體中無法引用本地安裝的包,只有在MaxCompute Executor中存在的包才有效。
上傳的第三方包必須相容MaxCompute Executor的Python版本(目前為Python 2.7,UCS2)。
handle函數體中修改引用的外部變數(例如上述代碼中的
coeffs)不會導致本地的coeffs值被修改。在handle函數體中引用在handle外部import的包可能會導致報錯。因為在不同環境中,包的結構可能不同,而cloudpickle會將當地套件的引用代入MaxCompute Executor,導致報錯,因此建議在handle函數體中進行import。
由於使用cloudpickle,如果在handle函數體中調用了其他檔案的代碼,該檔案所在的包必須存在於MaxCompute Executor中。如果您不想使用第三方包的形式解決該問題,請將所有引用的個人代碼放在同一個檔案中。
上述handle函數的解釋對於自訂彙總、apply和map_reduce中調用的自訂方法/Agg類均適用。如果使用的後端是Pandas後端,則所有代碼都會在本地運行,因此本地也需要安裝相關的包。但鑒於Pandas後端調試完畢後通常會轉移到MaxCompute運行,建議在本地安裝包的同時,參照MaxCompute後端的慣例進行開發。
使用第三方包
個人電腦/自有伺服器:在本地使用第三方包時,在相應的Python版本上安裝即可。
Notebook:在本地代碼中使用第三方包,請諮詢平台提供方。
DataWorks:不支援在本地安裝第三方包,但可以在DataWorks環境中進行調用。對於其他檔案中的代碼,可以通過讀取檔案+
exec命令的方式在本地進行使用。詳情請參見在PyODPS節點中調用第三方包。重要DataStudio中的目錄結構並非檔案系統中真實存在的目錄結構,直接import或開啟會導致執行失敗。
在DataWorks中上傳資源後,需要點擊提交確保資源被正確上傳到ODPS。
使用自訂的Numpy版本,上傳正確的wheel包的,並配置
odps.df.supersede_libraries = True,確保您上傳的Numpy包名作為libraries的第一個參數。
引用其他MaxCompute表中的資料
個人電腦/自有伺服器/Notebook/DataWorks:在本地訪問MaxCompute表,如果Endpoint可以串連,使用PyODPS/DataFrame訪問。串連Endpoint時出現問題請諮詢平台提供方。
map/apply/map_reduce/自訂彙總:訪問其他MaxCompute表,MaxCompute Executor中通常不支援訪問Endpoint/Tunnel Endpoint,也沒有PyODPS包可用,因此不能直接使用ODPS入口對象或者PyODPS DataFrame,也不能從自訂函數外部傳入這些對象。如果表的資料量不大,建議將DataFrame作為資源傳入,詳情請參見引用資源。如果資料量較大,建議改寫為表JOIN。