PyODPS可在DataWorks等資料開發平台中作為資料開發節點調用。這些平台提供了PyODPS運行環境和調度執行的能力,無需您手動建立ODPS入口對象。PyODPS支援類似Pandas的快速、靈活和富有表現力的資料結構。您可以通過PyODPS提供的DataFrame API使用Pandas的資料結果處理功能。本文以DataWorks平台為例,協助您快速開始使用PyODPS,並且能夠用於實際專案。
前提條件
已建立DataWorks工作空間,並綁定MaxCompute計算資源。
操作步驟
建立PyODPS節點。
為方便您快速開始,本文中使用DataWorks PyODPS節點進行開發,詳情請參見開發PyODPS 3任務。
說明以PyODPS 3節點作為樣本,PyODPS 3節點底層的Python版本為3.7。
PyODPS節點擷取本地處理的資料量不能超過50 MB,節點運行時佔用的記憶體不能超過1 GB,否則節點任務會被系統中止。因此請避免在PyODPS任務中寫入資料量較大的Python處理代碼。
在DataWorks上編寫代碼並進行調試效率較低,為提升運行效率,建議本地安裝IDEA進行代碼開發。
建立商務程序。
進入資料開發頁面,按右鍵商務程序,選擇建立商務程序。
建立PyODPS節點。
按右鍵建立的商務程序,選擇,輸入節點名稱,單擊提交。
編輯PyODPS節點。
編寫程式碼。
在PyODPS節點的編輯框中輸入測試代碼。以下是一個完整的使用PyODPS介面執行表操作的樣本,更多關於表操作以及SQL操作的方法請參見表和SQL。
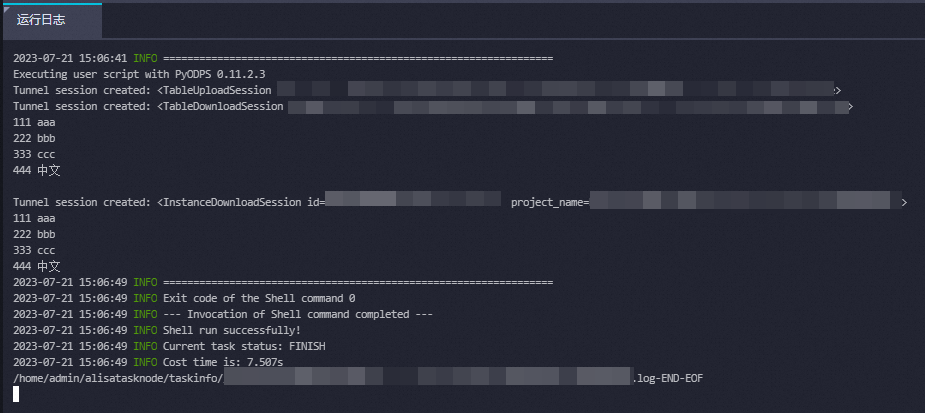
from odps import ODPS #以直接指定欄位名以及欄位類型的方式建立非分區表my_new_table。 #DataWorks的PyODPS節點中預設包含一個全域變數odps或者o,即為ODPS入口。您不需要手動定義ODPS入口,直接使用即可。更多資訊,請參見通過DataWorks使用PyODPS。 table = o.create_table('my_new_table', 'num bigint, id string', if_not_exists=True) #向非分區表my_new_table中插入資料。 records = [[111, 'aaa'], [222, 'bbb'], [333, 'ccc'], [444, '中文']] o.write_table(table, records) #讀取非分區表my_new_table中的資料。 for record in o.read_table(table): print(record[0],record[1]) #以運行SQL的方式讀取表中的資料。 result = o.execute_sql('select * from my_new_table;',hints={'odps.sql.allow.fullscan': 'true'}) #讀取SQL執行結果。 with result.open_reader() as reader: for record in reader: print(record[0],record[1]) #刪除表以清除資源。 table.drop()運行代碼。
完成編輯後,單擊
 表徵圖。運行結束後,您可以在下方的作業記錄中看到運行結果。輸出如下日誌代表執行成功。
表徵圖。運行結束後,您可以在下方的作業記錄中看到運行結果。輸出如下日誌代表執行成功。