本文介紹如何通過Lindorm計算引擎的OLAP或ETL資源群組快速使用SQL語言讀寫資料。
前提條件
使用OLAP資源群組
計算引擎OLAP資源群組提供了相容MySQL的提供者,面向查詢分析情境,具備高並發低延遲查詢響應能力。OLAP資源群組開通後分配常駐計算資源,確保查詢快速響應。
步驟一:建立OLAP資源群組
登入Lindorm管理主控台。在左上方選擇執行個體所屬的地區。在实例列表頁,單擊目標執行個體ID或者目標執行個體所在行操作列的管理。
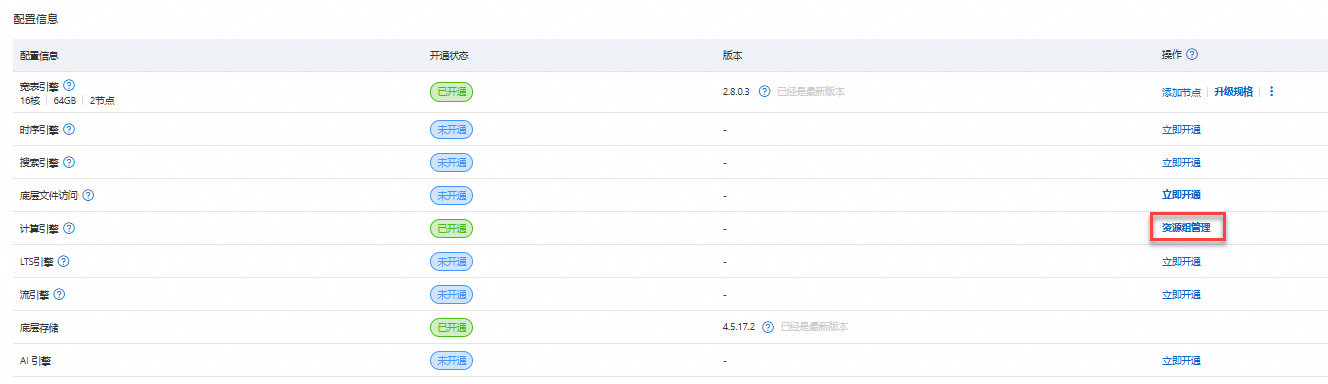
在实例详情頁的配置信息地區,單擊计算引擎操作列的资源组管理。
在资源组详情頁中單擊创建资源组,配置以下內容:
參數
說明
资源组类型
選擇OLAP。
资源组名称
資源群組的名字,僅支援小寫字母和數字,且長度不超過63個字元。例如
cg0。节点规格
選擇節點規格。
作业工作节点数
取值範圍:[4,1024],預設值為
4。單擊確定,建立資源群組。
說明建立過程大約需要20分鐘。
在资源组详情介面,新建立的資源群組状态&描述信息處於运行中後,您可以將懸浮滑鼠在OLAP資源群組名稱之上,擷取OLAP資源群組VPC內網串連地址,例如
jdbc:mysql://ld-bp1dv48fk0yg0****-olap-proxy-ldps.lindorm.aliyuncs.com:9030。配置MySQL用戶端後,通過JDBC串連指定OLAP資源群組的VPC內網地址,並使用Lindorm寬表引擎的使用者名稱和密碼登入,即可通過MySQL協議串連到OLAP資源群組執行SQL查詢。
mysql -hld-bp1dv48fk0yg0****-olap-proxy-ldps.lindorm.aliyuncs.com -P9030 -uroot -p
步驟二:訪問資料
訪問列存資料
列存資料是相容Iceberg生態的列式儲存資料湖。資料存放區在Lindorm執行個體的檔案引擎之中,可以通過OLAP資源群組寫入與查詢資料。
列存資料存放區在名為lindorm_columnar的Catalog(用來標識不同的資料來源)中,通過MySQL協議串連成功後,預設訪問列存資料的Catalog。您也可以執行SET CATALOG lindorm_columnar;顯式切換到列存資料Catalog中。
建立並使用資料庫。
-- 建立資料庫 CREATE DATABASE olapdemo; -- 使用該資料庫 USE olapdemo;建立資料表並寫入資料。
-- 建立表 CREATE TABLE test (id INT, name STRING) ENGINE = iceberg; -- 插入資料 INSERT INTO test VALUES (0, 'Jay'), (1, 'Edison');查詢資料。
樣本1:
SELECT id, name FROM test WHERE id != 0;返回結果:
+------+--------+ | id | name | +------+--------+ | 1 | Edison | +------+--------+樣本2:
SELECT count(distinct name) FROM test;返回結果:
+----------------------+ | count(DISTINCT name) | +----------------------+ | 2 | +----------------------+樣本3:
SELECT * FROM (SELECT id, name FROM test WHERE id != 0) t0 JOIN (SELECT id, name FROM test WHERE id != 2) t1 ON t0.id=t1.id;+------+--------+------+--------+ | id | name | id | name | +------+--------+------+--------+ | 1 | Edison | 1 | Edison | +------+--------+------+--------+
刪除表。
DROP TABLE test;刪除資料庫。
DROP DATABASE olapdemo;
訪問寬表資料
OLAP資源群組支援直接查詢寬表引擎中的資料,可藉助其計算能力高效執行複雜查詢計算。OLAP資源群組不支援建立或寫入寬表引擎資料表,只支援資料的查詢操作。
寬表引擎資料存放區在名為lindorm_table的Catalog中。訪問寬表引擎中的資料,需顯式執行SET CATALOG lindorm_table;切換至該Catalog中。
若您已有可使用的寬表,請直接進入下一步。若您尚未建立,請串連寬表引擎,參考以下語句建立寬表tb。
-- 建立資料庫
CREATE DATABASE test;
--使用該資料庫
USE test;
--建立資料表,並插入兩條資料
CREATE TABLE tb (id varchar, name varchar, address varchar, primary key(id, name)) ;
UPSERT INTO tb (id, name, address) values ('001', 'Jack', 'hz');
UPSERT INTO tb (id, name, address) values ('002', 'Edison', 'bj'); 在串連OLAP資源群組的MySQL命令列工具中,執行以下查詢語句訪問寬表資料。
顯式切換資料來源並使用資料庫。
-- 顯式切換資料來源 SET CATALOG lindorm_table; -- 使用test資料庫 USE test;查詢寬表資料。
樣本1:
SELECT * FROM tb LIMIT 5;返回結果:
+------+--------+---------+ | id | name | address | +------+--------+---------+ | 001 | Jack | hz | | 002 | Edison | bj | +------+--------+---------+樣本2:
SELECT count(*) FROM tb;返回結果:
+----------+ | count(*) | +----------+ | 2 | +----------+
使用ETL資源群組
計算引擎ETL資源群組提供Serverless的Spark SQL查詢與寫入能力,資源按需申請,自動釋放,適合低頻查詢或離線報表查詢情境。
步驟一:開通資源群組
登入Lindorm管理主控台。在左上方選擇執行個體所屬的地區。在实例列表頁,單擊目標執行個體ID或者目標執行個體所在行操作列的管理。
在实例详情頁的配置信息地區,單擊计算引擎操作列的资源组管理。
在资源组详情頁中單擊创建资源组,配置以下內容:
參數
說明
资源组类型
選擇ETL。
资源组名称
資源群組的名字,僅支援小寫字母和數字,且長度不超過63個字元。例如
cg0。单日资源消耗限额
資源群組每日消耗的能力單元CU(Capacity Unit)資源上限,單位為
CU*Hour。預設值為100000。重要超出上限,作業會被強制立即刪除。穩定性要求高的資源群組可以配置為
0,表示無限制。CPU上限(核)
資源群組CPU上限。取值範圍:[100,100000]。
内存上限(GB)
資源群組記憶體上限。取值範圍:[400G,1000000G],無預設值。
授权用户
預設值為
*,代表允許所有使用者訪問資源群組。單擊確定,建立資源群組。
步驟二:環境準備
以下環境均部署於與Lindorm執行個體處於同一VPC網路的ECS執行個體內。
安裝Java環境且JDK為1.8及以上版本。
下載Spark。
解壓Spark安裝包。
使用解壓後的路徑設定SPARK_HOME環境變數。
export SPARK_HOME=/path/to/spark/;填寫設定檔:
$SPARK_HOME/conf/beeline.conf。endpoint:Lindorm計算引擎的JDBC地址。如何擷取,請參見查看串連地址。
user:寬表引擎的使用者名稱。
password:寬表使用者名稱對應的密碼。
shareResource:相同使用者的多個會話之間是否共用計算資源,預設值為
true。compute-group:設定要使用的計算引擎ETL資源群組的名字,不設定則預設為
default。
進入
$SPARK_HOME/bin目錄並運行./beeline命令。您將看到以下資訊:Welcome to Lindorm Distributed Processing System (LDPS) !!! Initializing environment. It might take minutes ... Environemnt prepared. You may visit your jdbc cluster by below url: http://alb-boqak6zfns5gzx****.cn-hangzhou.alb.aliyuncsslb.com/proxy/75ce76086b61470da7046bd4c2b7**** Please note -- you are sharing this JDBC cluster between SQL sessions from the same user. The cluster will be released by auto if idle for 4 hours. You may also kill it manually by visiting above web url and clicking 'kill' in tab of 'Query Engine' lindorm-beeline>在互動會話中輸入SQL語句,執行寫入或查詢操作。
說明通過返回資訊中的連結
http://alb-boqak6zfns5gzx****.cn-hangzhou.alb.aliyuncsslb.com/proxy/75ce76086b61470da7046bd4c2b7****,您可以訪問計算引擎的SparkUI介面。
步驟三:訪問資料
訪問列存資料
列存資料是相容Iceberg生態的列式儲存資料湖,資料存放區在Lindorm執行個體的檔案引擎之中,可以通過Spark SQL來寫入和查詢資料。
列存資料存放區在名為lindorm_columnar的Catalog(用來標識不同的資料來源)中,通過MySQL協議串連成功後,預設訪問列存資料的Catalog。您也可以執行SET CATALOG lindorm_columnar;顯式切換到列存資料Catalog中。
建立並使用資料庫。
-- 建立資料庫 CREATE DATABASE etldemo; -- 使用該資料庫 USE etldemo;建立資料表並寫入資料
-- 建立表 CREATE TABLE test (id INT, name STRING); -- 插入資料 INSERT INTO test VALUES (0, 'Jay'), (1, 'Edison');查詢資料。
樣本1:
SELECT id, name FROM test WHERE id != 0;返回結果:
+------+--------+ | id | name | +------+--------+ | 1 | Edison | +------+--------+樣本2:
SELECT count(distinct name) FROM test;返回結果:
+----------------------+ | count(DISTINCT name) | +----------------------+ | 2 | +----------------------+樣本3:
SELECT * FROM (SELECT id, name FROM test WHERE id != 0) t0 JOIN (SELECT id, name FROM test WHERE id != 2) t1 ON t0.id=t1.id;+------+--------+------+--------+ | id | name | id | name | +------+--------+------+--------+ | 1 | Edison | 1 | Edison | +------+--------+------+--------+
刪除表。
DROP TABLE test;刪除資料庫。
DROP DATABASE etldemo;
訪問寬表資料
ETL資源群組中的Spark SQL串連可以查詢寬表引擎中的資料,可以利用彈性的計算能力,在寬表的資料上完成比較複雜的查詢計算。Spark SQL串連不支援寬表引擎的DDL語句,比如建表、刪表等,可以查詢寬表引擎中的資料。
寬表引擎資料存放區在名為lindorm_table的Catalog中。訪問寬表引擎中的資料,需顯式執行SET CATALOG lindorm_table;切換至該Catalog中。
若您已有可使用的寬表,請直接進入下一步。若您尚未建立,請串連寬表引擎,參考以下語句建立寬表tb。
-- 建立資料庫
CREATE DATABASE test;
--使用該資料庫
USE test;
--建立資料表,並插入兩條資料
CREATE TABLE tb (id varchar, name varchar, address varchar, primary key(id, name)) ;
UPSERT INTO tb (id, name, address) values ('001', 'Jack', 'hz');
UPSERT INTO tb (id, name, address) values ('002', 'Edison', 'bj'); 在lindorm-beeline互動會話中,執行以下查詢語句訪問寬表資料。
顯式切換資料來源並使用資料庫。
-- 顯式切換資料來源 SET CATALOG lindorm_table; -- 使用test資料庫 USE test;查詢寬表資料。
樣本1:
SELECT * FROM tb LIMIT 5;返回結果:
+------+--------+---------+ | id | name | address | +------+--------+---------+ | 001 | Jack | hz | | 002 | Edison | bj | +------+--------+---------+樣本2:
SELECT count(*) FROM tb;返回結果:
+-----------+ | count(1) | +-----------+ | 2 | +-----------+