本文介紹EMR Serverless StarRocks提供的業務洞察內容,並通過樣本闡明其潛在的應用情境。該業務洞察提供了前一天(T+1)的資料,並包括查詢洞察、匯入洞察、資料表洞察、Compaction洞察以及緩衝洞察。
查看業務洞察
進入EMR Serverless StarRocks執行個體列表頁面。
在左側導覽列,選擇。
在頂部功能表列處,根據實際情況選擇地區。
單擊目標執行個體ID。
單擊業務洞察頁簽。
在業務洞察頁面,您可以查看查詢洞察、匯入洞察、資料表洞察、Compaction洞察以及緩衝洞察。
查詢洞察
該頁面展示了查詢耗時、DB Lock、SQL查詢分析和參數化SQL分析部分內容。您可以通過選擇特定的日期、SQL類型和資料庫目錄,來查看TOP SQL指標。
支援以下SQL類型:
DML:用於資料的查詢和變更操作。例如,SELECT、UPDATE、DELETE等語句。
DDL:用於定義和修改資料結構的語句。例如,CREATE、ALTER等。
其他:包括非DML和DDL類的SQL命令。例如,SHOW等輔助命令語句。
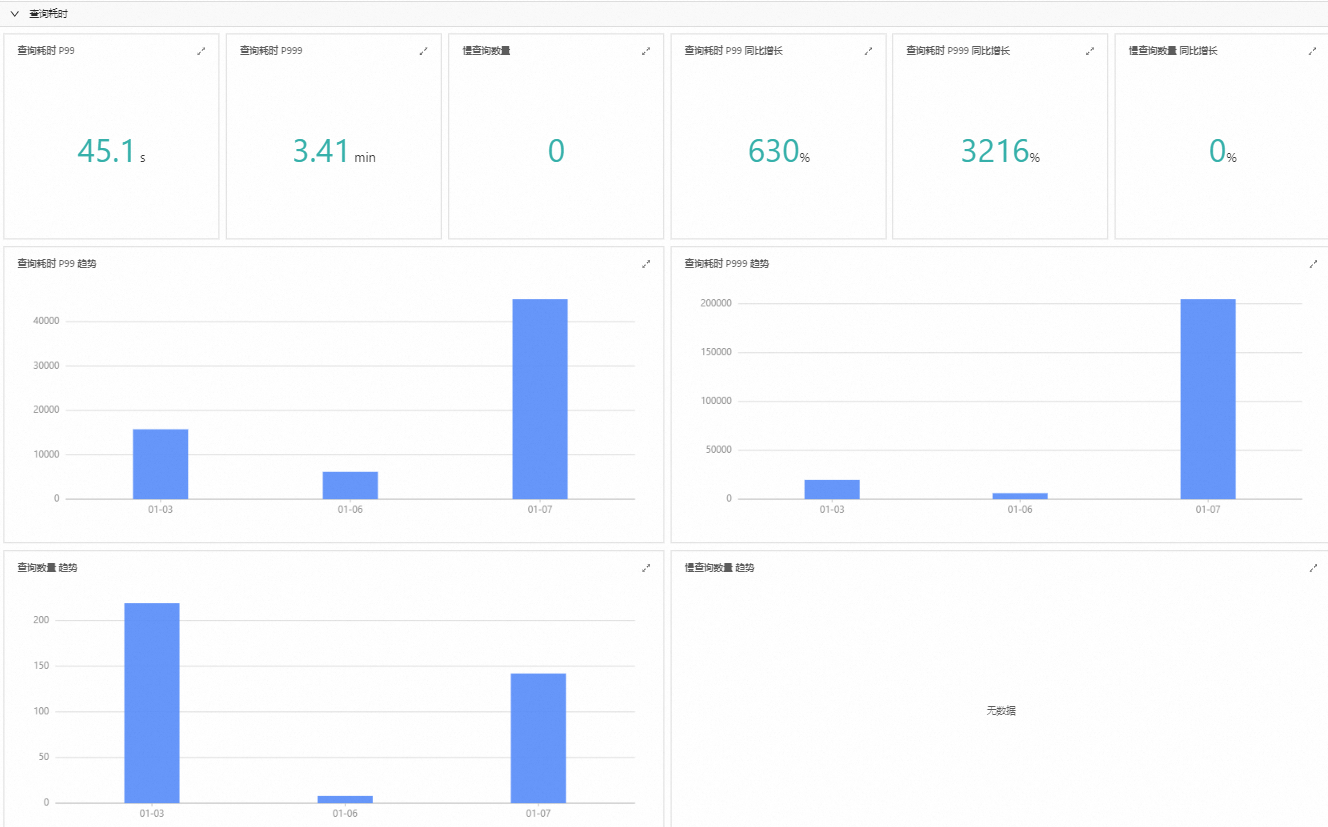
查詢耗時
查詢耗時資料是基於每日審計資料進行統計分析。
以P99查詢耗時(Query Latency P99)為例,這是效能監控中的一個重要指標,用于衡量系統回應時間的分布情況。具體而言,P99表示99%的請求能夠在該時間內得到響應。此指標對於評估服務品質和使用者體驗至關重要。
通過監控P99耗時,可以深入瞭解大多數使用者實際體驗到的服務響應速度。如果發現P99耗時過高,則可能需要增加計算資源或最佳化查詢邏輯,以提升處理效率。
通過展示最近七天的查詢耗時資料,能夠提前識別執行個體潛在的效能風險,從而避免對服務造成重大影響。
DB Lock
DB Lock功能用於監控和分析資料庫訪問過程中出現的鎖競爭狀況,特別是在多個事務嘗試同時訪問或修改同一資料資源時。為了確保資料的一致性和完整性,資料庫會採用鎖機制來控制對特定資料行或表的並發訪問。如果某事務長時間等待擷取鎖,則會影響整體系統的響應速度和服務品質。通過DB Lock資料,可以輔助分析效能問題。
SQL查詢分析
該部分內容是對StarRocks執行的SQL語句的查詢時間、CPU消耗以及記憶體消耗等維度進行排序,從而擷取TOP SQL並展現相應的執行指標。您可以基於這些指標對潛在的效能問題進行最佳化。 例如,可以從慢SQL Top10中查看指定日期執行時間最長的10條SQL語句。然後,根據Profile查詢分析提供的詳細資料來最佳化這些慢執行的SQL語句,Profile分析詳情請參見Query Profile介紹。
報表主要欄位說明如下。
欄位名稱 | 說明 |
查詢ID | StarRocks中每次SQL執行產生的唯一識別碼。每一次SQL執行都會產生新的ID。 |
使用者 | 執行SQL的StarRocks資料庫使用者。 |
查詢時間 | SQL執行過程中消耗的時間。單位:ms。 |
CPU執行時間 | SQL執行過程中消耗的CPU時間,是所有參與執行的CPU核心數的CPU時間匯總。單位:ns。 |
記憶體佔用 | SQL執行過程中消耗的記憶體。單位:bytes。 |
掃描位元組數 | SQL執行過程中訪問的資料量大小。單位:bytes。 |
掃描行數 | SQL執行過程中訪問的資料行數。 |
返回行數 | SQL執行後返回的結果行數。 |
SQL文本 | 被執行的具體SQL語句文本。 |
參數化SQL分析
參數化SQL是指將SQL語句中的常量替換成?參數,同時保留原有文法結構,並刪除注釋、調整空格,產生新的SQL語句。參數化SQL將原始SQL的文法結構映射成相同的參數化SQL語句,有助於對同類型的SQL進行綜合分析。
例如,對於以下兩個SQL語句,當它們經過參數化處理後,它們屬於同一類SQL。
原始SQL
SELECT * FROM orders WHERE customer_id=10 AND quantity>20 SELECT * FROM orders WHERE customer_id=20 AND quantity>100參數化後SQL
SELECT * FROM orders WHERE customer_id=? AND quantity>?
參數化SQL分析從SQL執行頻次、SQL執行總耗時、SQL耗時離散度、SQL CPU資源總消耗、SQL記憶體資源總消耗、SQL執行失敗頻次等維度進行排序,擷取相應的TOP SQL並展現相關指標。
通過參數化SQL分析,您可以:
擷取StarRocks資料庫整體的SQL執行情況。
通過最佳化執行次數較多、執行時間較長以及CPU和記憶體消耗較多的SQL,以擷取更大的最佳化收益。
通過查詢時間變異係數來衡量SQL執行的時間穩定性,可以發現潛在的效能問題。例如,同類SQL執行時間變長可能是由於資料扭曲、資源不足導致的pending等原因。
涉及欄位說明如下。
欄位
說明
參數化SQL ID
參數化SQL的雜湊值,用於標記參數化SQL。
查詢時間變異係數
SQL查詢執行時間標準差與其平均值的比值。通常變異係數越大,代表同類SQL每次執行的時間差別越大。
執行次數
參數化SQL的總執行次數。
參數化SQL文本
參數化後的SQL文本語句。
通過執行失敗次數尋找對應的SQL失敗原因,來發現潛在的問題。
涉及欄位說明如下。
欄位
說明
參數化SQL ID
參數化SQL的雜湊值,用於標記參數化SQL。
執行失敗次數
參數化SQL執行失敗的次數。
執行次數
參數化SQL的執行總次數。
參數化SQL文本
參數化後的SQL文本語句。
匯入洞察
該頁面展示匯入任務的統計資訊,並從多個角度對匯入任務進行分析。
目前系統僅能支援統計和分析存算一體執行個體下的匯入任務情況。
Too many versions情境
匯入頻率過高的資料是基於“too many versions”日誌的統計分析得出的。當Compaction Score超過1000時,系統將會報告錯誤,StarRocks會提示“Too many versions”。為瞭解決此問題,您可以降低匯入的並發量和頻率。
Top分析
Top匯入熱表潛在小檔案分析
針對錶層級的資料匯入情況,系統將會對每個表的所有匯入任務產生的資料檔案進行深入分析,以評估其潛在的小檔案問題嚴重程度,並據此計算出一個影響得分。根據該得分從高至低排序,選出Top 20個受小檔案問題影響最大的表。小檔案問題的存在可能導致查詢效能下降以及Compaction操作效率降低。針對此問題,建議您:
結合表的實際資料規模,科學合理地選擇分區與分桶的數量,以有效避免小檔案問題的發生。
通過適度增大批量處理的規模,可以在提高整體資料處理輸送量的同時,有效減少Object Storage Service中的小檔案數量。
雖然Compaction能夠整合資料檔案、提升系統效能,但其運行過程中會佔用一定的系統資源。因此,在資源較為緊張的情況下,建議適當調整Compaction頻率以平衡資源使用效率。
以下是用於評估小檔案影響得分的具體演算法:
主鍵表:計算公式為
寫入檔案總數÷寫入檔案的平均大小。若平均檔案大小較小,同時檔案數量較多,則表明此類表的小檔案問題潛在影響也越大。非主鍵表:計算公式改為
寫入檔案總數平均÷寫入單個檔案所需時間。當平均寫入檔案耗時較短,同時檔案數量較大時,此類表的小檔案問題潛在影響也越大。
通過上述演算法,我們可以量化表的小檔案問題,從而有針對性地對Top 20的表進行最佳化處理,以改善整體叢集效能。
主要欄位說明如下。
欄位 | 說明 |
表集合 | 記錄匯入任務可能同時寫入的所有相關表資訊,表現為一個包含多個表的集合。 |
表類型 | 用於區分不同類型的表,主要分為主鍵表和非主鍵表兩類。非主鍵表包括明細表、彙總表和更新表。 |
小檔案影響得分 | 通過演算法評估潛在小檔案問題的影響得分,評分值越高代表潛在的小檔案問題越嚴重。 |
更新的資料分桶數 | 統計在匯入任務過程中涉及到的需要更新的Tablet的總量。 |
寫入檔案數 | 寫入的Segment檔案的總數量。 |
平均寫檔案大小 | 總寫入資料大小除以寫入檔案總數,用以表示每個檔案的平均寫入資料量。 |
平均寫檔案耗時 | 檔案寫入總耗時除以檔案總數,反映了每次檔案寫入操作的平均所需時間。 |
Top匯入熱表分析
按表粒度對匯入任務數量進行排序並選取Top 20的表,這些表的匯入任務執行最為頻繁且涉及的資料匯入事務最多。
匯入熱節點分析
可以通過對各節點的統計資料進行匯入,來分析資料的均衡度。例如,您可以從寫入總大小指標分析各個broker的寫入是否均衡。
資料表洞察
該頁面展示資料表的查詢熱度、查詢SQL類型、資料分布均衡度和近期90天未訪問的表等相關的指標,為最佳化資料表提供判斷依據。主要指標如下表所示。
指標 | 說明 |
SQL執行次數 | 是指包含這張表的SQL的總執行次數。通常表的執行次數越多,越需要對錶設計進行精心的最佳化,以改善Starrocks執行個體的使用。 |
關聯的參數化SQL個數 | 這裡指的是這張表關聯了幾個參數化SQL。您可以分析表的查詢SQL類型模式來最佳化表的設計。更進一步的,您可以從不同的查詢類型中識別共性,看是否需要建立物化視圖來加速對這張表中資料的查詢。 |
Tablet資料大小變異係數 | 是指同一個分區內的tablet資料大小變異係數,代表了一個表的資料的tablet分布均衡程度。計算方式為:同一個分區內tablet資料大小的標準差除以平均值。一般來說,變異係數越大,這個分區越有可能存在資料扭曲的情況。 |
緩衝洞察
該頁面展示了存算分離版執行個體緩衝相關指標的統計資訊,並從表維度、參數化SQL維度和單SQL維度對緩衝進行分析,按照天來查看不同維度下的TOP指標。
該功能暫不適用於存算一體版執行個體。
使用說明
提高執行個體的快取命中率有助於提升查詢效能。該頁面根據Query Profile資料對執行個體的緩衝情況進行分析。Query Profile記錄了查詢中涉及的所有運算元的執行資訊,通過Query Profile可以擷取與查詢相關的緩衝指標,從而便於對緩衝使用方式進行深入分析。
在Query Profile中,對錶、視圖或物化視圖的每一次掃描均對應一個CONNECTOR_SCAN運算元。Query Profile提供了該運算元的各項指標,其中一些與緩衝相關的指標如下表所示。
指標 | 含義 | 內表 | 外表 |
快取命中量 | 從緩衝讀取的位元組數。 | CompressedBytesReadLocalDisk | dataCacheReadBytes |
緩衝miss量 | 從遠程讀取的位元組數。 | CompressedBytesReadRemote | FSIOBytesRead |
本地IO次數 | 從緩衝讀取的IO次數。 | IOCountLocalDisk | dataCacheReadCounter |
遠程IO次數 | 從遠程讀取的IO次數。 | IOCountRemote | FSIOCounter |
本地IO時間 | 從緩衝讀取耗時。 | IOTimeLocalDisk | dataCacheReadTimer |
遠程IO時間 | 從遠程讀取耗時。 | IOTimeRemote | FSIOTime |
根據上述指標,可以進一步計算出以下三個緩衝相關的指標:
快取命中率 = 快取命中量 /(快取命中量 + 緩衝miss量)
本地IO時間佔比 = 本地IO時間 /(本地IO時間 + 遠程IO時間)
本地IO次數佔比 = 本地IO次數 /(本地IO次數 + 遠程IO次數)
從一天的Query Profile記錄中提取出所有SQL的CONNECTOR_SCAN運算元的上述指標,並按照以下三個維度進行分組,計算出每個分組的平均快取命中量、快取命中率等指標,有助於從不同維度對緩衝情況進行分析。各個維度使用情境樣本如下表所示。
維度 | 應用情境 |
表維度 | 找出訪問頻率高、快取命中率低、緩衝miss量高的表。通過緩衝預熱等手段最佳化其緩衝情況,有助於提升查詢效能。 |
參數化SQL維度 | 分析包含CONNECTOR_SCAN運算元數量最多或平均查詢時間最長的參數化SQL的快取命中情況,可以優先對這些SQL進行最佳化,或者針對其訪問的表實施緩衝預熱,從而有效提升查詢效能。 |
單SQL維度 | 針對查詢時間較長、快取命中率低或緩衝miss數量較高的SQL進行深入分析,通過最佳化SQL語句或對其訪問的表進行緩衝預熱,有助於提高查詢效能。 |
表維度
該部分內容展示資料表的訪問次數、快取命中率、快取命中量、緩衝miss量等指標,並根據這些指標對錶進行排序。通過從表的維度進行分析,可以擷取與緩衝相關的以下資訊:
查看訪問次數排名靠前的表的快取命中情況。例如,下圖中訪問次數最高(6411次)的表,其快取命中率僅為24.2%。提高該表的快取命中率將有助於提升查詢效率。可以通過對這類訪問頻率高且快取命中率低的表進行緩衝預熱,以最佳化緩衝的使用。
查看快取命中率低或緩衝miss量高的表,採用緩衝預熱的方法以改善其緩衝狀況,從而提升相應查詢的效能。
在實際使用過程中,通常需要綜合多個指標來判斷是否對該表進行緩衝預熱。例如,如果一張表同時出現在“訪問頻率 Top20”、“快取命中率低 Top20”和“平均緩衝miss量 Top20”這三個表中,說明該表的訪問頻率較高、查詢資料量大且快取命中率低,因此應優先對其進行預熱處理。
涉及主要欄位說明如下表所示。
欄位 | 說明 |
訪問次數 | 掃描該表的CONNECTOR_SCAN運算元的數量。 |
快取命中率 | 通過 |
本地IO時間佔比 | 通過 |
本地IO次數佔比 | 通過 |
平均快取命中量 | 通過 |
平均緩衝miss量 | 通過 |
參數化SQL維度
參數化SQL是指將SQL語句中的常量替換成?參數,同時保留原有文法結構,並刪除注釋、調整空格,產生新的SQL語句。參數化SQL將原始SQL的文法結構映射成相同的參數化SQL語句,有助於對同類型的SQL進行綜合分析。
參數化SQL分析對掃描次數、快取命中率、快取命中量、緩衝miss量等指標進行排序,以擷取相應的TOP參數化SQL並展示相關指標。
通過參數化SQL分析,您可以擷取以下資訊:
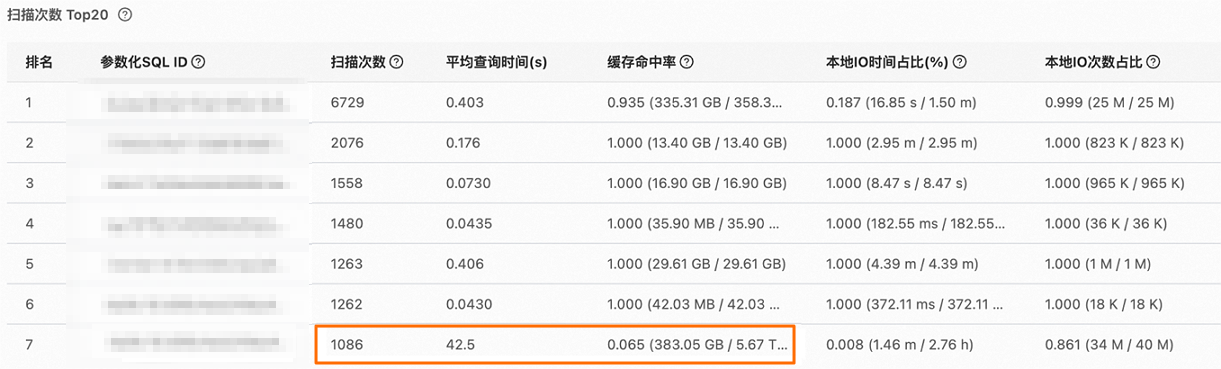
查看掃描次數排名靠前的參數化SQL的快取命中情況。例如,下圖中排名第七的參數化SQL掃描次數為1086,且平均查詢時間較長(42.5秒),然而其快取命中率僅為6.5%。通過對這些SQL進行最佳化,或對其掃描的表進行預熱,可以更有效地利用緩衝,從而提升查詢效能。
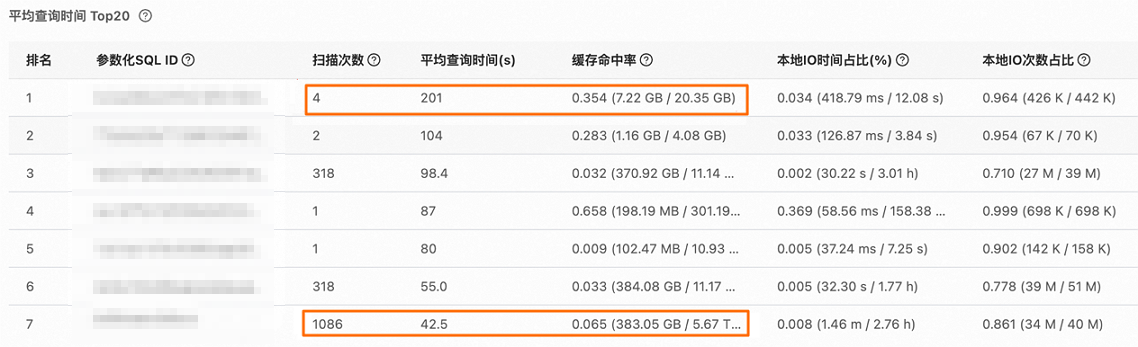
查看平均查詢時間排名靠前的參數化SQL的快取命中情況。例如,下圖所示,排名第一的參數化SQL平均查詢時間為201秒,但其掃描次數僅為4次,說明該參數化SQL對應冷查詢,是否需要進行最佳化可依據實際業務需求進行判斷;而排名第七的參數化SQL平均查詢時間為42.5秒,掃描次數卻達到了1086次,相比之下,該參數化SQL更值得關注。
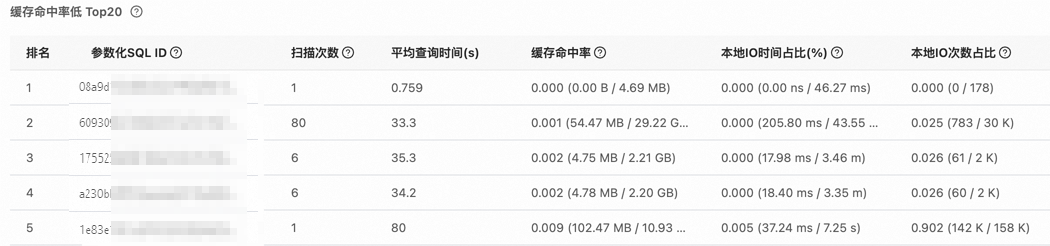
查看快取命中率較低、緩衝miss量較高的參數化SQL,並結合這些SQL的掃描次數、平均查詢時間等指標決定是否對其進行最佳化。
涉及主要欄位說明如下表所示。
欄位 | 說明 |
參數化SQL ID | 參數化SQL的雜湊值,用於標記參數化SQL。 |
掃描次數 | 一條參數化SQL對應的所有SQL的CONNECTOR_SCAN運算元數量之和。 |
快取命中率 | 通過 |
本地IO時間佔比 | 通過 |
本地IO次數佔比 | 通過 |
平均快取命中量 | 通過 |
平均緩衝miss量 | 通過 |
參數化SQL語句 | 經過參數化處理的SQL文本語句。 |
SQL維度
該部分內容是對StarRocks執行的SQL語句按照查詢時間、快取命中率、快取命中量、緩衝miss量等指標進行排序,從而擷取TOP SQL並展現相應的指標。
您可以基於這些指標對緩衝進行深入分析,例如查看執行時間較長、快取命中率較低以及緩衝未命中數量較高的SQL語句。通過對這些SQL語句進行最佳化或對其訪問的表實施緩衝預熱等方法,可以有效改善快取命中情況。
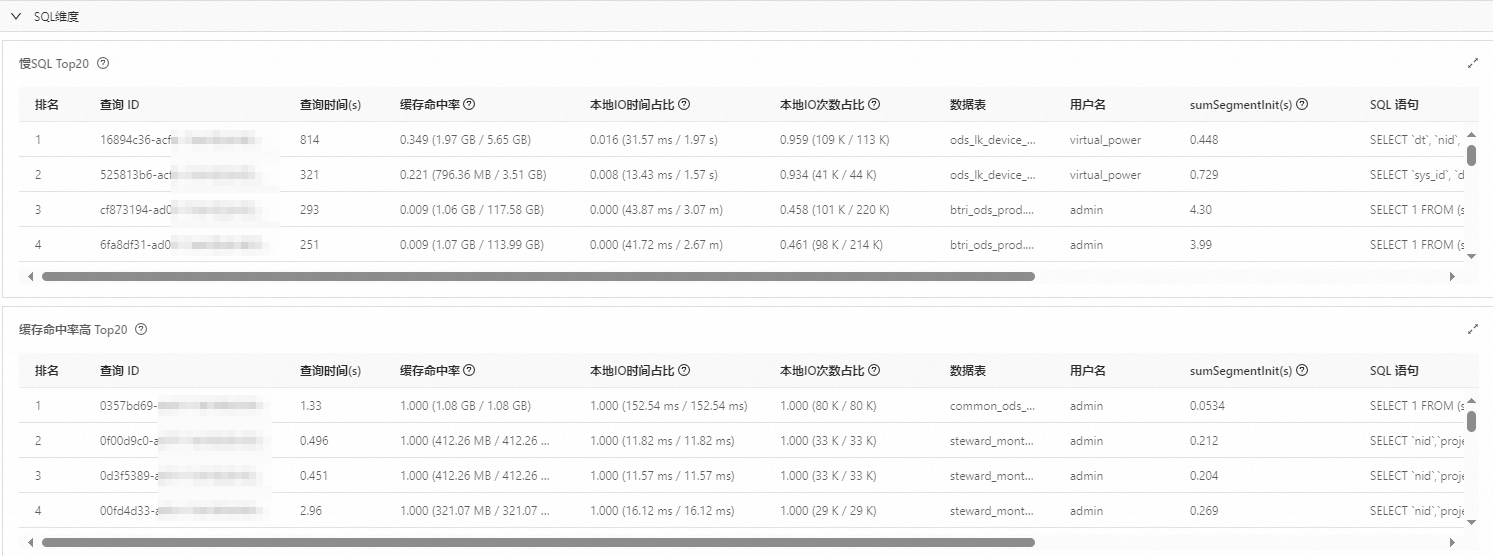
涉及主要欄位說明如下表所示。
欄位 | 說明 |
查詢ID | StarRocks中每次SQL執行產生的唯一識別碼。每次SQL執行均會產生一個新的ID。 |
查詢時間 | SQL執行過程中所消耗的時間,單位為秒(s)。 |
快取命中率 | 通過 |
本地IO時間佔比 | 通過 |
本地IO次數佔比 | 通過 |
資料表 | SQL語句查詢所有表、視圖及物化視圖。 |
使用者名稱 | 執行SQL的StarRocks資料庫使用者。 |
sumSegmentInit | SQL查詢中所有CONNECTOR_SCAN運算元的Segment初始化時間之和。 |
SQL語句 | 具體執行SQL語句文本。 |