Serverless StarRocks基於可視化的Query Profile提供了診斷建議功能,您可以在查看Query Profile的同時,根據Query Profile診斷建議分析SQL效能問題、最佳化SQL效能。
前提條件
已啟用Query Profile功能,詳情請參見啟用Query Profile。
使用Query Profile診斷建議
查看SQL語句診斷建議
在執行詳情頁面,如果存在SQL語句層面的診斷建議,則會在右側執行概覽面板中展現相關內容。SQL語句層面診斷建議說明,請查看SQL語句診斷建議。
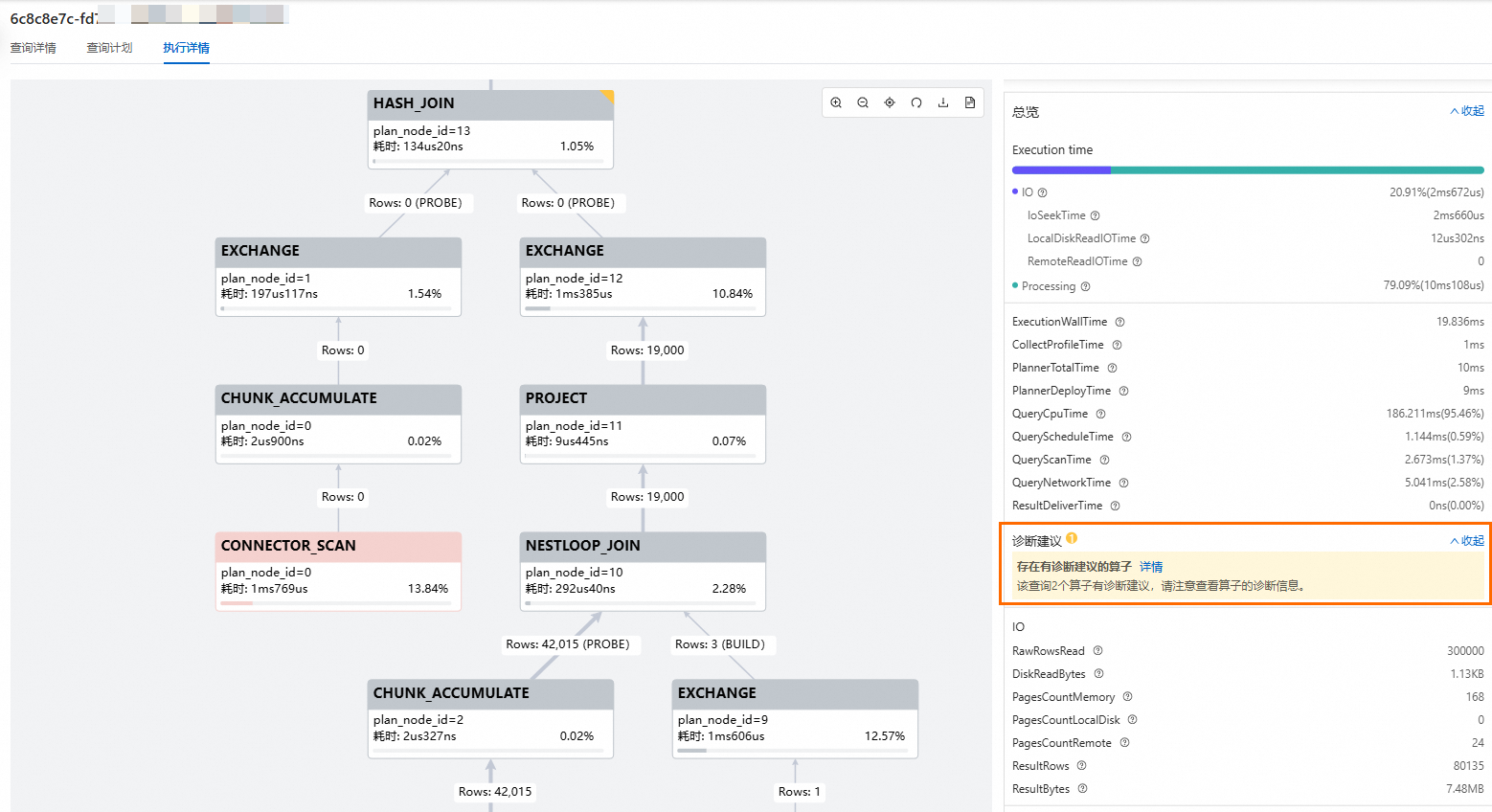
查看SQL運算元診斷建議
在執行詳情頁面,選中右上方有黃色標記的運算元節點,會在右側面板中展現出關於該運算元的診斷建議。SQL運算元診斷建議說明,請查看SQL運算元診斷建議。
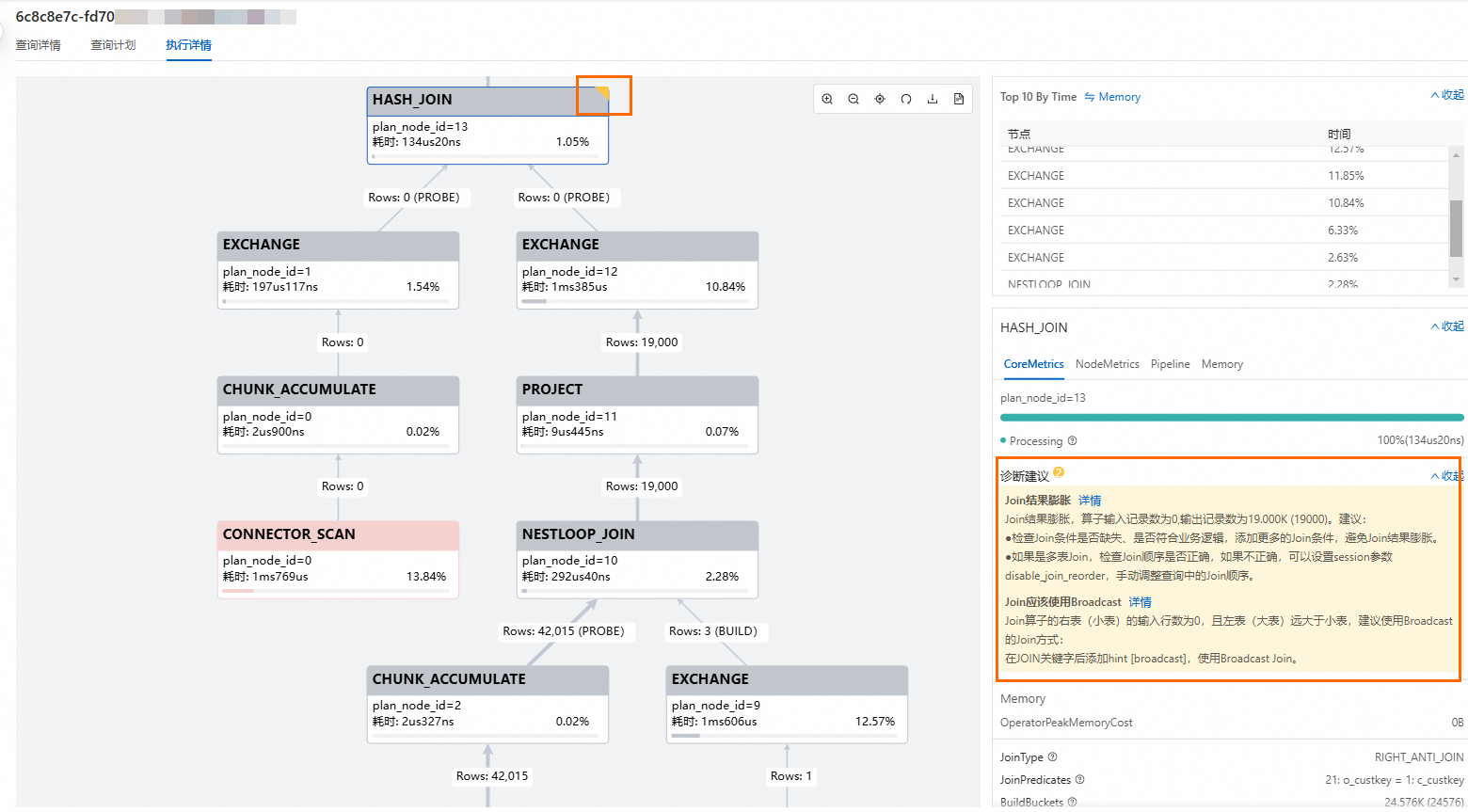
SQL語句診斷建議
Serverless StarRocks在分析Query Profile指標時,會自頂向下逐層分析各個層級的指標。在執行概覽頁面,除運算元層面的指標外,系統匯總其他指標的分析結果,作為SQL語句整體的診斷建議,為SQL效能調優提供直觀指導。
SQL語句層面的診斷建議包含以下內容:
Query Profile Summary部分的指標是否正常。例如,CollectProfileTime指標是否過大。
Query Profile Planner部分的指標是否正常。例如,CoordDeliverExec指標是否正常。
Fragment的指標是否正常。例如,是否存在Fragment各個執行個體執行時間傾斜的情況。
整合運算元層面指標分析結果,匯總提示本次診斷分析的各個運算元診斷建議資料。
SQL運算元診斷建議
Serverless StarRocks基於Wall Time、執行CPU成本等指標相關模型選擇需要診斷的運算元,根據運算元類別解讀Query Profile指標,並給出運算元的診斷建議。通常Wall Time佔整體SQL語句執行時間比重越大的運算元最佳化收益越大。但是,基於執行計畫樹整體的上下遊運算元的聯動關係,即使對執行時間佔比小的運算元進行調整,也可能會觸發計劃樹結構的最佳化重組,從而間接提升SQL語句的執行效能。
Query Profile運算元診斷建議,分為通用運算元的診斷建議和特定運算元的診斷建議。本文列舉一些常見的診斷建議,更多的診斷建議在實際使用Query Profile診斷功能時,會輸出相應的診斷結果概要說明、建議以及詳細診斷原因說明。
通用運算元診斷建議
通用運算元診斷建議是指該診斷建議適用於所有運算元。
運算元執行時間佔比過高
StarRocks是個MPP執行引擎,一個運算元通常會在多個節點以及同一個節點多個執行個體並發執行。當某個運算元多個執行個體的最大執行時間占整個SQL執行時間的比例超過設定的閾值,且診斷引擎基於已有資料無法更進一步的診斷執行時間佔比過高的原因時,系統會給出“運算元執行時間佔比過高”的診斷建議。請關注並最佳化執行時間佔比過高的運算元。
Scan運算元診斷建議
診斷建議 | 問題描述 | 建議措施 |
資料扭曲 | StarRocks資料在各個儲存節點分布不均,使得某些節點在讀取資料時需要掃描更多的資料,導致查詢延遲。 | 建議檢查並最佳化分桶鍵設定,確保資料更均勻分布。 |
IO傾斜 | Scan運算元多個執行個體在讀取資料時,部分執行個體花費的時間顯著大於其它執行個體時間。 | 建議從以下方面進行排查:
|
資料掃描未有效過濾 | 基於掃描未經處理資料量以及最終查詢語句輸出資料量、結合Query Profile執行樹資訊進行判斷。當Scan運算元本身掃描資料量較大,同時輸出給下遊運算元的資料量未顯著過濾的情況下,認為資料掃描未有效過濾。 | StarRocks提供索引、謂詞下推、Join Runtime Filter等多種方式過濾Scan運算元的資料量,可以通過多種方式來提高Scan運算元的掃描過濾效率。建議從以下方面進行排查:
|
Join運算元診斷建議
診斷建議 | 問題描述 | 建議措施 |
Join結果膨脹 | 正常情況下,Join運算元的輸出結果行數一般小於等於輸入行數。如果輸出結果顯著大於輸入結果,則視為Join結果膨脹。此種情況通常是缺少Join條件造成Cross Join,或者Join條件錯誤導致Join的兩張表資料出現1:N的情況。還有一些情況是缺少統計資訊、或者資料變更後統計資訊到期,導致最佳化器選擇了錯誤的計劃。 | 建議從以下方面進行排查:
|
Join build表選擇不合理 | 在Join運算元中,Build階段系統通常會在記憶體中建立雜湊表,Build表資料量過大會消耗更多的記憶體資源。此種情況,通常是因為執行最佳化器沒有正確的選擇Build表所致。 | 建議從以下方面進行排查:
|
Join不應該使用Broadcast | 當小表與大表Join時,如果小表遠小於大表,Broadcast Join可以將小表廣播到大表所在節點,避免大表的資料重分布,從而有效降低了網路傳輸的開銷。但某些情況下,由於統計資訊錯誤等原因,最佳化器錯誤地估計了表的大小,導致較大的表也使用了Broadcast Join,增加網路和計算的成本。 | 建議在JOIN關鍵字後添加 |
Aggregate運算元診斷建議
診斷建議 | 問題描述 | 建議措施 |
Aggregate本地彙總度低 | 在執行彙總操作時,各個計算節點通常會先在本地彙總擷取較小彙總結果後再分發到其它節點,以減少網路資料轉送。但某些情況下,本地彙總時未能有效縮減資料量,不僅不能減少網路資料轉送,反而會消耗大量的計算資源。 | 如果Aggregate整體(包括非本地彙總部分)執行時間較長,則建議通過修改Session參數 |
相關文檔
如果您想瞭解Query Profile的結構和指標,詳情請參見Query Profile介紹。