Apache Flume是一個分布式、可靠和高可用的系統,可以從大量不同的資料來源有效地收集、彙總和移動日誌資料,從而集中式的儲存資料。
使用情境
Flume使用最多的情境是日誌收集,也可以通過定製Source來傳輸其他不同類型的資料。
Flume最終會將資料落地到Realtime Compute平台(例如Flink、Spark Streaming和Storm)、離線計算平台上(例如MR、Hive和Presto),也可僅落地到資料存放區系統中(例如HDFS、OSS、Kafka和Elasticsearch),為後續分析資料和清洗資料做準備。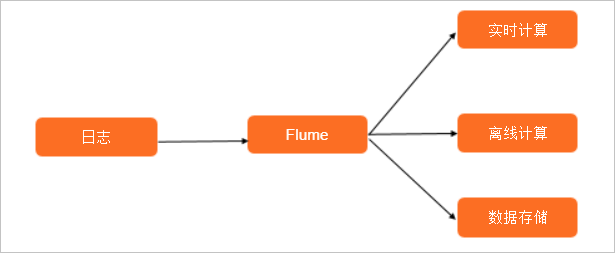
架構
Flume Agent是一個Flume的執行個體,本質是一個JVM進程,控制Event資料流從生產者傳輸到消費者。一個Flume Agent由Source、Channel、Sink組成。其中,Source和Channel可以是一對多的關係,Channel和Sink也可以是一對多的關係。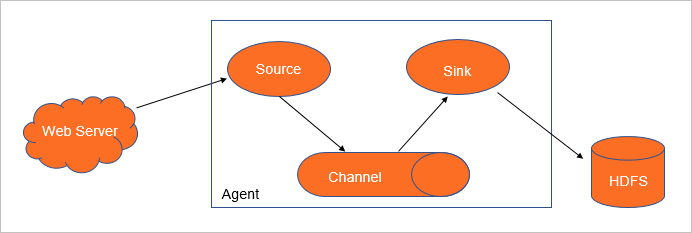
基本概念
名稱 | 描述 |
Event | 是資料流通過Flume Agent的基本單位。Event由一個可選的Header字典和一個裝載資料的位元組數組組成。 樣本如下。 |
Source | 是資料來源收集器,從外部資料源收集資料,並批量發送到一個或多個Channel中。 常見Source如下:
|
Channel | 是Source和Sink之間的緩衝隊列。 常見Channel如下:
|
Sink | 從Channel中擷取Event,並將以事務的形式Commit到外部儲存中。一旦事務Commit成功,該Event會從Channel中移除。 常見Sink如下:
|