使用ECS執行個體時,可能會遇到鏡像相關問題,如執行個體啟動慢、系統負載高、編譯核心等。本文介紹這些問題及解決方案。
Windows鏡像問題
執行個體的作業系統為Windows Server,現在提示Windows副本不是正版怎麼辦?
需要啟用Windows。具體操作,請參見如何使用KMS網域名稱啟用VPC網路中的Windows執行個體。
頻繁調用Windows系統API:timeBeginPeriod導致系統時間異常,如何解決?
在Windows Server 2008上頻繁調用系統API:timeBeginPeriod,導致Windows系統時間變慢或變快。您可以參考如下操作進行解決:
說明可能會造成系統時間精度變化的系統函數,請參見微軟官方文檔。
遠程登入ECS執行個體。
具體操作,請參見使用Workbench工具以RDP協議登入Windows執行個體。
下載工具。
解壓CheckTimeBeginPeriod.zip。
解壓bin.zip並進入bin目錄,然後雙擊.exe檔案。
64位作業系統,雙擊InjectDllx64.exe。
32位作業系統,雙擊InjectDllx86.exe。
列印的進程就是調用timeBeginPeriod的進程。
根據業務實際情況,停止或更新調用timeBeginPeriod的程式。
如果問題仍未解決,您可以直接提交工單尋求支援人員。
Windows雲端服務器使用IE瀏覽器開啟網站提示“增強安全配置正在阻止來自下列網站內容”如何處理?
在Windows作業系統的Elastic Compute Service或者Simple Application Server中,使用IE瀏覽器開啟網站時,提示“增強安全配置正在阻止來自下列網站內容”報錯,解決方案請參見Windows雲端服務器使用IE瀏覽器開啟網站提示“增強安全配置正在阻止來自下列網站內容”如何處理?。
更換Windows執行個體的系統硬碟或者重新初始化系統硬碟,為什麼userdata不會自動執行?
問題原因
Windows系統的ECS執行個體正常啟動後,會在
C:\ProgramData\aliyun\vminit\INSTANCE_執行個體ID}\METASERVER路徑下建立快取檔案,該檔案用於標記執行個體是否已經初始化。如果您通過該ECS執行個體建立了自訂鏡像,並用這個自訂鏡像重新初始化系統硬碟或更換系統硬碟,在C:\ProgramData\aliyun\vminit\INSTANCE_ID\METASERVER路徑下會找到與當前重設執行個體ID一致的快取檔案。由於Vminit組件會根據快取檔案的存在與否來判斷ECS執行個體是否是初次啟動。如果找到與當前重設執行個體ID一致的快取檔案,Vminit組件會判斷ECS執行個體不是初次啟動,將不會自動執行userdata指令碼。說明Vminit在建立Windows執行個體時會自動安裝,為Windows執行個體在啟動階段提供了初始化配置的能力,類似於Linux系統的cloud-init。關於Vminit組件的更多資訊,請參見初始化工具介紹。
解決方案
建議您在通過該ECS執行個體建立自訂鏡像前,檢查並刪除
C:\ProgramData\aliyun\vminit\INSTANCE_{執行個體ID}\METASERVER路徑下的快取檔案。
CentOS/Red Hat鏡像問題
如何處理CentOS DNS解析逾時?
問題原因
因CentOS 6和CentOS 7的DNS解析機制變動,導致2017年02月22日以前建立的ECS執行個體或使用2017年02月22日以前的自訂鏡像建立的CentOS 6和CentOS 7執行個體可能出現DNS解析逾時的情況。
解決方案
請按下列步驟操作修複此問題:
下載指令碼fix_dns.sh。
將下載的指令碼放至CentOS系統的/tmp目錄下。
運行bash /tmp/fix_dns.sh命令,執行指令碼。
指令碼的作用和邏輯說明如下:
判斷執行個體系統是否為CentOS。
如果執行個體為非CentOS系統(如Ubuntu和Debian):指令碼停止工作。
如果執行個體為CentOS系統:指令碼繼續工作。
查詢解析檔案/etc/resolv.conf中
options的配置情況。如果不存在
options配置:預設使用阿里雲
options配置options timeout:2 attempts:3 rotate single-request-reopen。
如果存在
options配置:不存在
single-request-reopen配置,則在options配置中追加該項。存在
single-request-reopen配置,則指令碼停止工作,不更改DNS nameserver的配置。
如何檢查與修複CentOS 7執行個體和Windows執行個體IP地址缺失問題?
問題原因及解決方案,請參見檢查與修複CentOS 7執行個體和Windows執行個體IP地址缺失問題。
CentOS 7.9 ARM系統無法產生dump檔案如何處理?
問題現象
CentOS 7.9 ARM系統宕機後,通過
ls /var/crash查詢dump檔案,沒有產生vmcore檔案。
問題原因
CentOS 7.9 ARM系統帶有
CONFIG_ARM64_USER_VA_BITS_52=y特性的核心,系統中原生內建的makedumpfile軟體版本與核心版本不匹配,因此無法產生dump檔案。解決方案
重要該方案僅適用於已正確開啟kdump服務的系統。如果您沒有開啟kdump服務且按照本文操作修複問題,請在
proc/cmdline檔案中手動設定crashkernel參數。運行以下命令,下載相應的kexec-tools包。
wget http://mirrors.aliyun.com/centos-vault/7.9.2009/os/Source/SPackages/kexec-tools-2.0.15-51.el7.src.rpm運行以下命令,安裝RPM包。
rpm -ivh kexec-tools-2.0.15-51.el7.src.rpm運行以下命令,下載patch補丁檔案。
cd /root/rpmbuild/SOURCES wget https://ecs-image-tools.oss-cn-hangzhou.aliyuncs.com/patch/rhelonly-kexec-tools-2.0.20-makedumpfile-arm64-Add-support-for-ARMv8.2-LVA-52-bi.patch運行以下命令,修改kexec-tools.spec檔案。
開啟kexec-tools.spec檔案。
cd /root/rpmbuild/SPECS/ vi kexec-tools.spec按
i鍵進入編輯模式,並在檔案相應位置加入如下兩行內容。Patch999: rhelonly-kexec-tools-2.0.20-makedumpfile-arm64-Add-support-for-ARMv8.2-LVA-52-bi.patch %patch999 -p1添加位置如下:
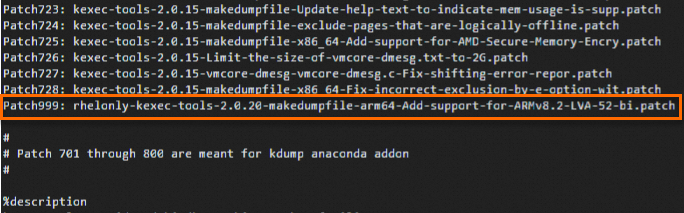
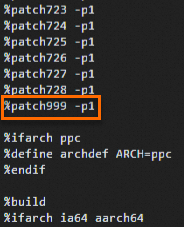
按
Esc鍵退出編輯模式,並輸入:wq儲存退出。
運行以下命令,檢查安裝依賴。
yum-builddep kexec-tools.spec運行以下命令,構建RPM包。
yum -y install rpm-build rpmbuild -ba kexec-tools.spec運行以下命令,安裝修改後的RPM包。
cd /root/rpmbuild/RPMS/aarch64 rpm -ivh kexec-tools-2.0.15-51.el7.aarch64.rpm
如果再次發生宕機,通過
ls -lh /var/crash查詢dump檔案,可以正常產生vmcore檔案,表示問題已解決。
如何將CentOS 7轉換為Red Hat Enterprise Linux(RHEL)7?
CentOS 7將於2024年06月30日停止維護(EOL),阿里雲將會同時停止對該作業系統的支援。為了避免作業系統停止維護帶來的影響,您可以將CentOS 7轉換為RHEL 7。以下是在阿里雲上將CentOS 7轉換成RHEL 7的簡要步驟,您也可以參考Red Hat官方文檔來進行轉換。
重要轉換前,建議您停止重要的應用程式、資料庫服務和儲存資料等服務,並建立快照備份重要資料,以避免誤操作導致資料丟失或異常。
(條件必選)如果您是阿里雲伺服器並且安裝了Server Guard,需要先卸載Server Guard。
具體操作,請參見卸載用戶端。
說明Server Guard是CentOS預設的安全增強工具,而RHEL 7則使用Red Hat提供的安全增強工具。Server Guard與RHEL 7中的工具可能存在不相容性和衝突,因此在轉換過程中需要卸載Server Guard,以確保系統的穩定性和相容性。
運行以下命令,將系統軟體包升級到最新版本。
sudo wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo sudo wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo運行以下命令,更新系統軟體包並重啟系統。
sudo yum -y update sudo reboot運行以下命令,從Red Hat官方網站下載並安裝convert2rhel工具。
sudo curl -o /etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release https://www.redhat.com/security/data/fd431d51.txt sudo curl --create-dirs -o /etc/rhsm/ca/redhat-uep.pem https://ftp.redhat.com/redhat/convert2rhel/redhat-uep.pem sudo curl -o /etc/yum.repos.d/convert2rhel.repo https://ftp.redhat.com/redhat/convert2rhel/7/convert2rhel.repo sudo yum -y install convert2rhel在阿里雲上購買RHEL訂閱,並擷取RHEL 7的repo RPM包地址。
具體操作,請提交工單諮詢。
運行以下命令,安裝RHEL 7的repo源包。
sudo rpm -ivh --replacefiles <repo rpm包地址> sudo sed -i 's/enabled=1/enabled=0/g' /etc/yum.repos.d/rh-cloud.repo其中,
<repo rpm包地址>需替換為RHEL 7實際的repo rpm包地址,該地址請在購買RHEL訂閱時擷取。運行以下命令,將CentOS 7轉換為RHEL 7。
sudo convert2rhel -y --no-rhsm --enablerepo rhui-rhel-7-server-rhui-rpms --enablerepo rhui-rhel-7-server-rhui-extras-rpms --enablerepo rhui-rhel-7-server-rhui-optional-rpms轉換過程需要花費一定時間,請您耐心等待。類似出現如下回顯資訊時,表示轉換完成。
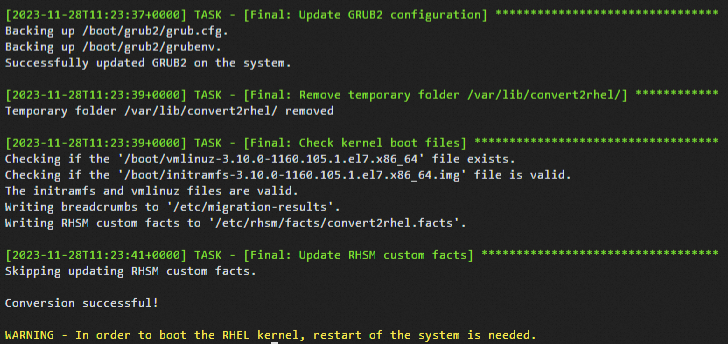
運行以下命令,重啟系統。
轉換結束後會提示重啟系統,重啟系統可以引導新的RHEL核心,然後檢查作業系統是否轉換成功。
sudo reboot說明CentOS 7轉換為RHEL 7之後,如果您有需求將RHEL 7升級為RHEL 8,請參見Red Hat Enterprise Linux(RHEL)7升級為RHEL 8。
如何解決RedHat 8.1/8.2鏡像在ECS Bare Metal Instance執行個體規格類型系列的ECS執行個體下啟動慢的問題?
在ECS Bare Metal Instance執行個體規格類型系列的ECS執行個體中,RedHat 8.1/8.2鏡像相較於RedHat 7鏡像啟動時間長度多1~2分鐘。為解決該問題,您可以在RedHat 8.1/8.2系統的/boot/grub2/grubenv檔案中,將核心啟動參數
console=ttyS0 console=ttyS0,115200n8修改為console=tty0 console=ttyS0,115200n8,然後重啟伺服器使配置生效。
Ubuntu鏡像問題
為什麼Ubuntu某些版本的ECS執行個體中啟動Server Guard進程後系統負載較高?
在某些版本的Ubuntu(例如Ubuntu 18.04)的ECS執行個體中,啟動Server Guard進程(AliYunDun)後,系統平均負載較高。
FreeBSD鏡像問題
FreeBSD系統如何打補丁編譯核心?
阿里雲的FreeBSD公用鏡像已為核心添加了補丁,已滿足系列V及以上的執行個體規格類型系列的啟動需求。具體的執行個體規格類型系列可通過DescribeInstanceTypeFamilies介面的
Generation參數查詢。以下情況可能導致系統無法正常啟動,您可以通過FreeBSD核心源碼打補丁編譯核心的方式,避免或解決系統無法啟動的問題。
使用非阿里雲提供的FreeBSD鏡像及相關自訂鏡像建立ECS執行個體時,系列V及以上執行個體規格類型系列的ECS執行個體可能出現無法正常啟動的情況。
使用FreeBSD公用鏡像建立ECS執行個體,並使用了freebsd-update等更新核心補丁,可能會導致系列V及以上執行個體規格類型系列的ECS執行個體無法正常啟動。
FreeBSD 13及以上不需要打補丁。本樣本以FreeBSD 12.3為例,介紹如何使用FreeBSD核心源碼打補丁編譯核心。
下載並解壓FreeBSD核心源碼。
wget https://mirrors.aliyun.com/freebsd/releases/amd64/12.3-RELEASE/src.txz -O /src.txz cd / tar -zxvf /src.txz下載補丁包。
本樣本中,為virtio驅動打補丁包
0001-virtio.patch。cd /usr/src/sys/dev/virtio/ wget https://ecs-image-tools.oss-cn-hangzhou.aliyuncs.com/0001-virtio.patch patch -p4 < 0001-virtio.patch複製核心檔案,並編譯安裝核心。
make -j<N>表示指定編譯時間的並行數,需要根據您執行編譯的環境配置來決定。例如,1 vCPU環境建議設定-j2,即vCPU核心數與變數N的比值為1:2。cd /usr/src/ cp ./sys/amd64/conf/GENERIC . make -j2 buildworld KERNCONF=GENERIC make -j2 buildkernel KERNCONF=GENERIC make -j2 installkernel KERNCONF=GENERIC編譯完成後,刪除源碼。
rm -rf /usr/src/* rm -rf /usr/src/.*
FreeBSD系統在KVM環境無法找到系統硬碟,如何處理?
問題現象
FreeBSD系統在KVM虛擬化環境上VNC登入時,無法找到系統硬碟,無法進入系統,如下圖所示。

解決方案
在VNC中輸入?,查看相關rootfs的ufsid。

繼續輸入
ufs:/dev/ufsid/5565b5a09045****,按斷行符號即可正常進入作業系統內部。輸入使用者名稱和密碼,登入系統。
運行以下命令,查看
/etc/fstab配置。cat /etc/fstab如下圖所示,說明
/etc/fstab配置是UUID的掛載方式。但是FreeBSD系統並不支援UUID的掛載方式,需要修改為ufsid方式。
將FreeBSD系統的掛載方式修改為ufsid。
運行以下命令,開啟
/etc/fstab。vi /etc/fstab按i鍵進入編輯模式。
修改
UUID=5565b5a09045****為/dev/ufsid/5565b5a09045****。修改完成後按Esc鍵,並輸入
:wq後按下斷行符號鍵,儲存並退出。
運行以下命令,重啟系統使配置生效。
reboot
Fedora鏡像問題
為什麼我無法使用ssh-rsa簽名演算法的SSH金鑰組遠端連線Fedora 33 64位系統的執行個體?
當您使用Fedora 33 64位作業系統的ECS執行個體時,如果登入憑證設定的是ssh-rsa簽名演算法的SSH金鑰組,可能無法順利使用SSH遠端連線執行個體。您可以通過以下任一方式解決該問題:
將ssh-rsa簽名演算法的SSH金鑰組替換為ECDSA簽名演算法等其他簽名演算法的SSH金鑰組。
在系統中運行update-crypto-policies --set LEGACY命令,將加密策略
POLICY切換為LEGACY,即可繼續使用ssh-rsa簽名演算法的SSH金鑰組。
為什麼使用Fedora CoreOS鏡像建立部分執行個體後,CPU資訊只有執行個體規格的一半?
使用Fedora CoreOS鏡像建立部分執行個體(例如,通用型執行個體規格類型系列g5)後,執行lscpu命令查看CPU資訊,
On-line CPU(s) list的總個數只有執行個體實際規格的一半。例如,建立執行個體時選擇的CPU為2核,則On-line CPU(s) list個數只有1個。樣本如下圖所示。 說明
說明On-line CPU(s) list參數值代表CPU編號,圖中樣本表示只有0號CPU可用。這是因為Fedora CoreOS鏡像的核心預設配置了
mitigations=auto,nosmt啟動參數,會自動為有漏洞的系統禁用同步多線程技術SMT(Simultaneous Multi-Threading ),導致可用CPU減半。mitigations=auto,nosmt參數可以通過執行cat /proc/cmdline命令查看。關於SMT的更多資訊,請參見Automatically disable SMT when needed to address vulnerabilities和Policy for disabling SMT。
其他問題
Linux時間和時區說明
如何為已有自訂鏡像安裝NVMe驅動?
如何解決執行個體遷移後的宕機問題?
如何為Linux伺服器安裝GRUB?
如何收集作業系統宕機後的核心轉儲資訊?
如何解決查看/proc/cpuinfo檔案中CPU頻率與執行個體規格說明不一致的問題
使用RSA密鑰無法登入ECS執行個體問題
基於彈性裸金屬執行個體規格的ECS執行個體,系統產生crash dump檔案失敗如何解決?
問題原因及解決方案,請參見部分ECS執行個體產生crash dump檔案失敗如何解決?。
Linux作業系統核心回寫時出現softlockup異常如何解決?
部分低版本的Linux作業系統核心在回寫(writeback)檔案快取時,會出現softlockup異常。具體的解決方案,請參見Linux作業系統核心回寫時出現softlockup異常的解決方案。
在ECS執行個體內刪除cgroup出現softlockup異常如何解決?
具體的解決方案,請參見在ECS執行個體內刪除cgroup出現softlockup異常的解決方案。
公用鏡像內建FTP上傳嗎?
不內建,需要您自己安裝配置。具體操作,請參見搭建FTP網站(Windows)和搭建FTP網站(Linux)。
為什麼ECS預設沒有啟用虛擬記憶體或Swap說明?
Swap分區或虛擬記憶體檔案,是在系統實體記憶體不夠用的時候,由系統記憶體管理程式將那些很長時間沒有操作的記憶體資料,臨時儲存到Swap分區或虛擬記憶體檔案中,以提高可用記憶體額度的一種機制。
但是,如果在記憶體使用量率已經非常高,而同時I/O效能也不是很好的情況下,該機制其實會起到相反的效果。阿里雲ECS雲端硬碟使用了Distributed File System作為雲端服務器的儲存,對每一份資料都進行了強一致的多份拷貝。該機制在保證使用者資料安全的同時,由於3倍增漲的I/O操作,會降低本地磁碟的儲存效能和I/O效能。
綜上,為了避免當系統資源不足時進一步降低ECS雲磁碟的I/O效能,Windows系統執行個體預設沒有啟用虛擬記憶體,Linux系統執行個體預設未配置Swap分區。
如何在公用鏡像中開啟kdump?
公用鏡像中預設未開啟kdump服務。若您需要執行個體在宕機時,產生core檔案,並以此分析宕機原因,請參見以下步驟開啟kdump服務。本步驟以公用鏡像CentOS 7.2為例。實際操作時,請以您的作業系統為準。
設定core檔案組建目錄。
運行vim /etc/kdump.conf開啟kdump設定檔。
設定path為core檔案的組建目錄。本樣本中,在/var/crash目錄下產生core檔案,則path的設定如下。
path /var/crash儲存並關閉/etc/kdump.conf檔案。
開啟kdump服務。
根據作業系統對命令的支援情況,選擇開啟方式。
方法一:依次運行以下命令開啟kdump服務。
systemctl enable kdump.servicesystemctlstartkdump.service方法二:依次運行以下命令開啟kdump服務。
chkconfig kdump onservice kdump start方法三:如果您的伺服器已安裝雲助手,可參考如何解決執行個體遷移後的宕機問題?開啟kdump服務。
Linux作業系統配置IPv6地址後,安裝了NTP服務的伺服器時間無法同步,如何處理?
問題現象
在伺服器上執行
ntpq -p同步時間時,返回逾時,如下圖所示。
解決方案
說明本方法適用於CentOS 7及以下、Ubuntu 20.04及以下、Anolis OS(ANCK\RHCK)、Alibaba Cloud Linux、Debian等系列作業系統。
遠端連線Linux執行個體。
具體操作,請參見使用Workbench工具以SSH協議登入Linux執行個體。
運行以下命令,修改/etc/ntp.conf設定檔。
vi /etc/ntp.conf按i鍵進入編輯模式。
在檔案中添加
restrict -6 ::1內容,如下圖所示。
修改完成後按Esc鍵,並輸入
:wq後按下斷行符號鍵,儲存並退出。運行以下命令,重啟NTP服務。
systemctl restart ntp
為什麼使用自訂鏡像建立的執行個體,熱插拔雲端硬碟/網卡會失敗?
問題現象
熱插拔雲端硬碟指執行個體處於運行中狀態時掛載/卸載雲端硬碟;熱插拔網卡指執行個體處於運行中狀態時綁定/解除綁定彈性網卡。
阿里雲支援熱插拔雲端硬碟和網卡,但熱插拔是否成功需要作業系統核心(Kernel)支援。如果作業系統核心不支援,則會出現以下問題:
掛載雲端硬碟或綁定彈性網卡後,在作業系統內部查看不到對應的裝置。
卸載雲端硬碟或解除綁定彈性網卡失敗。
解決方案
普通雲端服務器和裸金屬伺服器的熱插拔需要核心支援的功能不同,建議核心都支援PCI(Peripheral Component Interconnect)、ACPI(Advanced Configuration and Power Management Interface)熱插拔功能(除CentOS 5等低版本系統外,一般都預設開啟)。您可以通過以下步驟查看核心是否開啟PCI/ACPI熱插拔功能。
遠端連線Linux執行個體。
具體操作,請參見使用Workbench工具以SSH協議登入Linux執行個體。
執行如下命令,查看當前執行個體核心版本。
uname -r返回資訊如下所示,表示當前系統核心版本為
3.10.0-1127.19.1.el7.x86_64。
執行如下命令,查看
/boot目錄下的檔案。ll /boot返回資訊如下所示,
config-3.10.0-1127.19.1.el7.x86_64即為系統核心的設定檔。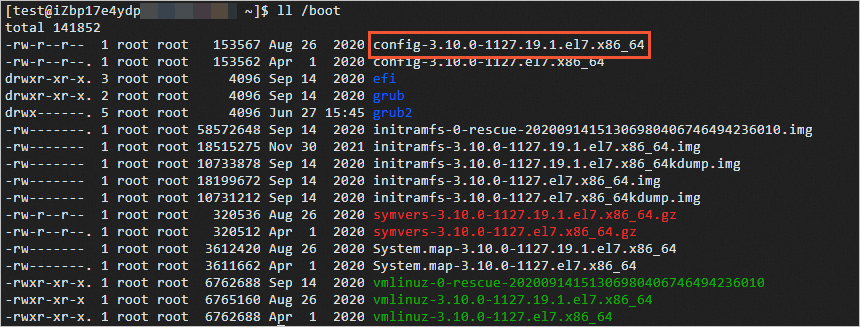
執行如下命令,查看系統核心設定檔。
cat /boot/config-3.10.0-1127.19.1.el7.x86_64當以下配置項都是
y,表示該功能已經編譯進核心,作業系統支援對應的熱插拔。CONFIG_HOTPLUG_PCI_PCIE=y CONFIG_HOTPLUG_PCI=y CONFIG_HOTPLUG_PCI_ACPI=y當某個配置項是
is not set,表示核心未編譯該特性,需要重新編譯核心以支援該特性。當某個配置項是
m,表示編譯成module,例如以下CONFIG_HOTPLUG_PCI_ACPI是編譯成module的,需要載入對應的module。CONFIG_HOTPLUG_PCI_PCIE=y CONFIG_HOTPLUG_PCI=y CONFIG_HOTPLUG_PCI_ACPI=m以CentOS 5.x作業系統2.6的核心為例,
CONFIG_HOTPLUG_PCI_ACPI對應的module為acpiphp.ko,如果需要載入,需要執行modprobe acpiphp命令。如果載入失敗,您可以升級高版本核心或停止執行個體後進行冷插拔。重要不建議隨意自行升級雲端服務器的核心和作業系統版本。如果需要升級核心,請參見避免Linux執行個體升級核心系統無法啟動的方法。
作業系統核心錯誤後可能出現執行個體關機,如何處理?
問題現象
當作業系統內出現非預期核心錯誤(kernel panic)時,載入第二核心(捕獲核心)進行記憶體轉儲產生Kdump日誌。由於與裸金屬執行個體規格存在相容性問題,在第二核心啟動過程中磁碟識別失敗,導致Kdump日誌採集失敗並且第二核心啟動失敗,執行個體處於關機狀態,後續需要在控制台重新啟動執行個體。
更多關於裸金屬執行個體規格的資訊,請參見執行個體規格類型系列。
問題原因
裸金屬執行個體使用作業系統內建的Kdump服務產生dump檔案時可能失敗。
ebm*6代系列裸金屬執行個體,在選用如下鏡像時會出現該問題。
CentOS 8.3及以下CentOS版本
Ubuntu 16/18
Debian 10
Alibaba Cloud Linux 2的
4.19.91-24.al7之前的核心版本(4.19.91-24.al7版本已修複)
ebm*7代系列裸金屬執行個體,在選用Debian 10鏡像時會出現該問題。
解決方案
CentOS等鏡像
建議更換更高版本的作業系統。具體操作,請參見更換作業系統(更換系統硬碟)。
Alibaba Cloud Linux 2鏡像
建議按照以下操作,升級核心版本到
4.19.91-24.al7及以上。遠程登入ECS執行個體。
具體操作,請參見使用Workbench工具以SSH協議登入Linux執行個體。
運行以下命令,查詢核心版本。
uname -r運行以下命令,升級核心版本。
sudo yum update kernel運行以下命令,重啟ECS執行個體,以使新的核心版本生效。
sudo reboot