在本實驗中,您將體驗基於OpenLake House環境下的零售電子商務資料開發與分析情境,通過DataWorks實現面向多引擎協同開發、可視化工作流程編排和資料目錄管理等。同時實踐Python編程及調試,並使用Notebook進行與AI聯動的互動式資料探索與分析。
背景介紹
DataWorks簡介
DataWorks是智能湖倉一體資料開發治理平台,內建阿里巴巴15年巨量資料建設方法論,深度適配阿里雲MaxCompute、E-MapReduce、Hologres、Flink、PAI 等數十種巨量資料和AI計算服務,為資料倉儲、資料湖、OpenLake湖倉一體資料架構提供智能化ETL開發、資料分析與主動式資料資產治理服務,助力“Data+AI”全生命週期的資料管理。自2009年起,DataWorks不斷對阿里巴巴資料體系進行產品化沉澱,服務於政務、金融、零售、互連網、汽車、製造等行業,使數以萬計的客戶信賴並選擇DataWorks進行數字化升級和價值創造。
DataWorks Copilot簡介
DataWorks Copilot是您在DataWorks的智能助手,在DataWorks,您可以自由選擇用DataWorks預設模型、Qwen3-235B-A22B、DeepSeek-R1-0528或Qwen3-Coder大模型來完成相關Copilot產品操作。藉助DeepSeek-R1的深度推理能力,DataWorks Copilot可以協助您通過自然語言互動完成更為複雜的SQL代碼產生、最佳化、測試等操作,顯著提升ETL開發和資料分析效率。
DataWorks Notebook簡介
DataWorks Notebook是智能化互動式資料開發和分析工具,能夠面向多種資料引擎開展SQL或Python分析,即時運行或調試代碼,擷取可視化資料結果。同時,DataWorks Notebook能夠與其他任務節點混合編排為工作流程,提交至調度系統運行,助力複雜業務情境的靈活實現。
注意事項
使用限制
OpenLake只支援資料湖構建(DLF)2.0版本。
資料目錄只支援資料湖構建(DLF)2.0版本。
Qwen3-235B-A22B/DeepSeek- R1模型支援地區:華東1(杭州)、華東2(上海)、華北2(北京)、華北3(張家口)、華南1(深圳)、西南1(成都)。
Qwen3-Coder模型支援地區為華東1(杭州)、華東2(上海)、華北2(北京)、華北3(張家口)、華北6(烏蘭察布)、華南1(深圳)、西南1(成都)。
環境準備
- 說明
請選擇參加資料開發(Data Studio)(新版)公測。
實驗步驟
步驟一:資料目錄管理
湖倉一體的資料目錄管理能力,支援對DLF、MaxCompute、Hologres等進行資料目錄管理及建立。
在Data Studio頁面,單擊頁面左側一級菜單
 ,進入資料目錄功能。在資料目錄左側列表上找到您需要管理的中繼資料類型,單擊添加專案(不同中繼資料類型按鈕存在差異,本文以MaxCompute為例)。
,進入資料目錄功能。在資料目錄左側列表上找到您需要管理的中繼資料類型,單擊添加專案(不同中繼資料類型按鈕存在差異,本文以MaxCompute為例)。您可以按需添加DataWorks工作空間中已建立的資料來源,也可以在MaxCompute-專案頁簽下選擇當前帳號具有相關許可權的MaxCompute專案。

添加專案後,即可在對應中繼資料類型下看到已添加的專案,您可以單擊專案名稱,進入資料目錄詳情頁。
在資料目錄詳情頁選擇Schema後,單擊任意表名可進入該表的詳情頁面查看錶詳情。
資料目錄支援您可視化建表。
展開資料目錄至指定Schema的表層級,單擊右側的
 ,進入建立表頁面。
,進入建立表頁面。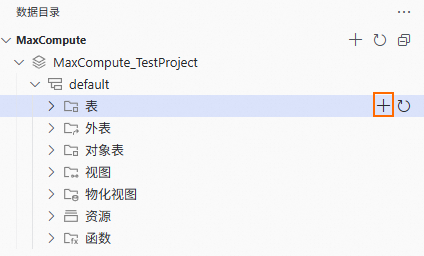
在建立表頁面,您可以通過多種方式建表:
在地區①中填入表名、欄位資訊等。
在地區②中直接填入建表DDL語句。
單擊頁面頂部的發布,完成表建立。
步驟二:工作流程編排
工作流程(Workflow)支援以業務視角通過可視化拖拽的方式編排多種不同類型的資料開發節點,調度時間等通用參數無需單獨配置,可以協助您輕鬆管理複雜的任務工程。
在Data Studio頁面,單擊頁面左側一級菜單
 ,進入資料開發功能。在資料開發左側列表中找到專案目錄,單擊專案目錄右側的
,進入資料開發功能。在資料開發左側列表中找到專案目錄,單擊專案目錄右側的 ,選擇建立工作流程。
,選擇建立工作流程。進入工作流程編輯功能介面前,請先輸入工作流程名稱,單擊確定,進入工作流程編輯介面。
進入工作流程編輯功能介面後,單擊畫布中央的拖拽或點擊添加節點,然後在添加節點對話方塊中,指定節點類型為虛擬節點,自訂節點名稱,單擊確認。
從工作流程編輯功能介面左側的節點類型列表中找到自己需要的節點類型,並將其拖至畫布中,在添加節點對話方塊中輸入節點名稱,單擊確認。

從工作流程編輯功能介面右側的畫布上,找到需要建立依賴關係的兩個節點,滑鼠移至上方到其中一個節點下邊緣的中間位置,當滑鼠變為+後,開始拖動滑鼠,將箭頭拖動至另一個節點後鬆開。設定依賴關係如下圖所示後,在頂部工具列單擊儲存。
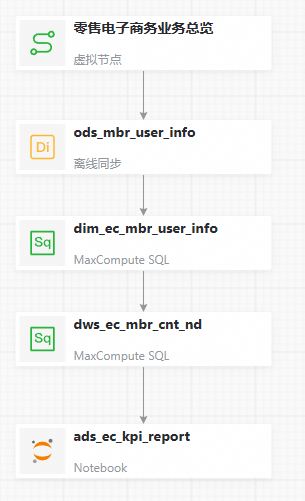
儲存成功後,可按需對畫布進行布局調整。
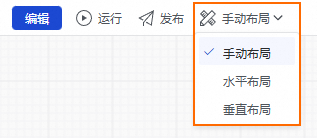
從工作流程畫布右側找到並單擊調度配置,在調度配置面板中,依次配置工作流程的調度參數及節點依賴。單擊調度參數中的添加參數,參數名輸入框中輸入bizdate,在參數值下拉式清單中選擇$[yyyymmdd-1]。
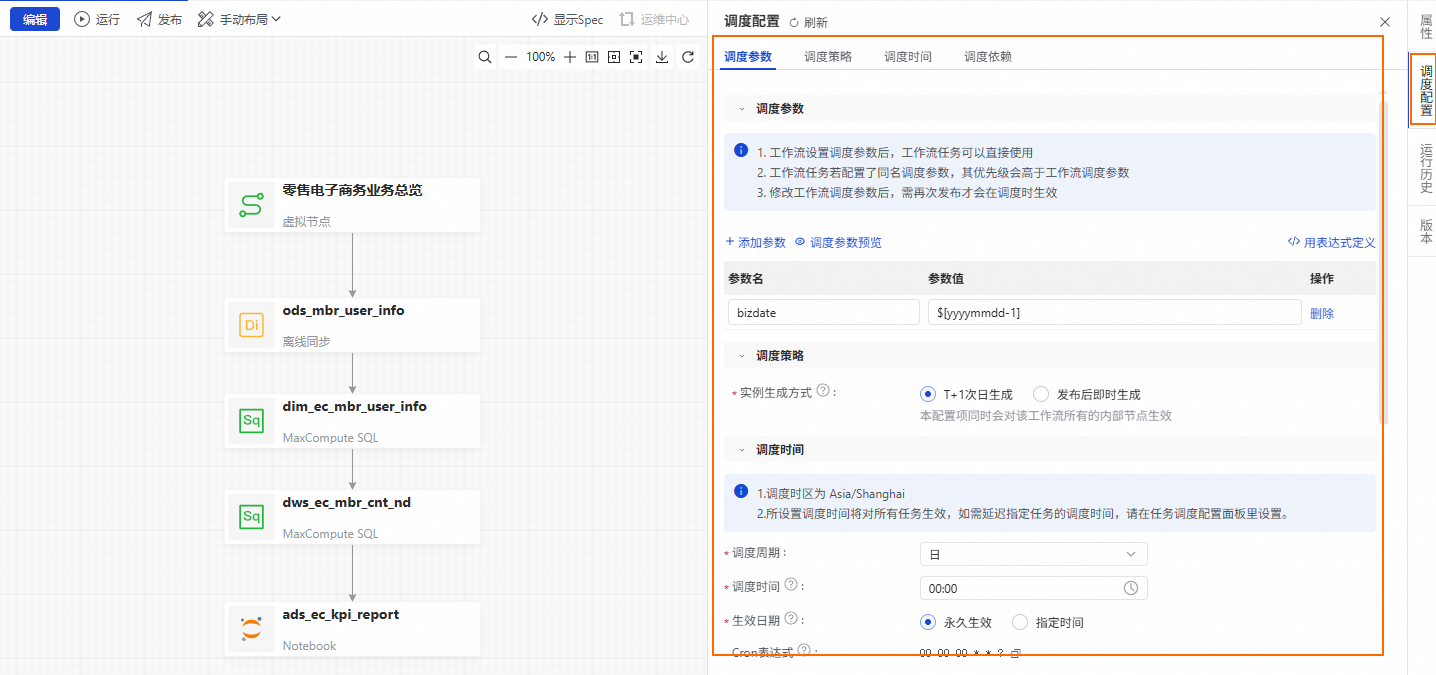
單擊使用工作空間根節點,將工作空間根節點作為工作流程的上遊依賴。
單擊工作流程畫布上方的發布,頁面右下方會出現發佈動作介面,單擊上線發布內容操作介面中的開始發布生產後,依次進行檢查和確認即可。

步驟三:多引擎協同開發
Data Studio支援Data Integration、MaxCompute、Hologres、EMR、Flink、Python、Notebook、ADB等數十種不同引擎類型的節點的數倉開發,支援複雜的調度依賴,提供開發環境與生產環境隔離的研發模式。本實驗以建立Flink SQL Streaming節點為例。
在Data Studio頁面,單擊頁面左側一級菜單
 ,進入資料開發功能介面。在資料開發功能介面左側列表中找到專案目錄,單擊專案目錄右側的
,進入資料開發功能介面。在資料開發功能介面左側列表中找到專案目錄,單擊專案目錄右側的 ,單擊串聯功能表中的Flink SQL Streaming進入節點編輯功能介面。在進入節點編輯功能介面前,請先輸入節點名稱,敲擊斷行符號鍵,等待即可。
,單擊串聯功能表中的Flink SQL Streaming進入節點編輯功能介面。在進入節點編輯功能介面前,請先輸入節點名稱,敲擊斷行符號鍵,等待即可。預設節點名稱:
ads_ec_page_visit_log。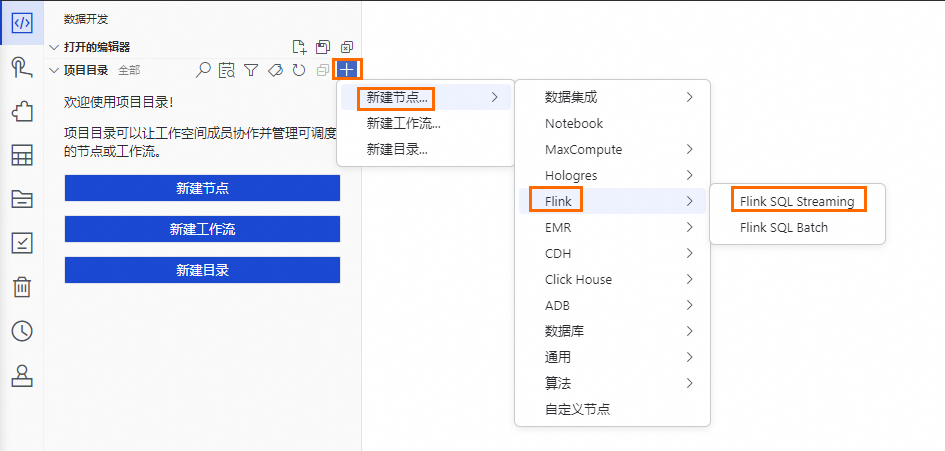
在節點編輯功能介面,將預設Flink SQL Stream代碼粘貼到代碼編輯器中。
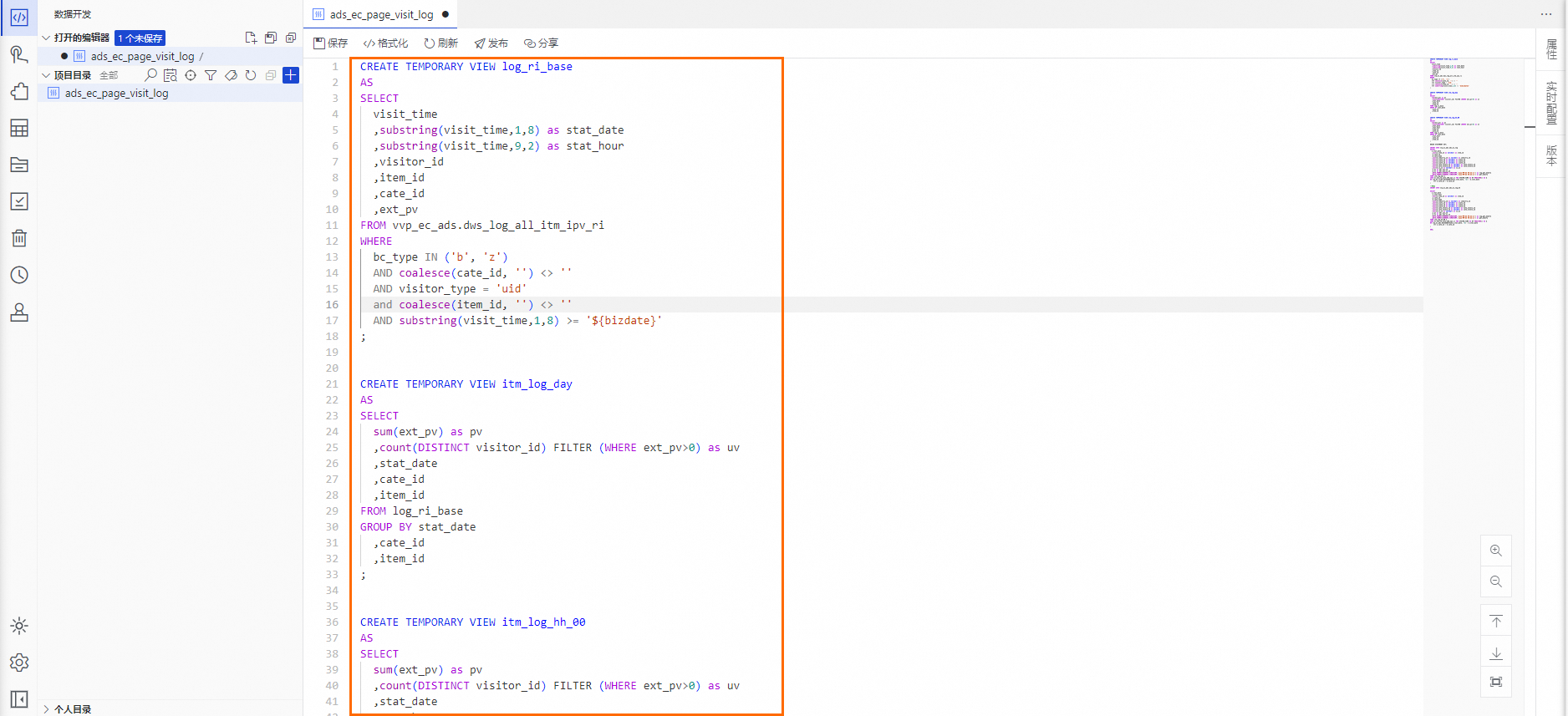
在節點編輯功能介面,單擊代碼編輯器右側的即時配置,配置Flink資源資訊、指令碼參數及Flink運行參數相關參數資訊。
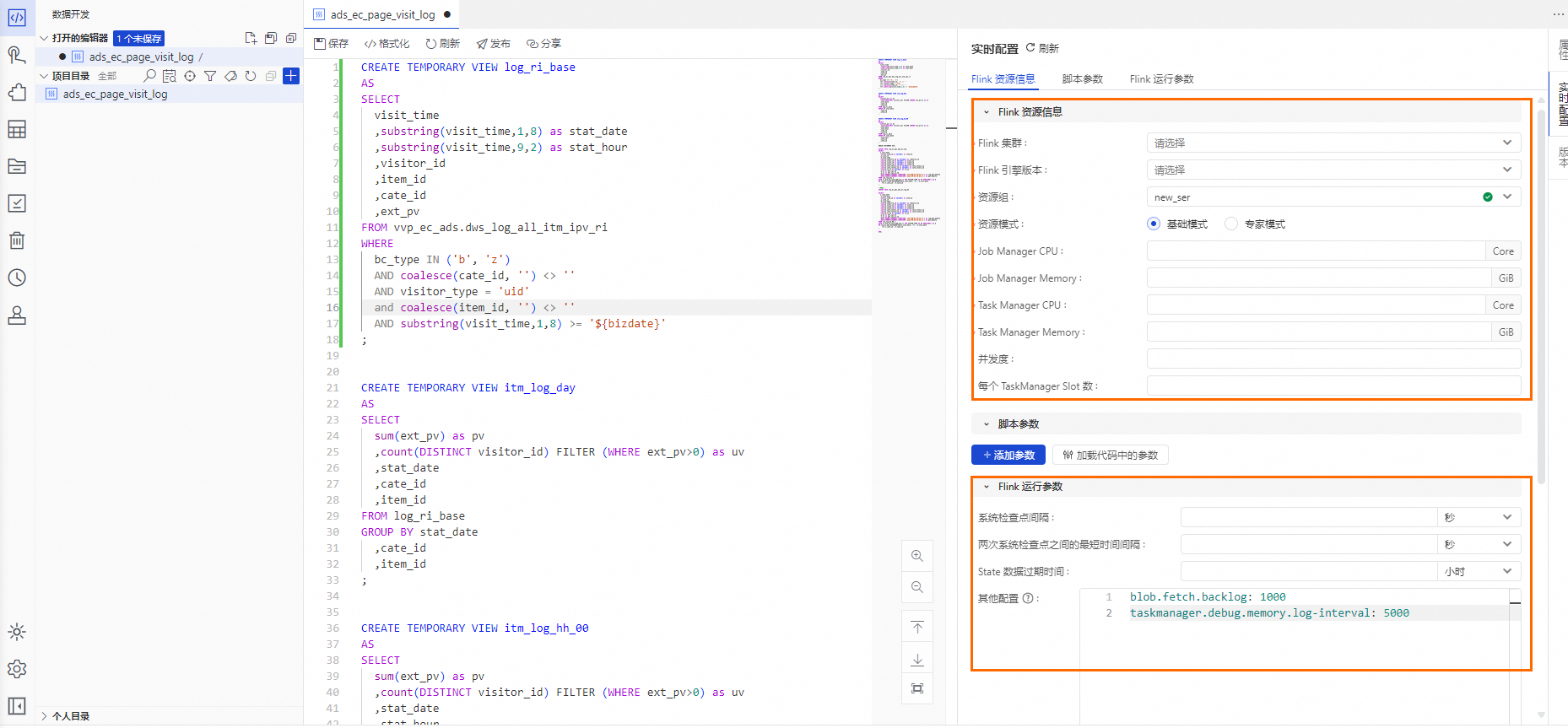
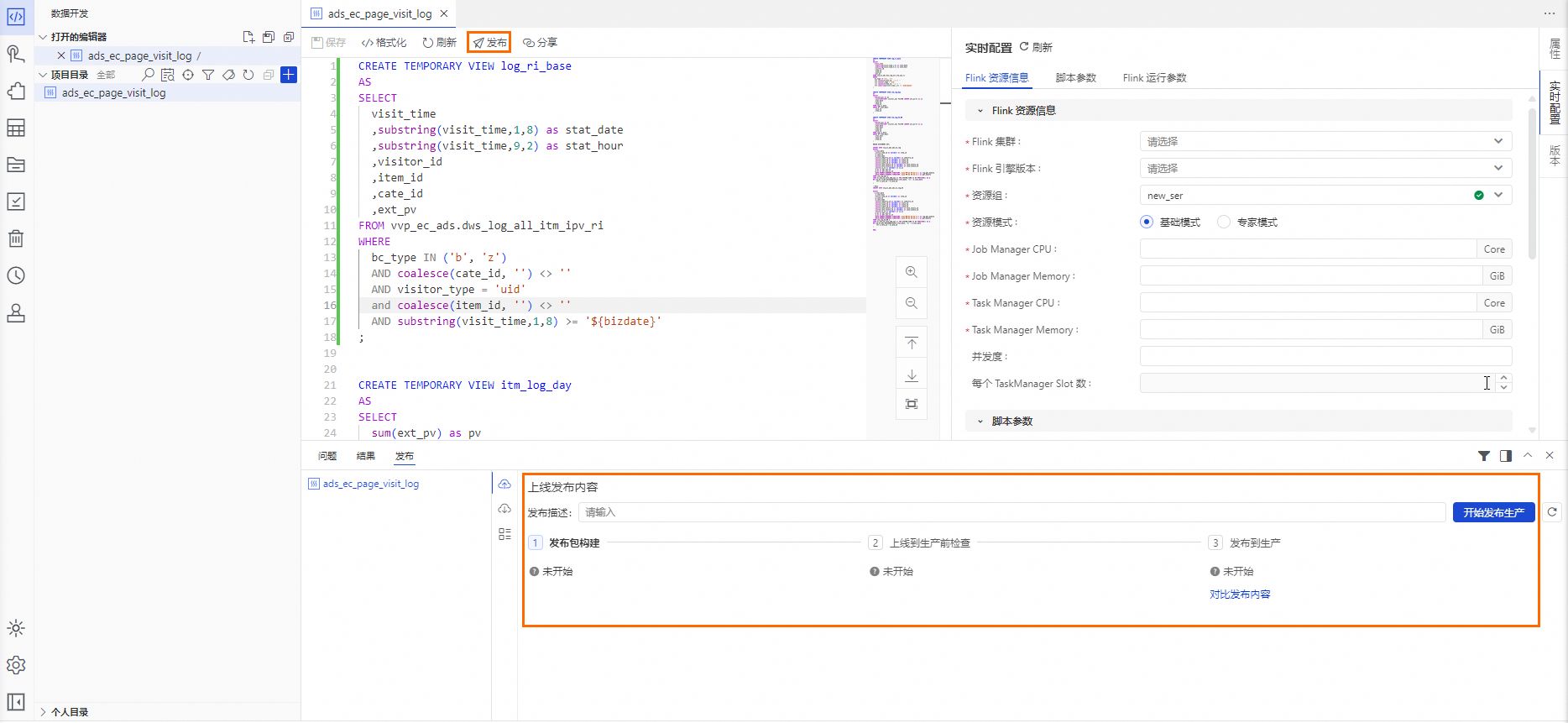
完成即時配置後,單擊代碼編輯器上方的儲存,單擊代碼編輯器上方的發布,頁面右下方會出現發佈動作介面,單擊上線發布內容操作介面中的開始發布生產後,依次進行檢查和確認即可。
步驟四:進入個人開發環境
個人開發環境,支援自訂容器鏡像,支援對接使用者NAS,支援對接Git,支援Python編程與Notebook。
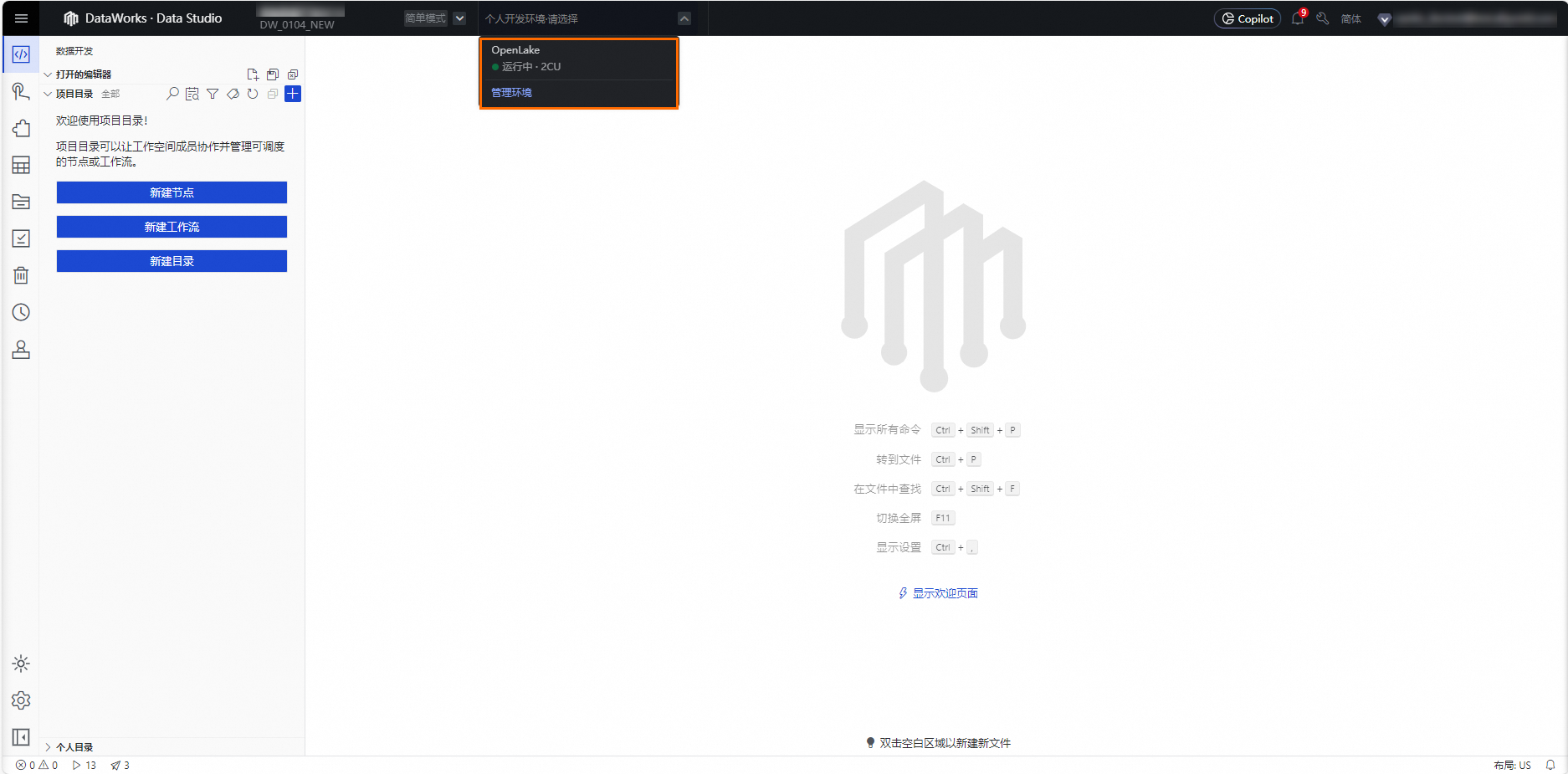
在Data Studio頁面,單擊頁面頂部![]() ,在下拉式功能表中選中您需要進入的個人開發環境,等待頁面返回即可。
,在下拉式功能表中選中您需要進入的個人開發環境,等待頁面返回即可。
步驟五:Python編程與調試
DataWorks深度整合DSW,在進入個人開發環境後,Data Studio支援Python語言的編寫、調試、運行及調度。
該步驟需要先完成步驟四:進入個人開發環境後方可開始。
在Data Studio頁面,且已進入個人開發環境,單擊
workspace目錄,單擊個人目錄右側的 ,在左側列表上會新增一個未命名的檔案,輸入預設檔案名稱,敲擊斷行符號鍵,等待檔案產生即可。
,在左側列表上會新增一個未命名的檔案,輸入預設檔案名稱,敲擊斷行符號鍵,等待檔案產生即可。預設檔案名稱:
ec_item_rec.py。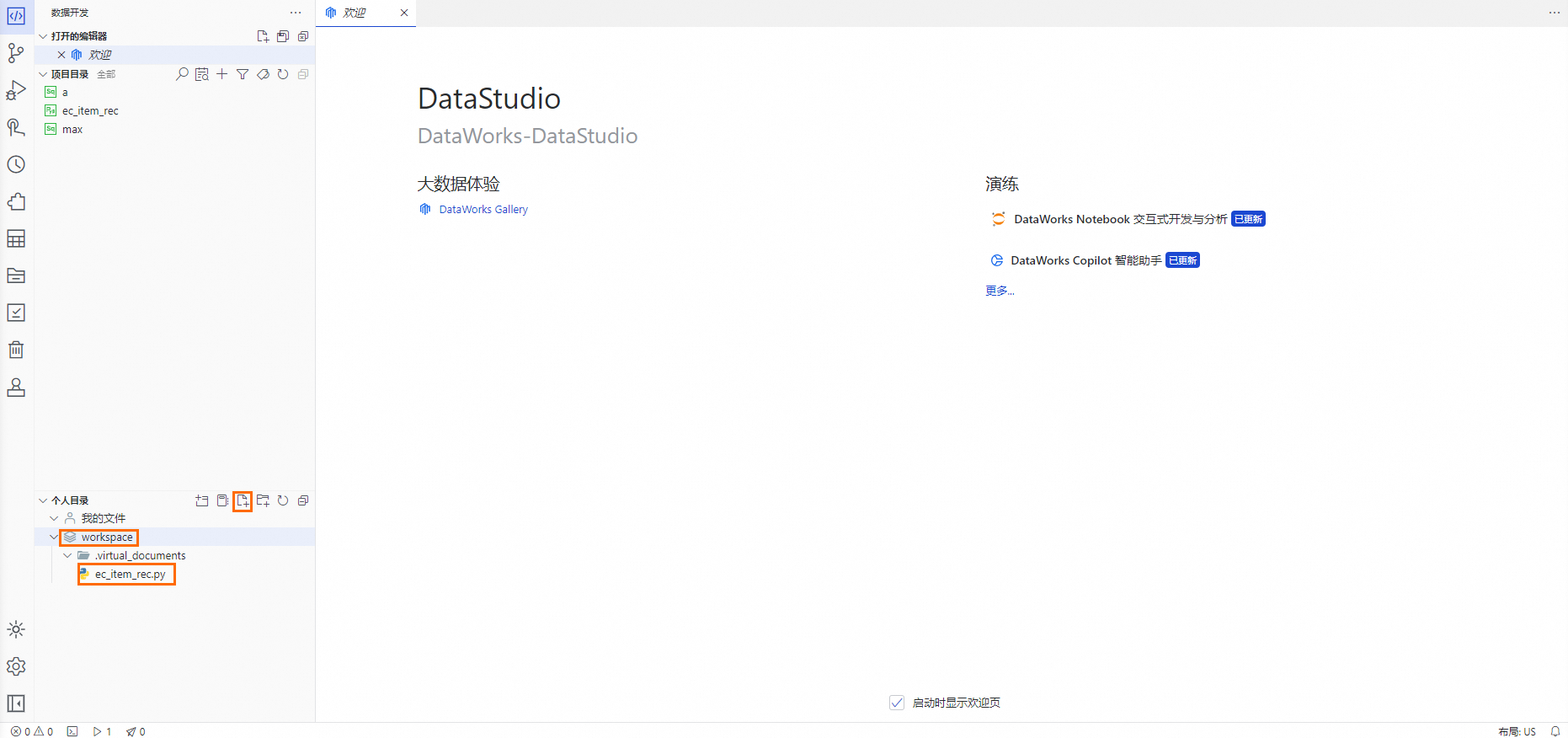
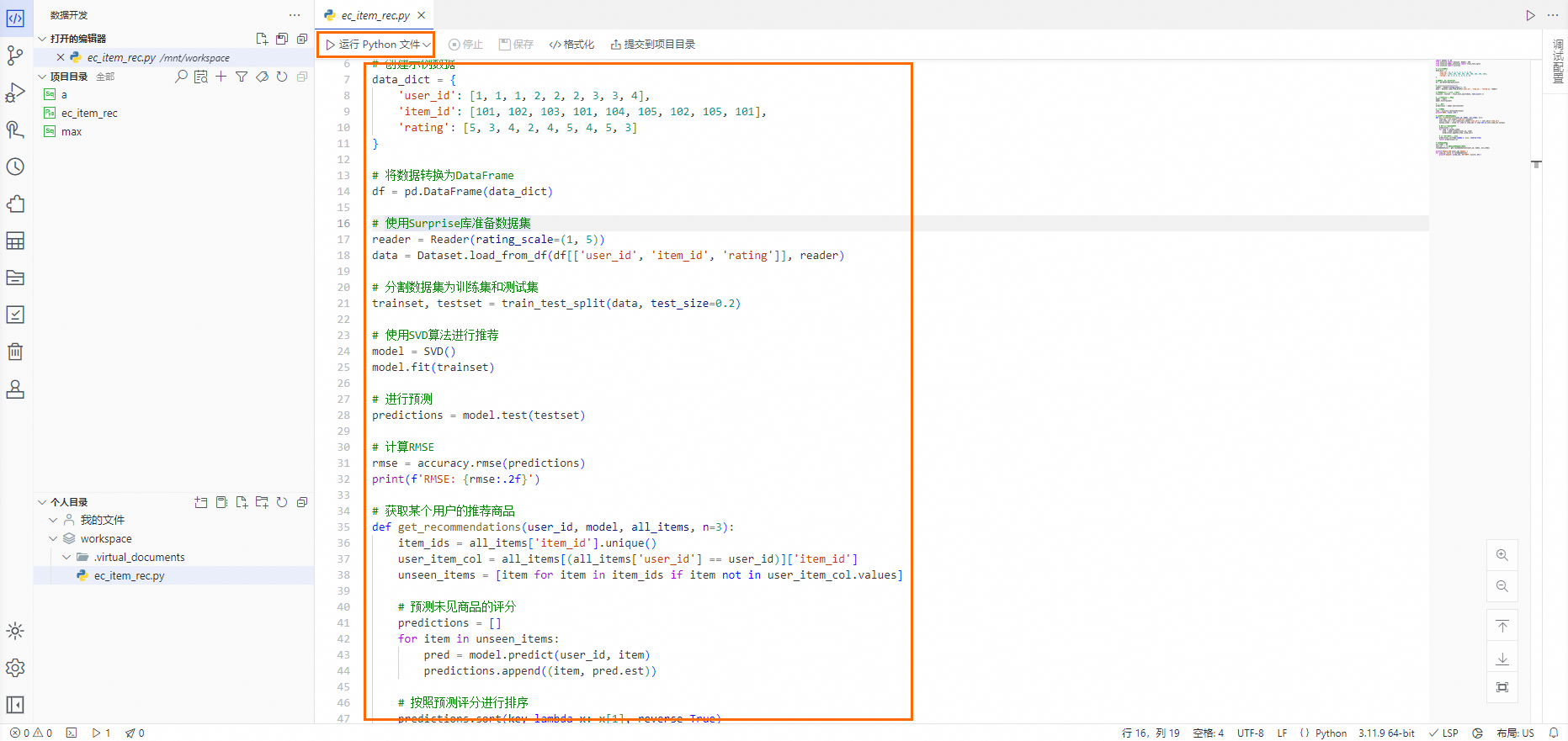
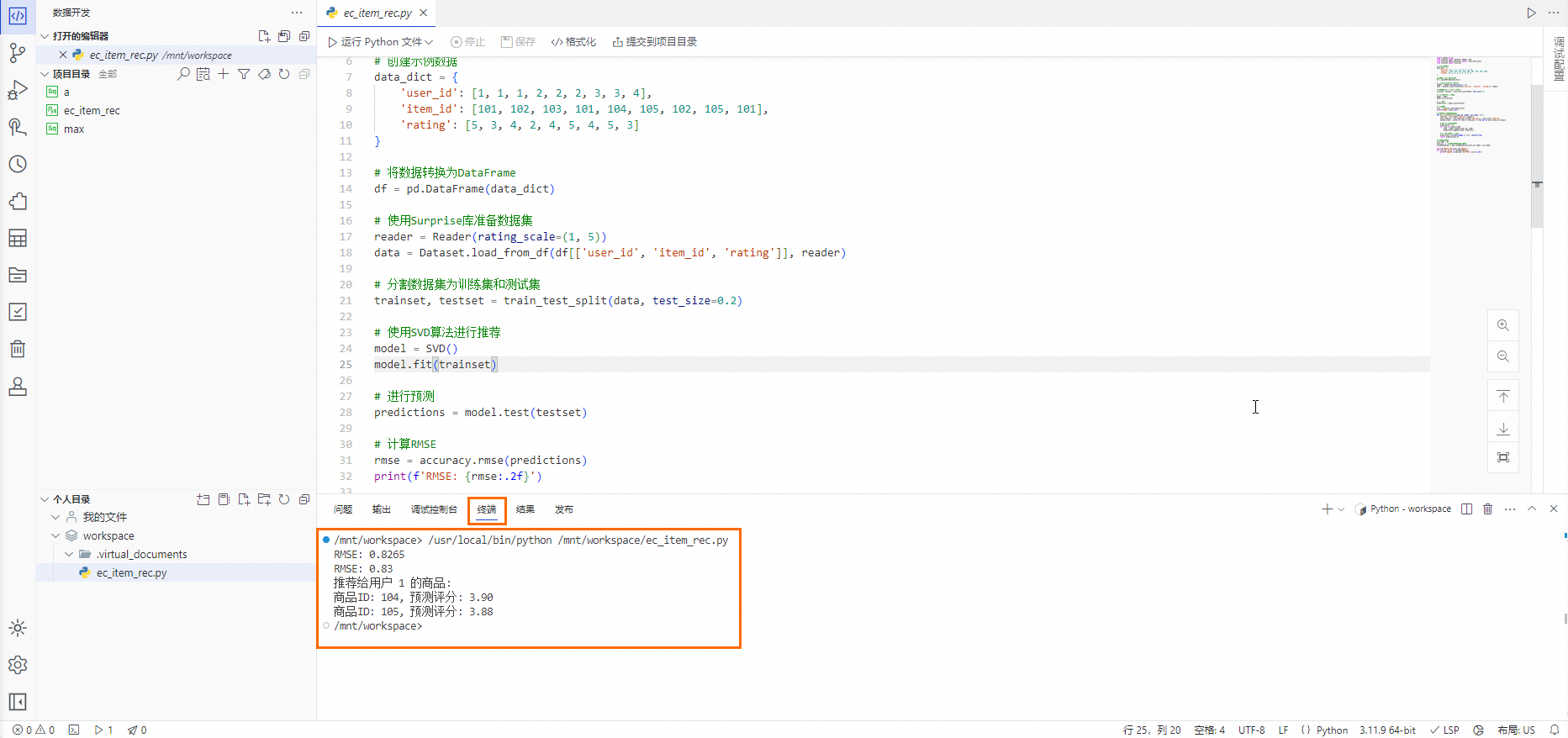
在Python檔案編輯頁面的代碼編輯器中,先輸入預設的Python代碼,再單擊代碼編輯器上方的運行Python檔案,在頁面下方的終端中查詢運行結果。
單擊Python檔案編輯頁面的代碼編輯器上方的調試Python檔案,在代碼編輯器中程式碼號左側可以單擊產生斷點,代碼編輯器左側面板上方單擊
 進行代碼調試。
進行代碼調試。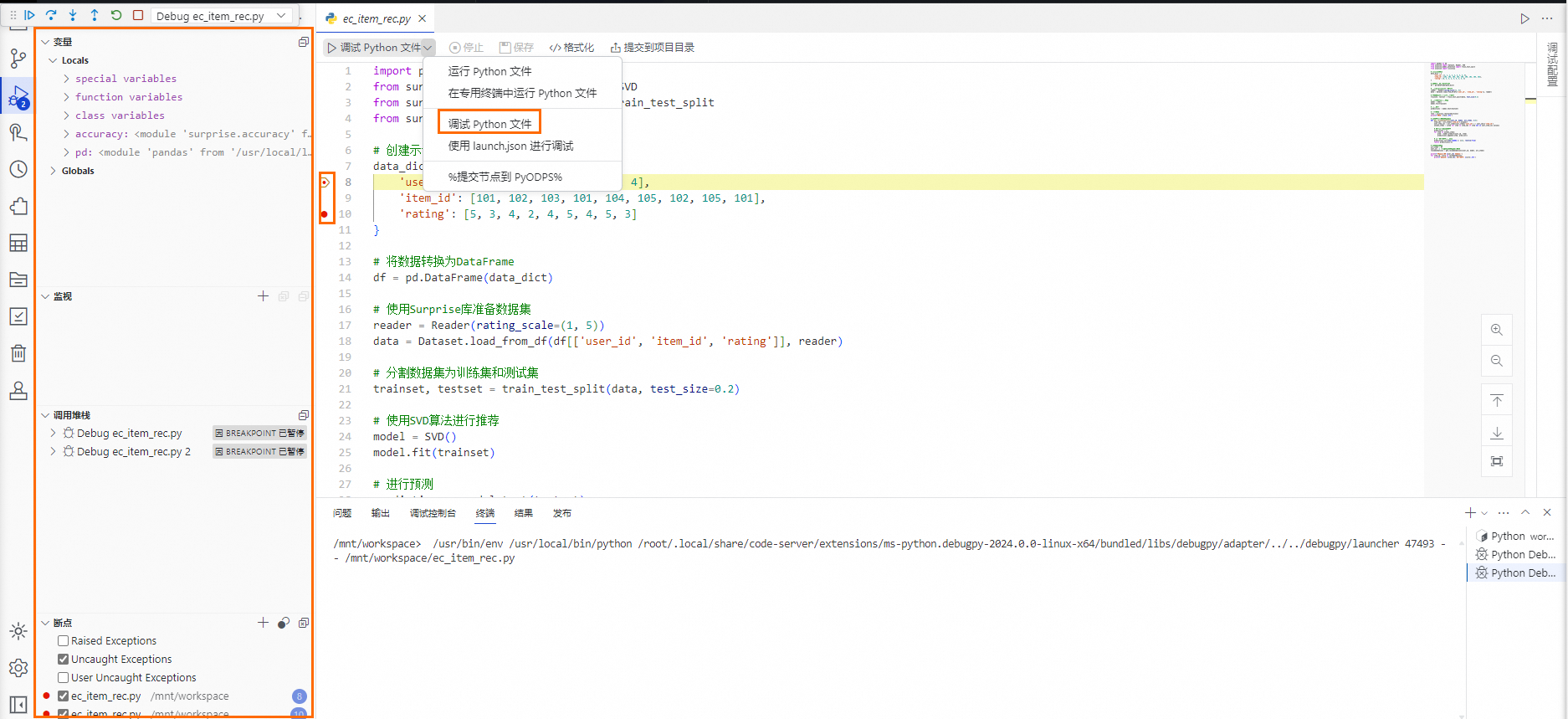
步驟六:Notebook資料探索
在進行Notebook資料探索時,Notebook資料探索相關操作是基於個人開發環境的,您需要先完成前面的步驟四:進入個人開發環境後方可開始。
建立Notebook
進入Data Studio > 資料開發。
在個人目錄中,按右鍵目標檔案夾,選擇建立Notebook。
輸入Notebook名稱,單擊斷行符號鍵 或 頁面空白位置,使Notebook名稱生效。
在個人目錄中單擊Notebook名稱,即可開啟並進入Notebook編輯頁面。
Notebook使用
如下內容為獨立操作步驟,不分先後順序,可以按需體驗。
Notebook多引擎開發
EMR Spark SQL
在DataWorks Notebook中單擊
 按鈕,建立SQL Cell。
按鈕,建立SQL Cell。在SQL Cell中,輸入以下語句,完成dim_ec_mbr_user_info 表的查詢。
在SQL Cell右下角,選擇SQL Cell類型為EMR Spark SQL,選擇計算資源為
openlake_serverless_spark。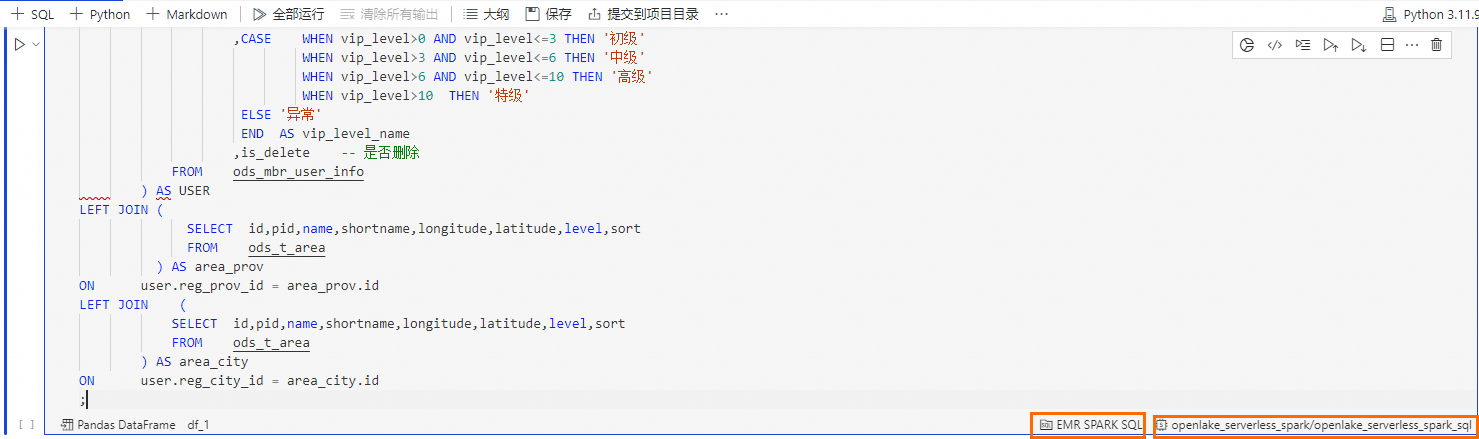
單擊運行按鈕,等待運行完成,查看資料結果。
StarRocks SQL
在DataWorks Notebook中單擊
 按鈕,建立SQL Cell,如下圖:
按鈕,建立SQL Cell,如下圖:在SQL Cell中,輸入以下語句,完成dws_ec_trd_cate_commodity_gmv_kpi_fy 表的查詢。
在SQL Cell右下角,選擇SQL Cell類型為StarRocks SQL,選擇計算資源為
openlake_starrocks。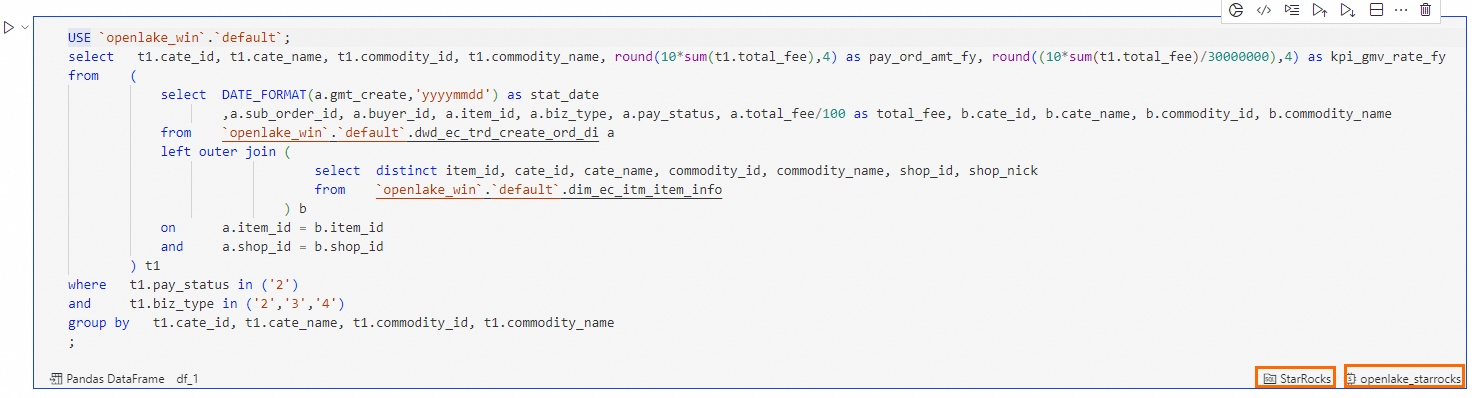
單擊運行按鈕,等待運行完成,查看資料結果。
Hologres SQL
在DataWorks Notebook中單擊
按鈕,建立SQL Cell。在SQL Cell中,輸入以下語句,完成dws_ec_mbr_cnt_std 表的查詢。
在SQL Cell右下角,選擇SQL Cell類型為Hologres SQL,選擇計算資源為
openlake_hologres。
單擊運行按鈕,等待運行完成,查看資料結果。
MaxCompute SQL
在DataWorks Notebook中單擊
按鈕,建立SQL Cell。在SQL Cell中,輸入以下語句,完成dws_ec_mbr_cnt_std 表的查詢。
在SQL Cell右下角,選擇SQL Cell類型為MaxCompute SQL,選擇計算資源為
openlake_maxcompute。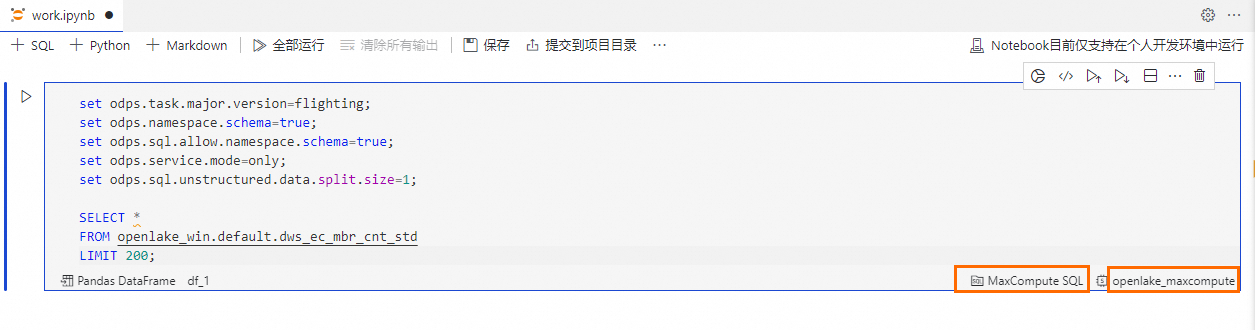
單擊運行按鈕,等待運行完成,查看資料結果。
Notebook互動式資料
在DataWorks Notebook中單擊
 按鈕,建立Python Cell。
按鈕,建立Python Cell。在Python Cell右上方,單擊
 按鈕,呼出DataWorks Copilot智能編程助手。
按鈕,呼出DataWorks Copilot智能編程助手。在DataWorks Copilot輸入框中,輸入以下需求,用於產生一個查詢會員年齡的ipywidgets互動組件。
說明需求描述:使用Python,產生一個會員年齡的滑動條組件,取值範圍從1到100,預設值為20,即時監測組件取值的變化,並將值儲存到全域變數query_age中。
查看DataWorks Copilot產生的Python代碼,單擊接受按鈕。

單擊Python Cell的運行按鈕,等待運行完成,查看互動組件的產生(運行Copilot產生的程式碼,或預設代碼);同時,能夠在互動組件中滑動選擇目標年齡。

在DataWorks Notebook中單擊
 按鈕,建立SQL Cell。
按鈕,建立SQL Cell。在SQL Cell中,輸入以下查詢語句,包含Python中定義的會員年齡變數
${query_age}。SELECT * FROM openlake_win.default.dim_ec_mbr_user_info WHERE CAST(id_age AS INT) >= ${query_age};在SQL Cell右下角,選擇SQL Cell類型為Hologres SQL,選擇計算資源為
openlake_hologres。
單擊運行按鈕,等待運行完成,查看資料結果。
在運行結果中,單擊
 按鈕,產生可視化圖表。
按鈕,產生可視化圖表。
Notebook模型開發與訓練
在DataWorks Notebook中單擊
按鈕,建立SQL Cell。在SQL Cell中,輸入以下語句,完成ods_trade_order表的查詢。
SELECT * FROM openlake_win.default.ods_trade_order;將SQL查詢結果寫入DataFrame變數中,單擊df位置,自訂DataFrame變數名稱(例如:
df_ml)。
單擊SQL Cell的運行按鈕,等待運行完成,查看資料結果。
在DataWorks Notebook中單擊
 按鈕,建立Python Cell。
按鈕,建立Python Cell。在Python Cell中,輸入以下語句,使用Pandas完成資料清洗和處理,並存入DataFrame的新變數
df_ml_clean中。import pandas as pd def clean_data(df_ml): # 產生新的一列:預估訂單總額 = 商品單價 * 商品數量 df_ml['predict_total_fee'] = df_ml['item_price'].astype(float).values * df_ml['buy_amount'].astype(float).values # 將列 'total_fee' 重新命名為 'actual_total_fee' df_ml = df_ml.rename(columns={'total_fee': 'actual_total_fee'}) return df_ml df_ml_clean = clean_data(df_ml.copy()) df_ml_clean.head()單擊Python Cell的運行按鈕,等待運行完成,查看資料清理結果。
在DataWorks Notebook中單擊
按鈕,再次建立Python Cell。在Python Cell中,輸入以下語句,構建一個線性迴歸的機器學習模型,並進行訓練和測試。
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error # 擷取商品價格及總費用 X = df_ml_clean[['predict_total_fee']].values y = df_ml_clean['actual_total_fee'].astype(float).values # 準備資料 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.05, random_state=42) # 建立並訓練模型 model = LinearRegression() model.fit(X_train, y_train) # 預測和評估 y_pred = model.predict(X_test) for index, (x_t, y_pre, y_t) in enumerate(zip(X_test, y_pred, y_test)): print("[{:>2}] input: {:<10} prediction:{:<10} gt: {:<10}".format(str(index+1), f"{x_t[0]:.3f}", f"{y_pre:.3f}", f"{y_t:.3f}")) # 計算均方誤差MSE mse = mean_squared_error(y_test, y_pred) print("均方誤差(MSE):", mse)單擊運行按鈕,等待運行完成,查看模型訓練的測試結果。