本次ARMS Prometheus最新版本為Helm 1.1.17,對應的Agent版本為v4.0.0,包括有多項迭代,提升採集穩定性,修複已知Bug,最佳化資源消耗等。
如果您的叢集內ARMS Prometheus Agent版本為v3.x.x 系列,由於歷史版本存在一些未最佳化項,且存在資料斷線的隱患和風險,因此建議您儘快升級至最新版本。
v4.0.0 版本特性說明
變更類型 | 發布內容 |
新增 | 叢集事件採集任務,支援Kubernetes Deployment大盤。 |
新增 | 根據SLA進行自監控指標埋點,SLA穩定性大盤資料。 |
新增 | ServiceMonitor支援BasicAuth認證方式,Secret需要與ServiceMonitor在同一個命名空間下使用。 |
新增 | Metrics Metadata能力展示具體指標含義。 |
新增 | 支援傳遞Agent Chart版本到服務端,服務端根據該版本號碼初始化或升級大盤。 |
新增 | RemoteWrite自監控指標,統計每批次發送資料耗時。 |
新增 | 基礎指標採集報錯和採集延遲自監控指標。 |
新增 | 業務指標採集報錯和延遲自監控指標。 |
最佳化 | RemoteWrite預設參數queue_config設定為min_shards=10,max_samples_per_send=5000,capacity=10000,提升大規模叢集適應能力。 |
最佳化 | CSI採集Job服務發現方式,主要為PV採集相關。 |
最佳化 | senderLoop下發頻率,修改syncWorkersSeries頻率,減少不必要擾動。 |
最佳化 | 精簡部分日誌,最佳化部分日誌增加抓取鏈路耗時更細節展示。 |
最佳化 | 基礎指標採集Job單獨固定採集周期和採集逾時設定,不再使用Global配置,減少對基礎指標採集受到的不必要幹擾。 |
最佳化 | Master-Slave多副本模式下互相影響邏輯,Master與Worker,Worker與Worker之間互相不再影響,提升穩定性。 |
最佳化 | Master下發Targets策略,節省大約30%的CPU40%的Memory資源開銷,提升採集效能。 |
最佳化 | metrics_relabel最佳化,CPU佔用降低70%。 |
最佳化 | 多租情境Informer監聽邏輯,多租情境下節省CPU開銷約20%。 |
最佳化 | CoreDNS網域名稱解析偶發失敗,自動切換緩衝IP並沿用,弱依賴CoreDNS即時網域名稱解析,提升資料發送穩定性。 |
最佳化 | SendConfig下發採集配置邏輯,提升下發穩定性。 |
最佳化 | Master預抓取策略,節省Master資源開銷,提升Master服務發現和Targets調度能力。 |
最佳化 | 單批次大包大於1 MB自適應,減少因後端限制導致資料包丟失情況。 |
BugFix | ScrapeLoop個別採集Target無法停止導致採集重複問題。 |
BugFix | 多租情境Pod的Label緩衝中更新不及時,造成一個時間軸變為兩條問題。 |
BugFix | Master對於OOM或者Restart副本偶發Targets下發異常,導致部分採集Targets丟失問題。 |
BugFix | RemoteWrite中解析Secret類型問題和傳輸Header問題。 |
BugFix | Kubernetes-pods關閉操作偶發不生效問題。 |
BugFix | 修複Global預設參數和external_labels不生效問題,同時支援自訂修改。 |
升級風險
升級風險:本次升級到Helm 1.1.17/Agent v4.0.0為有損升級,按照叢集監控資料擷取量級的不同(Targets和Series的量級),存在監控資料斷線的風險,預計斷線時間在0~5分鐘,不同叢集可能存在一定的差異。
升級前:建議您在升級前執行步驟一、升級前預檢查項(必選),確保最大程度降低升級對於叢集監控資料的影響。
升級後:如果您在升級後探索資料異常,升級後請務必按照三、升級後檢查項(可選)進行檢查,一旦發現問題可參考升級後的常見問題進行檢查和應對,如果未能解決您可以在DingTalk中搜尋Prometheus值班號(釘號:aliprometheus),聯絡產品技術專家進行諮詢。
升級方式
一、升級前預檢查項(必選)
Helm 1.1.16之前版本(不包含1.1.16)升級到最新Helm 1.1.17,曾經修改過的一些參數在升級過程中不會保留,需要升級前進行檢查,如果存在修改過的參數需要在新版本中保留,需要您在升級後手動修改為升級前的參數值。
Helm 1.1.16之後的版本升級(包含1.1.16)支援參數的繼承,後續升級則不需要再關注修改的參數。升級前參數檢查方法如下:
單擊目的地組群名稱超連結,然後在左側導覽列選擇工作負載 > 無狀態,切換命名空間為
arms-prom,並在目標arms-prometheus-ack-arms-prometheus的操作列選擇更多 > 查看Yaml,查看完整YAML。需要檢查的參數如下。
spec.replicas副本數,如果為1(升級後預設為1)則不需要單獨關注。
spec.containers下的args(Agent)啟動參數,未開啟多租則此參數不存在,如果有自行設定則在升級後需要手動修改回升級前值。
tenant_userid
tenant_clusterid
tenant_token
spec.containers.resources limits預設為3核4 GB,requests預設為1核1 GB。
若非預設則需要記錄,建議在升級後手動修改回升級前的數值。

對於上述參數有修改且需要保留的,需要自行記錄數值,在升級後使用同樣方法擷取完整YAML後,修改並單擊更新即可。
二、升級具體方法
建議通過ACK容器頁面,進行ARMS Prometheus組件升級Helm版本,具體操作如下:
單擊目的地組群名稱超連結,然後在左側導覽列選擇營運管理 > 組件管理,單擊日誌與監控頁簽,找到ack-arms-prometheus卡片,單擊升級進行升級。
升級完成後,在左側導覽列選擇營運管理 > Prometheus監控,然後單擊右上方的跳轉到Prometheus服務,系統會跳轉至Prometheus控制台的Prometheus執行個體大盤列表頁面,您可以查看具體Agent運行狀態、指標採集情況等。
同時在左側導覽列單擊設定,然後在設定頁簽,查看Helm組件是否已經升級到最新版本。

三、升級後檢查項(可選)
登入ARMS控制台。
在左側導覽列選擇,進入可觀測監控 Prometheus 版的執行個體列表頁面。
單擊目標Prometheus執行個體名稱,然後在左側導覽列單擊服務發現。單擊Targets頁簽,升級後查看Job採集情況,總覽採集情況。
在左側導覽列單擊設定,然後在自監控頁簽右上方單擊前往Grafana查看大盤。Helm組件升級後可重點關注Agent運行狀態,包括:副本數符合預期、資料發送速率無異常、資源消耗無異常、資料發送無異常。
在自監控頁面的agent自監控頁簽,可以查看Prometheus Agent自監控大盤。
Helm組件升級後,可重點關注4個基礎指標採集Job:_arms/kubelet/cadvisor、_arms/kubelet/metric、_kube-state-metrics、node-exporter。同時在頁面右上方可選擇時間範圍,查看時間跨度覆蓋升級前後,觀察升級前後採集是否存在異常情況。
升級後的常見問題
升級後,實際運行副本數與預期Replica不相等
您需要檢查是否有Agent處於Pending狀態,ARMS Prometheus強依賴於全部副本處於Running狀態才可以正常工作。您可以在Container Service控制台的目的地組群工作負載 > 無狀態頁面的arms-prom命名空間下,查看全部副本的運行狀態。
升級後,Agent消耗Memory/CPU較高
您需要檢查是否有發送資料出現異常,資料發送異常會導致Agent記憶體堆積資料,進而導致資源消耗增高。您可以在Container Service控制台的目的地組群營運管理 > Prometheus監控頁面,單擊其他頁簽,在Prometheus Agent中查看Memory/CPU的資源消耗情況。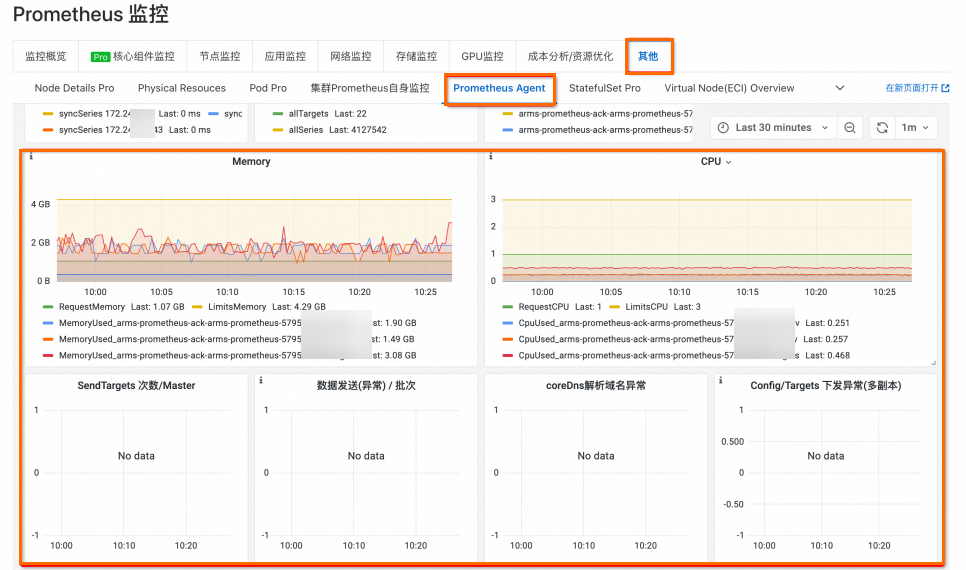
升級後,出現基礎指標異常(完全斷線或者不連續)
例如node_*** (表徵圖①)、container_***(表徵圖②)、kubelet_***(表徵圖③)、kube_***(表徵圖④)指標等,則需要排查基礎指標採集Job是否有報錯,您可以在Prometheus服務控制台的服務發現頁面的Targets頁簽下,查看這些指標的情況。若發現存在報錯請在DingTalk中搜尋Prometheus值班號(釘號:aliprometheus),聯絡產品技術專家協助解決。
升級後,出現RemoteWrite流量下跌或者出現RemoteWrite側部分資料缺失(若沒有配置則忽略)
新版本v4.0.0中RemoteWrite的write_relabel_configs會自動生效,歷史版本中該欄位對應的能力未生效,若配置了drop、keep等動作,則會出現流量一定程度上的下跌,可自行酌情修改該欄位。您可以在Prometheus服務控制台的設定頁面的設定頁簽下,單擊編輯Prometheus.yaml,然後在彈出的對話方塊中修改該欄位。