このトピックでは、近似関数の基本的な構文と例について説明します。
Simple Log Service は、次の近似関数をサポートしています。
関数名 | 構文 | 説明 | SQL サポート | SPL サポート |
approx_distinct(x) | x 内の個別値の概数を計算します。デフォルトの標準誤差は 2.3% です。 | √ | × | |
approx_distinct(x, e) | x 内の個別値の概数を計算し、カスタムの標準誤差を指定できます。 | √ | × | |
approx_percentile(x, percentage) | x を昇順にソートし、指定された percentage での x の近似値を返します。結果は近似値であり、その安定性と一貫性は保証されません。 | √ | × | |
approx_percentile(x, array[percentage01, percentage02...]) | x を昇順にソートし、percentage01 や percentage02 などの指定されたパーセンテージでの x の近似値を返します。結果は近似値であり、その安定性と一貫性は保証されません。 | √ | × | |
approx_percentile(x, weight, percentage) | x とその重みの積を昇順にソートし、指定された percentage での x の近似値を返します。結果は近似値であり、その安定性と一貫性は保証されません。 | √ | × | |
approx_percentile(x, weight, array[percentage01, percentage02...]) | x とその重みの積を昇順にソートし、percentage01 や percentage02 などの指定されたパーセンテージでの x の近似値を返します。結果は近似値であり、その安定性と一貫性は保証されません。 | √ | × | |
approx_percentile(x, weight, percentage, accuracy) | x とその重みの積を昇順にソートし、指定された percentage での x の近似値を返します。戻り値の精度を設定できます。結果は近似値であり、その安定性と一貫性は保証されません。 | √ | × | |
numeric_histogram(bucket, x) | x の近似ヒストグラムをバケット (ヒストグラム列) の数に基づいて計算します。結果は JSON フォーマットで返されます。 | √ | × | |
numeric_histogram(bucket, x, weight) | x の近似ヒストグラムをバケット (ヒストグラム列) の数に基づいて計算します。結果は JSON フォーマットで返されます。x の重みを設定できます。 | √ | × | |
numeric_histogram_u(bucket, x) | x の近似ヒストグラムをバケット (ヒストグラム列) の数に基づいて計算します。結果は複数行、複数列のフォーマットで返されます。 | √ | × | |
approx_most_frequent(k, x) | 列 x 内で最も頻繁に出現する | √ | × |
approx_distinct 関数
approx_distinct 関数は、x 内の個別値の概数を計算します。
構文
x 内の個別値の概数を計算します。デフォルトの標準誤差は 2.3% です。
approx_distinct(x)x 内の個別値の概数を計算し、カスタムの標準誤差を指定できます。
approx_distinct(x, e)
パラメーター
パラメーター | 説明 |
x | 値は任意のデータの型にすることができます。 |
e | カスタムの標準誤差。値は [0.0115, 0.26] の範囲内である必要があります。 |
戻り値の型
bigint
例
例 1: count 関数を使用してページビュー (PV) を計算し、approx_distinct 関数を使用して client_ip フィールドの個別値に基づいてユニークビジター (UV) の概数を計算します。標準誤差は 2.3% です。
クエリ文
* |SELECT count(*) AS PV, approx_distinct(client_ip) AS UVクエリと分析結果

例 2: count 関数を使用して PV を計算し、approx_distinct 関数を使用して client_ip フィールドの個別値に基づいて UV の概数を計算します。カスタムの標準誤差は 10% です。
クエリ文
* |SELECT count(*) AS PV, approx_distinct(client_ip,0.1) AS UVクエリと分析結果

approx_percentile 関数
approx_percentile 関数は、x を昇順にソートし、指定された percentage での近似値を返します。結果は近似値であるため、その安定性と一貫性は保証されません。
構文
x を昇順にソートし、指定された percentage での x の近似値を返します。戻り値は double です。
approx_percentile(x, percentage)x を昇順にソートし、percentage01 や percentage02 などの指定されたパーセンテージでの x の近似値を返します。戻り値は array(double,double) 型です。
approx_percentile(x, array[percentage01, percentage02...])x とその重みの積を昇順にソートし、指定された percentage での x の近似値を返します。戻り値は double です。
approx_percentile(x, weight, percentage)x とその重みの積を昇順にソートし、percentage01 や percentage02 などの指定されたパーセンテージでの x の近似値を返します。戻り値は array(double,double) 型です。
approx_percentile(x, weight, array[percentage01, percentage02...])x とその重みの積を昇順にソートし、指定された percentage での x の近似値を返します。戻り値は double です。戻り値の精度を設定することもできます。
approx_percentile(x, weight, percentage, accuracy)
パラメーター
パラメーター | 説明 |
x | 値は double 型である必要があります。 |
percentage | パーセント値。値は [0, 1] の範囲内である必要があります。 |
accuracy | 精度。値は (0, 1) の範囲内である必要があります。 |
weight | 重み。値は 1 より大きい整数である必要があります。 重みを設定した場合、システムは x と重みの積に基づいてデータをソートします。 |
戻り値の型
double または array(double,double)
例
例 1: request_time 列をソートし、50 パーセンタイルでの request_time フィールドの近似値を返します。
クエリ文
*| SELECT approx_percentile(request_time,0.5)クエリと分析結果

例 2: request_time 列をソートし、10、20、70 パーセンタイルでの request_time の値を返します。
クエリ文
*| SELECT approx_percentile(request_time,array[0.1,0.2,0.7])クエリと分析結果

例 3: この例では、request_time 値とその重みの積に基づいて request_time 列をソートし、request_time フィールドから 50 パーセンタイルの近似値を返します。request_time 値が 20 未満の場合、重みは 100 で、それ以外の場合は 10 です。
クエリ文
* | SELECT approx_percentile( request_time,case when request_time < 20 then 100 else 10 end, 0.5 )クエリと分析結果

例 4: request_time とその重みの積で request_time 列をソートし、80 および 90 パーセンタイルでの request_time の近似値を返します。request_time が 20 未満の場合、重みは 100 です。それ以外の場合、重みは 10 です。
クエリ文
* | SELECT approx_percentile( request_time,case when request_time < 20 then 100 else 10 end, array [0.8,0.9] )クエリと分析結果

例 5: request_time とその重みの積で request_time 列をソートし、精度 0.2 で 50 パーセンタイルでの request_time フィールドの近似値を返します。ここで、request_time が 20 未満の場合は重みが 100、それ以外の場合は 10 です。
クエリ文
* | SELECT approx_percentile( request_time,case when request_time < 20 then 100 else 10 end, 0.5, 0.2 )クエリと分析結果
numeric_histogram 関数
numeric_histogram 関数は、x の近似ヒストグラムを計算します。結果は JSON フォーマットで返されます。
構文
指定されたバケット数に基づいて x の近似ヒストグラムを計算します。
numeric_histogram(bucket, x)指定されたバケット数に基づいて x の近似ヒストグラムを計算します。x の重みを指定することもできます。
numeric_histogram(bucket, x, weight)
パラメーター
パラメーター | 説明 |
bucket | ヒストグラムの列数。値は bigint 型である必要があります。 |
x | 値は double 型である必要があります。 |
weight | 重み。値は 0 より大きい整数である必要があります。 重みを設定した場合、システムは x と重みの積に基づいてデータをグループ化します。 |
戻り値の型
JSON
例
例 1: POST リクエストのリクエスト期間の近似ヒストグラムを計算します。
クエリ文
request_method:POST | SELECT numeric_histogram(10,request_time)クエリと分析結果

例 2: POST リクエストのリクエスト期間の重み付けされた近似ヒストグラムを計算します。重みは request_time 値に基づいています。
クエリ文
request_method:POST| SELECT numeric_histogram(10, request_time,case when request_time<20 then 100 else 10 end)クエリと分析結果

numeric_histogram_u 関数
numeric_histogram_u 関数は、x の近似ヒストグラムを計算します。結果は複数行、複数列のフォーマットで返されます。
構文
numeric_histogram_u(bucket, x)パラメーター
パラメーター | 説明 |
bucket | ヒストグラムの列数。値は bigint 型である必要があります。 |
x | 値は double 型である必要があります。 |
戻り値の型
double
例
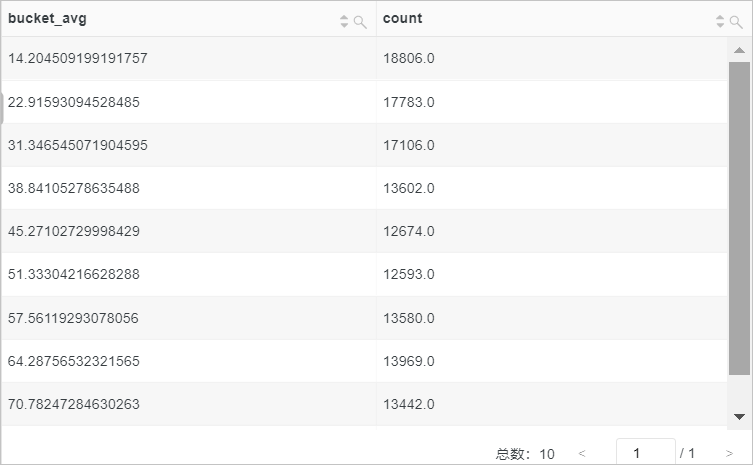
POST リクエストのリクエスト期間の近似ヒストグラムを計算します。
クエリ文
request_method:POST | select numeric_histogram_u(10,request_time)クエリと分析結果
approx_most_frequent 関数
列 x 内で最も頻繁に出現する k 個の値の近似頻度を計算します。
構文
approx_most_frequent(k, x)パラメーター
パラメーター | 説明 |
k | 返す最も頻繁な値の数。たとえば、値 5 は、関数が上位 5 つの最も頻繁な値の近似頻度を返すことを示します。 |
x | 値は varchar 型である必要があります。 |
戻り値の型
map(varchar, bigint)
例
content フィールドで最も頻繁に出現する 3 つの値を検索します。
サンプルデータ
content: 'A' 'B' 'A' 'C' 'A' 'B' 'C' 'D' 'E'クエリ文
select approx_most_frequent(3, content)出力
