このトピックでは、プライマリ ApsaraDB RDS for MySQL インスタンスとその読み取り専用 RDS インスタンス間のデータレプリケーション中に発生する遅延の原因と解決策について説明します。
問題の説明
読み取り専用 RDS インスタンスは、MySQL のネイティブなログベースの非同期または準同期レプリケーションメカニズムを使用して、プライマリ RDS インスタンスからデータを同期します。このメカニズムにより、レプリケーション遅延が発生します。レプリケーション遅延は、読み取り専用 RDS インスタンスとプライマリ RDS インスタンス間のデータ不整合を引き起こし、ワークロードに影響を与えます。レプリケーション遅延は、ログの蓄積を引き起こす可能性もあります。その結果、蓄積されたログが読み取り専用 RDS インスタンスのストレージ容量を急速に使い果たしてしまいます。
プライマリ RDS インスタンスで多くのログが生成されている場合、その読み取り専用 RDS インスタンスはロックされる可能性があります。
レプリケーション遅延は、
show slave status \Gコマンドの出力の `second_behind_master` フィールド (秒単位) に表示されます。遅延の計算: 遅延 = 現在時刻 - セカンダリインスタンスで適用中のトランザクションがプライマリインスタンスでコミットされた時点。現在時刻は、
show slave status \Gコマンドを実行した時点を示します。
レプリケーション遅延は、遅延の期間に基づいて次のタイプに分類できます。
1 秒以下の遅延。このタイプの遅延は、計算精度、計算方法、サンプリングポイント、および監視の粒度によって引き起こされます。このタイプの遅延が発生した場合、データレプリケーションは正常に実行されており、問題を無視できます。
1 秒を超える遅延。このタイプの遅延は、読み取り専用 RDS インスタンスの仕様が低い、プライマリ RDS インスタンスの 1 秒あたりのトランザクション数 (TPS) が大きい、プライマリ RDS インスタンスに大規模なトランザクションが存在する、プライマリ RDS インスタンスで DDL 文が長時間実行されるなどのシナリオで発生します。このタイプの遅延が発生した場合は、原因を特定して問題を解決する必要があります。
原因
1 秒以下の遅延の原因
1 秒未満の遅延: 監視時間範囲が大きな値に設定されています。このタイプの実際の遅延は発生せず、問題を無視できます。
指定された監視時間範囲が長期間にわたる場合、監視の粒度は大きくなります。たとえば、監視時間範囲が 3 時間の場合、デフォルトの監視粒度は最大 30 秒になることがあります。毎回計算されるデータは 30 秒間の平均値であり、1 秒未満の遅延が報告される場合があります。ただし、計算される遅延の最小粒度は 1 秒です。
より正確な遅延を取得するには、ApsaraDB RDS コンソールにログインし、[パフォーマンス傾向] タブに移動し、監視時間範囲を 6 分未満の値に設定します。これにより、1 秒の監視粒度で遅延を表示できます。詳細については、「ApsaraDB RDS for MySQL インスタンスのダッシュボード機能を使用する」をご参照ください。
1 秒の遅延: このタイプの遅延は、計算精度、計算方法、サンプリングポイント、および秒をまたぐトランザクションによって引き起こされます。このタイプの実際の遅延は発生せず、問題を無視できます。
ApsaraDB RDS for MySQL では、サンプリングポイントは常に最も近い秒に切り捨てられます。たとえば、00:00:00.95 のサンプリングポイントは 00:00:00 のサンプリングポイントと見なされ、00:00:01.05 のサンプリングポイントは 00:00:01 のサンプリングポイントと見なされます。たとえば、サンプリングポイントが次の秒にまたがる場合、実際の遅延が 1 秒未満であっても、遅延は 1 秒として計算されます。これは、次の表の 4 行目に示されています。
トランザクション
プライマリ RDS インスタンスでのコミット時間
セカンダリ RDS インスタンスでのコミット時間
現在時刻 (SHOW SLAVE STATUS \G 文を実行した時点)
秒単位の正確な遅延
Trx1
00:00:00.30
00:00:00.50
00:00:00.35
0(0.35) - 0(0.3) = 0
00:00:00.45
0(0.45) - 0(0.3) = 0
Trx2
00:00:00.90
00:00:01.10
00:00:00.95
0(0.95) - 0(0.9) = 0
00:00:01.05
1(1.05) - 0(0.9) = 1
データは 1 秒間隔で収集され、各サンプリングポイントは次の秒にまたがります。ワークロードが重い場合や、秒をまたぐトランザクションが存在する場合、各サンプリングポイントで 1 秒の遅延が得られることがあります。サンプリングポイントが次の秒にまたがらない場合、たとえば 00:00:00.95 の場合、前の表の 3 行目に示すように、0 秒の遅延が得られます。
1 秒を超える遅延の原因
このタイプの遅延は、次の原因で発生する可能性があります。
原因 1: 読み取り専用 RDS インスタンスの仕様が低い
読み取り専用 RDS インスタンスの仕様がプライマリ RDS インスタンスの仕様よりも低く、読み取り専用 RDS インスタンスのワークロードが重い。たとえば、読み取り専用 RDS インスタンスの IOPS が高い場合です。データ整合性のため、読み取り専用 RDS インスタンスは MySQL のネイティブなログベースのレプリケーションメカニズムを使用して、プライマリ RDS インスタンスからデータを同期します。このメカニズムは、I/O スレッドと SQL スレッドを開始します。I/O スレッドはプライマリ RDS インスタンスからログを読み取り、SQL スレッドは読み取り専用 RDS インスタンスにログを適用します。両方のスレッドは、読み取り専用 RDS インスタンスの I/O リソースを消費します。読み取り専用 RDS インスタンスが適切な IOPS を維持するのに十分なリソースを提供できない場合、読み取り専用 RDS インスタンスとプライマリ RDS インスタンス間でデータ同期遅延が発生します。ApsaraDB RDS コンソールにログインし、[監視とアラート] ページで IOPS を表示できます。
原因 2: プライマリ RDS インスタンスの TPS が高い
読み取り専用 RDS インスタンスは、1 つのスレッドを使用してプライマリ RDS インスタンスからデータを同期します。プライマリ RDS インスタンスが同時マルチスレッド書き込みを処理し、プライマリ RDS インスタンスの TPS が著しく高い場合、読み取り専用 RDS インスタンスとプライマリ RDS インスタンス間でデータ同期遅延が発生します。
原因 3: 大規模なトランザクション
大量のデータに対して UPDATE、DELETE、INSERT...SELECT、REPLACE...SELECT などの操作を実行するトランザクションがプライマリ RDS インスタンスで実行されます。大量のログデータが生成され、読み取り専用 RDS インスタンスに送信される必要があります。読み取り専用 RDS インスタンスは、トランザクションを完了するためにプライマリ RDS インスタンスと同じ時間が必要です。これにより、データ同期遅延が発生します。たとえば、プライマリ RDS インスタンスで 80 秒間続く削除操作を実行した場合、読み取り専用 RDS インスタンスでも同じ操作を完了するのに 80 秒かかります。その結果、データ同期遅延が発生します。
複数のテーブルでの同時トランザクションがサポートされています。ただし、テーブル上のトランザクションをレプリケートするために使用できるスレッドは 1 つだけです。これにより、レプリケーション期間が長くなります。
原因 4: プライマリ RDS インスタンスで DDL 文が長時間実行される
読み取り専用 RDS インスタンスとそのプライマリ RDS インスタンス間のデータ同期は、順番に実行されます。大規模なテーブルで DDL 文が長時間実行されたり、プライマリ RDS インスタンスで多くのスロークエリが実行されたりすると、多くの一時テーブルが生成されます。これにより、ストレージが不足し、ディスク I/O が増加し、遅延が発生します。一般的な DDL 文には、CREATE INDEX、REPAIR TABLE、ALTER TABLE ADD COLUMN などがあります。
読み取り専用 RDS インスタンスで実行されるクエリや進行中のトランザクションが、プライマリ RDS インスタンスから同期される DDL 文をブロックします。
特殊なケース
データをレプリケートするために実行される SQL 文に適切なインデックスがありません。その結果、多くの全表スキャンが実行され、論理読み取りの数が大幅に増加します。
テーブルに NULL 値を持つ一意なインデックスしかなく、プライマリキーがない場合、セカンダリ RDS インスタンスがデータをレプリケートするときに、オプティマイザーによって選択された実行計画ではなく、一意なインデックスの実行計画が優先的に使用されます。これは、WHERE 句を使用してクエリ条件を指定した場合でも適用されます。
特定方法
遅延が 1 秒以下の場合は、問題を無視できます。このセクションでは、1 秒を超える遅延の原因を特定する方法について説明します。
読み取り専用インスタンスの仕様が小さすぎる
ApsaraDB RDS コンソールの読み取り専用 RDS インスタンスの [基本情報] ページの [設定情報] セクションで、読み取り専用 RDS インスタンスのインスタンスタイプを表示します。詳細については、「標準読み取り専用 ApsaraDB RDS for MySQL インスタンスのインスタンスタイプ (元の x86 アーキテクチャ)」および「YiTian 読み取り専用 ApsaraDB RDS for MySQL インスタンスのインスタンスタイプ (元の ARM アーキテクチャ)」をご参照ください。
ApsaraDB RDS コンソールの読み取り専用 RDS インスタンスの [監視とアラート] ページで、CPU 使用率、メモリ使用量、I/O 帯域幅、接続数などの監視情報を表示します。次に、監視情報に基づいて、読み取り専用 RDS インスタンスにリソースのボトルネックが存在するかどうかを確認します。
プライマリインスタンスの 1 秒あたりのトランザクション数 (TPS) が高すぎる。
RDS インスタンスの [ダッシュボード] ページで、プライマリまたは読み取り専用 RDS インスタンスの TPS を表示します。詳細については、「ApsaraDB RDS for MySQL インスタンスのダッシュボード機能を使用する」をご参照ください。
大規模なトランザクションの書き込み
大規模なトランザクションが読み取り専用インスタンスに同期され、遅延が発生した場合、データベースにログインして
show slave status \GSQL 文を実行します。`Exec_Master_Log_Pos` パラメーターの値が変更されないままで `Seconds_Behind_Master` パラメーターの値が継続的に変更される場合、読み取り専用インスタンスの SQL スレッドが大規模なトランザクションまたは DDL 操作を実行していることを示します。次のような出力が表示されます: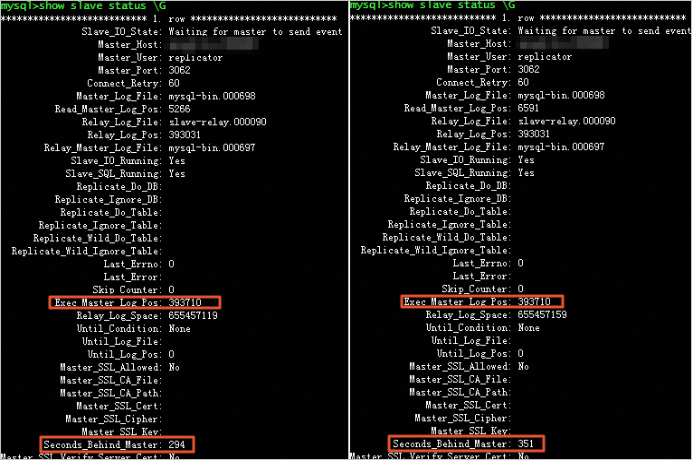
最後に、
show processlist;文を実行して、特定のスレッドを特定します。読み取り専用インスタンスで
show slave status \G文を実行して、メタデータロックが存在するかどうかを判断します。バイナリログのフォーマットが ROW に設定されている場合、大規模なトランザクションは大きなバイナリログファイルになります。
SHOW BINARY LOGS;コマンドを実行して、File_size の値を確認できます。値が `max_binlog_size` パラメーターの値より大きい場合、大規模なトランザクションが存在します。
プライマリインスタンスでの DDL 文の実行時間が長い。
読み取り専用 RDS インスタンスのバイナリログのボリュームをチェックして、DDL 操作が存在するかどうかを判断します。バイナリログファイルがタイムリーに切り捨てられない場合、大きなバイナリログファイルが生成されます。
読み取り専用インスタンスでプライマリキーのないテーブルが削除または更新されているかどうかを確認します。
show engine innodb status \G文を実行して確認するか、show open tables;文を実行し、[in_use] 列の値が 1 であるテーブルの出力を確認します。スロークエリログの情報を表示して、OPTIMIZE、ALTER、REPAIR、CREATE などの DDL 操作が存在するかどうかを確認します。詳細については、「スロークエリログ分析」をご参照ください。
原因 5 の特定方法 (NULL 値を持つ一意なキー)
sys.schema_index_statistics ビューを使用して、テーブルにプライマリキーがなく、一意なインデックスしかないかどうかを確認します。
一意なインデックスに NULL 値が含まれているかどうかを確認します。
ソリューション
インスタンスの設定やデータの変更など、リスクの高い操作を実行する前に、インスタンスのディザスタリカバリとフォールトトレランス機能を確認して、データのセキュリティを確保することをお勧めします。
Elastic Compute Service (ECS) インスタンスや RDS インスタンスなど、インスタンスの設定やデータを変更する前に、スナップショットを作成するか、インスタンスのバックアップ機能を有効にすることをお勧めします。たとえば、RDS インスタンスのログバックアップを有効にできます。
Alibaba Cloud 管理コンソールで機密情報に対する権限を付与した場合、または機密情報を送信した場合は、できるだけ早く機密情報を変更することをお勧めします。機密情報には、ユーザー名とパスワードが含まれます。
このセクションでは、一般的な対処方法について説明します。特定された原因に基づいて、次のいずれかの方法を使用できます。
読み取り専用インスタンスの仕様が小さすぎる
読み取り専用 RDS インスタンスの仕様をアップグレードし、読み取り専用 RDS インスタンスの仕様がプライマリ RDS インスタンスの仕様以上であることを確認することをお勧めします。これにより、読み取り専用 RDS インスタンスの仕様が小さいことによって引き起こされるレプリケーション遅延を防ぎます。詳細については、「ApsaraDB RDS for MySQL インスタンスの仕様を変更する」をご参照ください。
プライマリインスタンスの TPS (1 秒あたりのトランザクション数) が高すぎる。
プライマリ RDS インスタンスの TPS が高い場合は、トランザクションを最適化または分割します。
大規模なトランザクションの書き込み
大規模なトランザクションをより小さなトランザクションに分割します。たとえば、DELETE 文に WHERE 句を追加して、一度に削除できるデータの量を制限し、削除操作をより小さな操作に分割できます。これにより、読み取り専用 RDS インスタンスは遅延なく大規模なトランザクションを迅速に完了できます。
プライマリインスタンスでの DDL 文の実行時間が長すぎる。
読み取り専用 RDS インスタンスのデータ同期遅延が DDL 操作によって引き起こされる場合は、オフピーク時に DDL 操作を実行することをお勧めします。次のいずれかの方法を使用できます。
サービスサポート: 自動ストレージ拡張機能を有効にします。手動ストレージ拡張をトリガーするしきい値を 90% に設定することもできます。詳細については、「ApsaraDB RDS インスタンスをスケーリングする方法」をご参照ください。
SQL 最適化: SQL Explorer を有効にして、SQL 文のパフォーマンスを定期的に確認します。詳細については、「ApsaraDB RDS for MySQL インスタンスで SQL Explorer と監査機能を使用する」をご参照ください。
負荷: ディスク使用率のアラートルールを設定するか、自動ストレージ拡張を設定するか、手動で仕様をアップグレードします。
プライマリ RDS インスタンスから同期された DDL 操作が読み取り専用 RDS インスタンスでブロックされている場合は、次の手順を実行します。
読み取り専用インスタンスで
show processlist;文を実行し、SQL スレッドのステータスが 'waiting for table metadata lock' であることを確認します。kill コマンドを実行して、読み取り専用 RDS インスタンスでブロックを引き起こしたセッションを終了させ、読み取り専用 RDS インスタンスとそのプライマリ RDS インスタンス間のデータ同期を再開します。詳細については、「DMS を使用してメタデータロックを解放する」をご参照ください。
特殊なケース
プライマリキーのないテーブルに明示的なプライマリキーを追加します。
よくある質問
一部の読み取り専用 RDS インスタンスで 1 秒の遅延が発生するのはなぜですか?
読み取り専用 RDS インスタンスの収集プロシージャと起動時間は互いに異なります。一部の読み取り専用 RDS インスタンスのサンプリングポイントが次の秒にまたがる場合、1 秒の遅延が発生します。一部の読み取り専用 RDS インスタンスのサンプリングポイントが次の秒にまたがらない場合、1 秒の遅延は発生しません。詳細については、「1 秒以下の遅延の原因」をご参照ください。
RDS インスタンスで 1 秒の遅延が発生した場合、RDS インスタンスは影響を受けますか?
いいえ、RDS インスタンスは影響を受けません。1 秒の遅延は、RDS インスタンスで実際の遅延が発生したことを示すものではありません。たとえば、実際の遅延が 0.1 秒であっても、サンプリングポイントが次の秒にまたがる場合、1 秒の遅延が報告されます。この場合、1 秒の遅延は、計算精度、計算方法、およびサンプリングポイントによって引き起こされます。詳細については、「1 秒以下の遅延の原因」をご参照ください。
ビジネス要件に基づいて、プロキシの読み取り遅延しきい値を指定するか、アラートをトリガーすることをお勧めします。指定されたしきい値が 1 秒より大きいことを確認してください。
読み取り専用 RDS インスタンスで ReplicationInterrupted エラーメッセージが表示されるか、 Slave_SQL_Running または Slave_IO_Running アラートが報告された場合はどうすればよいですか?
A: 次の 3 つの問題をトラブルシューティングできます。
読み取り専用 RDS インスタンスのストレージ容量が十分かどうかを確認します。
ストレージ容量が不足している場合、読み取り専用 RDS インスタンスはプライマリ RDS インスタンスのバイナリログを同期できません。
説明使用状況 ページの 基本情報 セクションで、読み取り専用 RDS インスタンスのストレージ使用状況を表示できます。
レプリケーション遅延を確認します。
レプリケーション遅延が 5 分以内に継続して 5 秒を超えると、読み取り専用 RDS インスタンスの遅延が高くなり、アラートがトリガーされます。プライマリ RDS インスタンスにデータが頻繁に書き込まれる場合や、プライマリ RDS インスタンスに大規模なトランザクションが存在する場合、データレプリケーションが中断されることがあります。
説明レプリケーション遅延を表示するには、次の操作を実行します: 読み取り専用 RDS インスタンスの 基本情報 ページに移動します。ページの左側のナビゲーションウィンドウで、モニターとアラーム をクリックします。[標準監視] タブで、セカンダリインスタンスのレプリケーション遅延 (秒) メトリックの値を確認します。
スロークエリログを確認します。
スロークエリログはインスタンスのパフォーマンスに大きな影響を与え、レプリケーション遅延を増加させる可能性があります。
説明読み取り専用 RDS インスタンスの 基本情報 ページで、次のいずれかの方法を使用してスロークエリログを確認できます。
左側のナビゲーションウィンドウで、ログ管理 をクリックします。次に、スロークエリログの詳細 タブでスロークエリログを確認します。
左側のナビゲーションウィンドウで、自律型サービス > 低速 SQL を選択して、スロークエリログを確認します。
レプリケーションの中断が前述の原因によるものでない場合は、エラーを無視できます。システムは自動的にインスタンスをチェックし、レプリケーションの中断の問題を解決します。