データテーブルで使用可能な処理を超える処理が必要なデータを分析するには、計算フィールドを作成できます。
前提条件
データセットを作成済みであること。 詳細については、「データセットの作成と管理」をご参照ください。
背景情報
Quick BI は、データ処理効率を高めるためにさまざまな計算方法を提供しています。
集計
たとえば、名前別に顧客数をカウントするには、次のようになります。
COUNT(DISTINCT [顧客名])基本操作
たとえば、顧客 1 人あたりの平均取引金額を計算するには、次のようになります。
[取引金額] / [顧客数]文字の分割とマージ
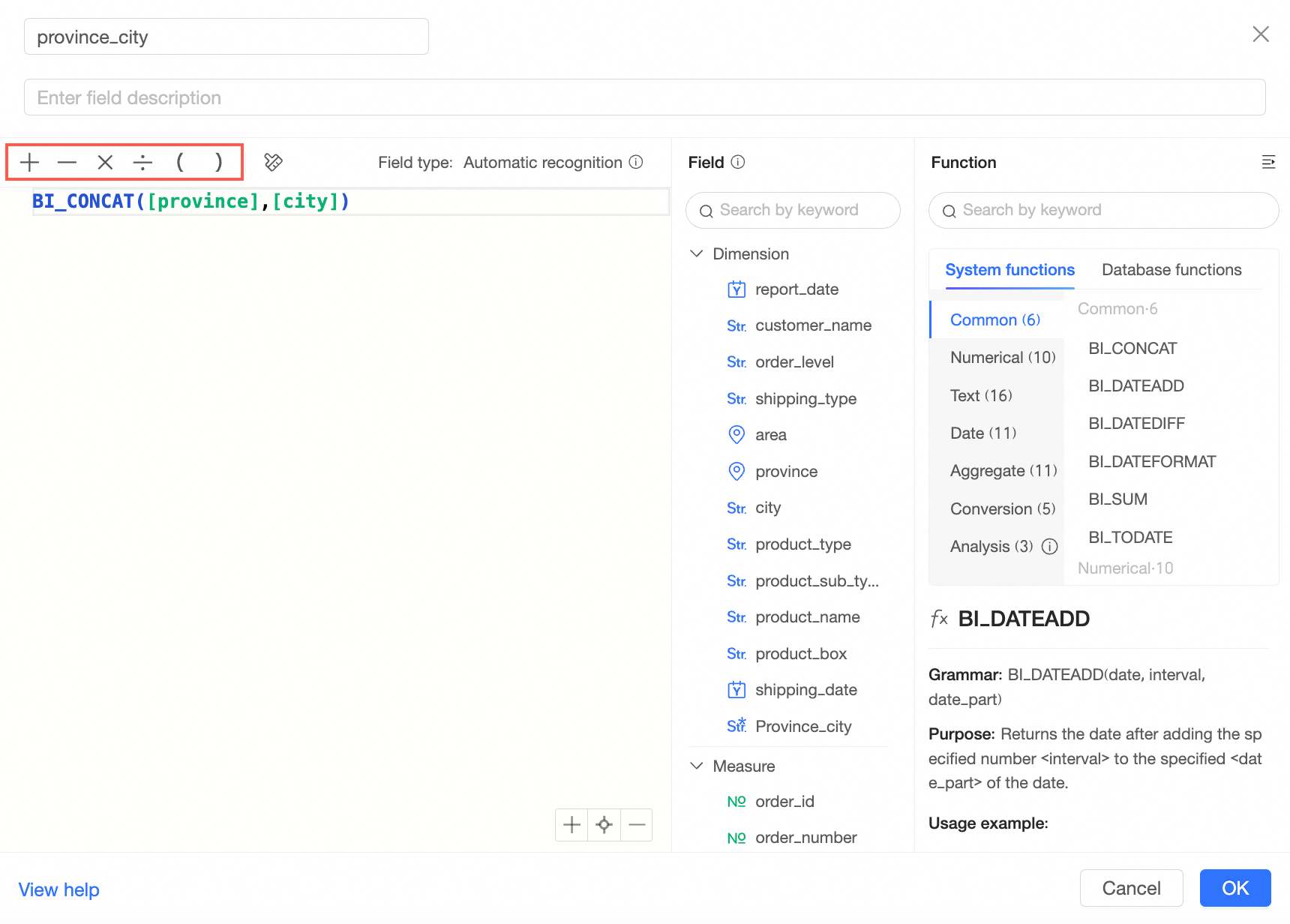
たとえば、都道府県と市を連結するには、次のようになります。
CONCAT([都道府県], [市])複雑なグループ化
たとえば、特定の基準に基づいて VIP 顧客を定義するには、次のようになります。
CASE WHEN [取引金額] > 1000 AND [取引回数] > 5 THEN 'VIP' ELSE '通常' END
設定方法
データ処理ページで、[計算フィールドの作成] をクリックします。
フィールド アウトラインまたはデータ プレビュー インターフェイスでターゲット フィールドにマウスを移動し、
 アイコンをクリックして、[作成]->[計算フィールドの作成] を選択することもできます。
アイコンをクリックして、[作成]->[計算フィールドの作成] を選択することもできます。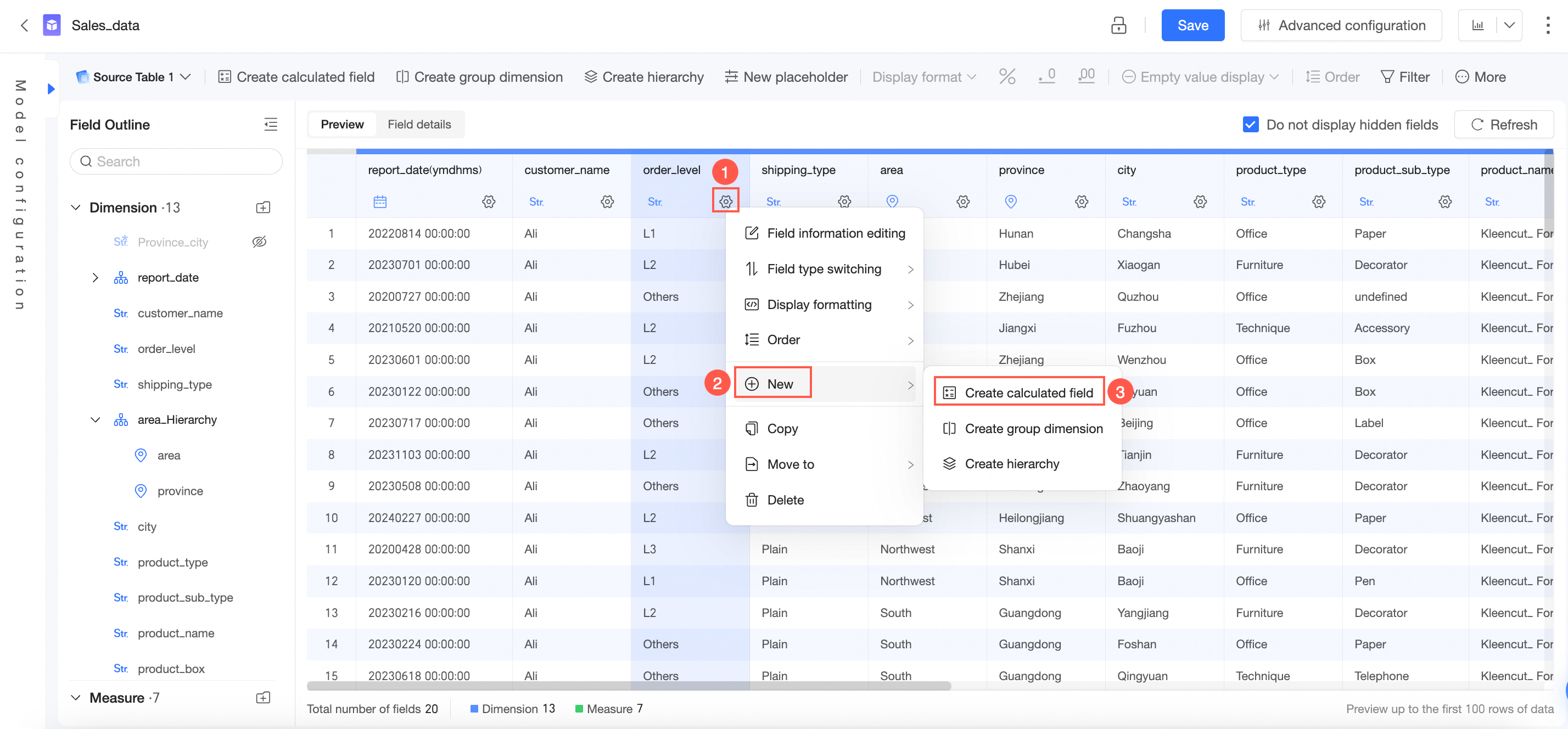
[計算フィールドの作成] ページで、パラメーターを設定し、[OK] をクリックします。
フィールド名を入力します。
(オプション) [フィールドの説明] を入力します。

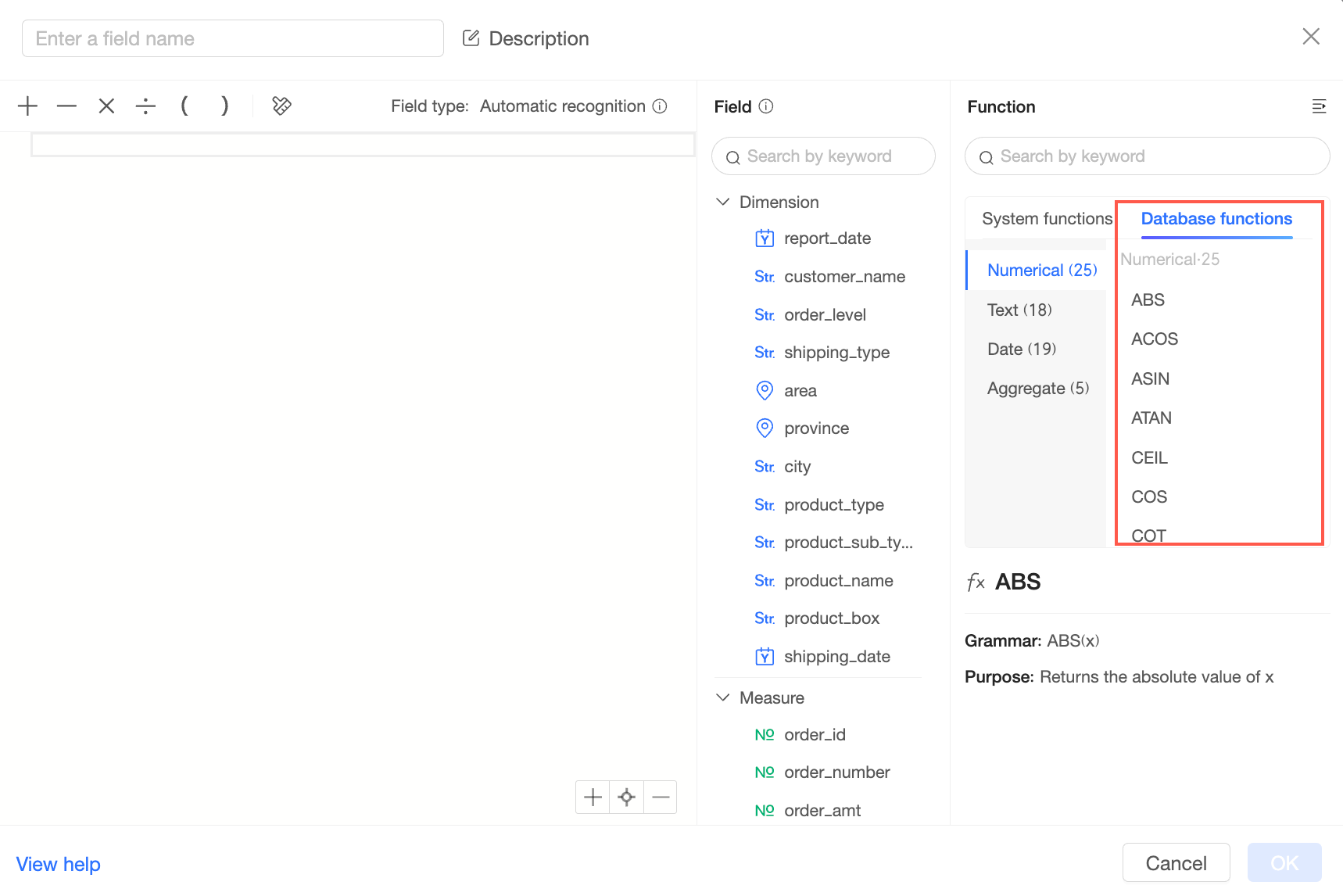
[参照関数] と [参照フィールド] をクリックして、フィールド式を編集します。 参照関数は、[システム組み込み関数] と [データベース関数] に分類されます。
[システム組み込み関数]: これらは BI システムに組み込まれている計算関数であり、基盤となるデータベース間の違いをマスクし、さまざまなデータベース タイプに適用できます。
システム組み込み関数の詳細については、「システム組み込み関数」をご参照ください。
[データベース関数]: これらは、基盤となるデータベースによって提供されるネイティブ関数です。 データベースによって、提供されるネイティブ関数は異なります。 例:
MySQL データソースに表示されるデータベース関数:
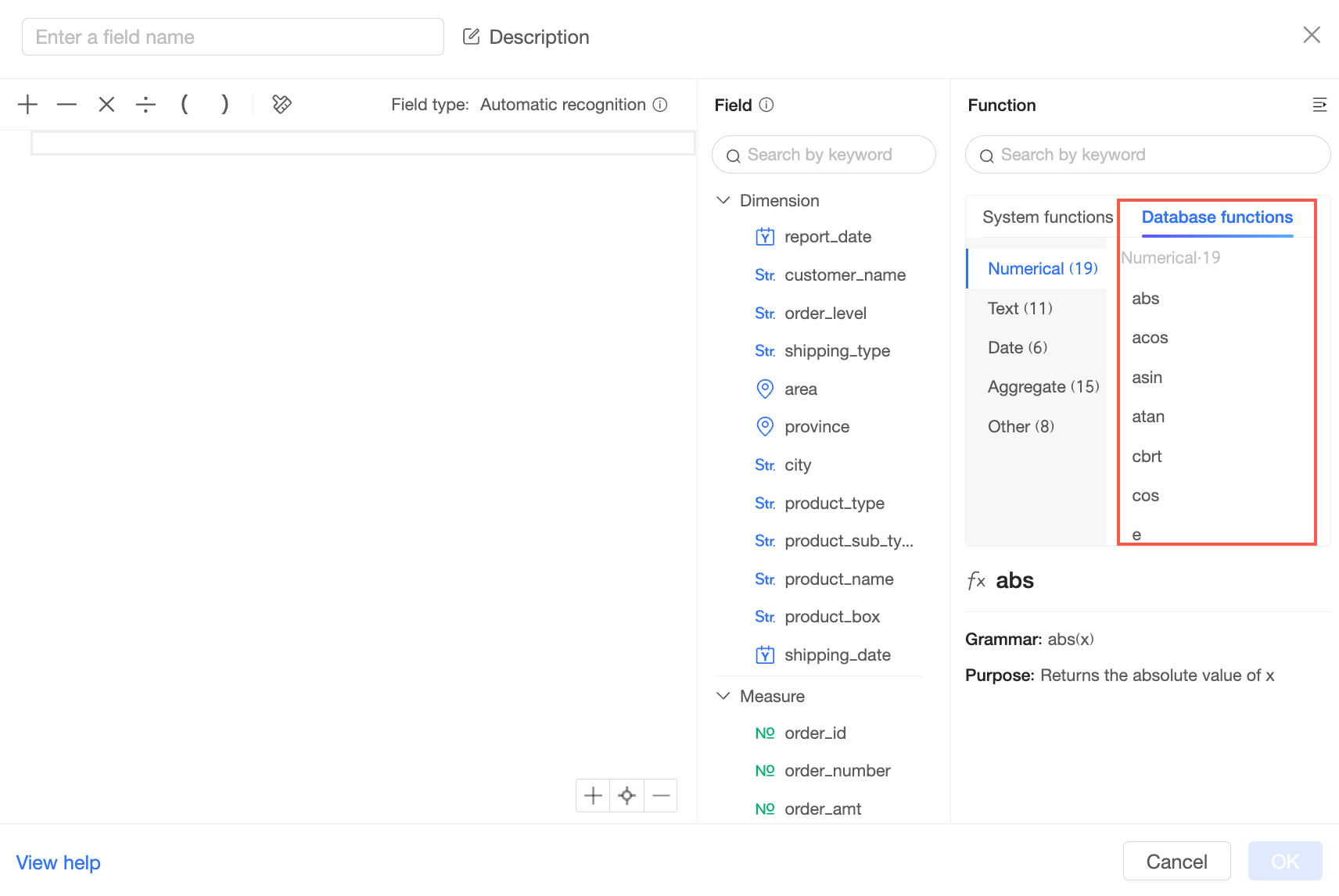
Exploration Space に表示されるデータベース関数は Clickhouse 関数です。
式を編集する場合は、次の点を考慮してください。
式エディターに
[と入力すると、リストが表示され、メジャー フィールド名を挿入できます。クイック計算演算子をクリックして直接参照します。
 アイコンをクリックして式をクリアします。
アイコンをクリックして式をクリアします。
一般的なフィールド式の例については、「シナリオ例」をご参照ください。
[OK] をクリックします。
新しく作成された計算フィールドは、複雑な計算シナリオに対応するために、さらなる計算で直接参照できます。
たとえば、
利益額 = 注文額 - コスト額、利益率 = 利益額 / 注文額などです。
シナリオ例
集約関数
合計:
SUM([フィールド])カウント:
COUNT([フィールド])重複を除くカウント:
COUNT(DISTINCT [Field])平均:
AVG([フィールド])
Quick BI は、集計用に構成された計算フィールドについて、ダッシュボードのディメンションデータを自動的に集計します。
基本操作
加算、減算、乗算、除算がサポートされています。
たとえば、注文詳細テーブルから顧客 1 人あたりの平均取引金額を計算するには、次のようになります。
SUM([取引金額]) / COUNT(DISTINCT [顧客名])
複雑なグループ化シナリオ
ディメンション グループ化を含むシナリオの場合、[グループ ディメンション] 機能は、単純な単一フィールドのグループ化をサポートしています。 複数のフィールドの組み合わせ条件の場合は、
CASE WHEN関数を使用します。 例:CASE WHEN [成交金额]>5000 AND [成交笔数]>40 THEN 'VVIP' WHEN [成交金额]>1000 AND [成交笔数]>5 THEN 'VIP' ELSE '普通' END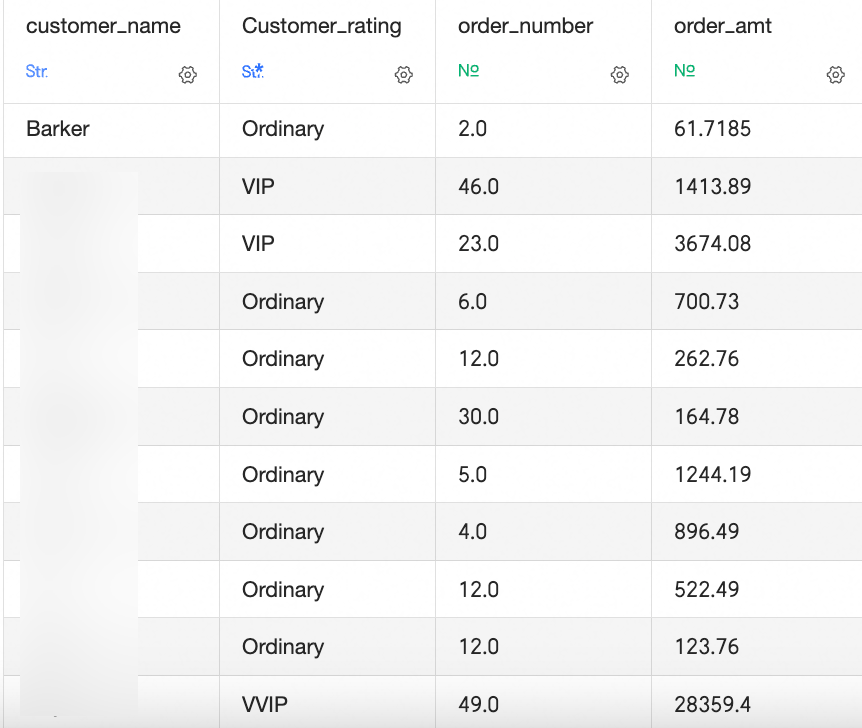
文字列の連結
都道府県や市などのフィールドをマージするには、CONCAT 関数を使用します。
CONCAT(a, b, c, d): マージするフィールドを括弧で囲み、コンマで区切ります。 文字列をマージするときに列の間にデリミタを追加するには、デリミタを単一引用符で囲みます。たとえば、
CONCAT([Province],'-',[City])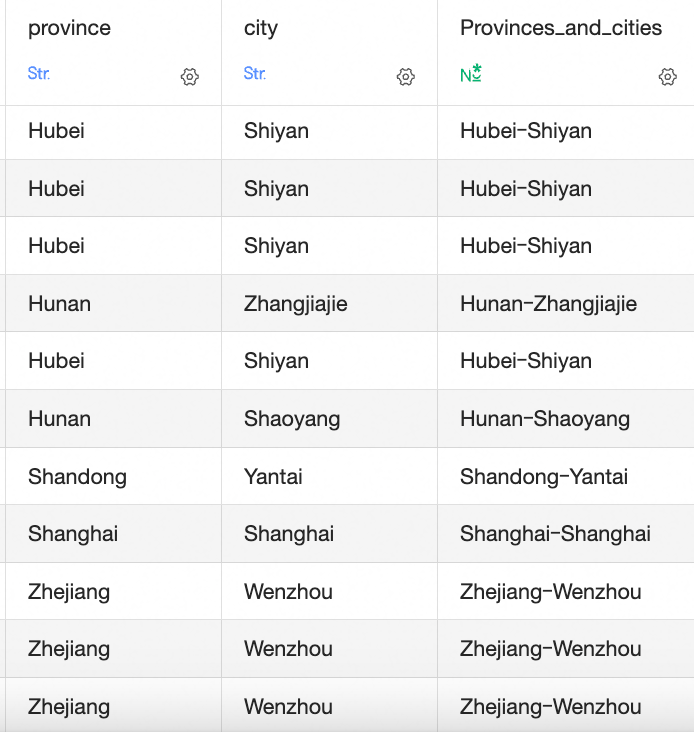
文字列処理
文字列関数を使用すると、テキスト データを操作できます。
メソッドはデータベース関数によって異なります。 ここでは、MySQL 関数を例として使用します。
文字列を切り捨てるには、次のようになります。
SUBSTRING([Customer Name],1,1): [Customer Name] フィールドの最初の文字から 1 文字を取得します。SUBSTRING([Field]): 切り捨てる文字列の開始位置と長さを指定します。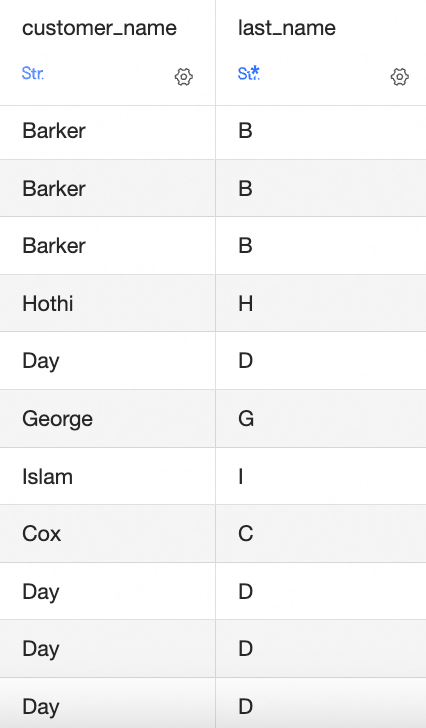
文字列内の部分文字列の位置を見つけるには、次のようになります。
INSTR([Customer Name],'东'): この関数は、[顧客名] フィールドに文字‘东’が含まれているかどうかを確認します。 見つかった場合は文字の位置を返し、見つからない場合は 0 を返します。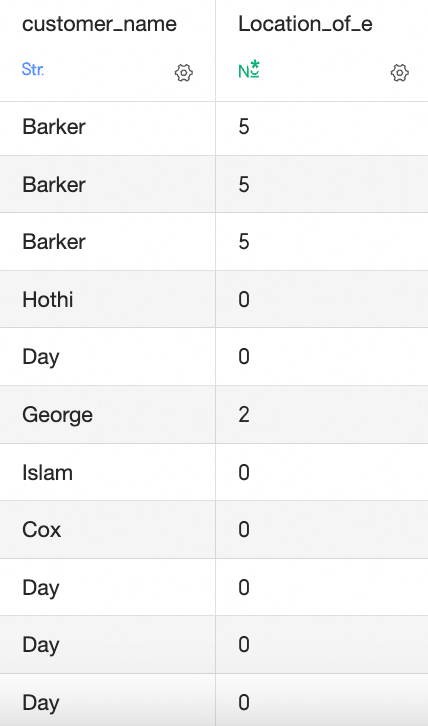
日付と時刻の処理
Quick BI は、日付と時刻のフィールドをさまざまな時間粒度に自動的に分割するため、さまざまなビジネス要件に合わせてさまざまな粒度の表示形式を指定できます。
さらに、データベースの日付関連関数を使用して、さらに処理を行うことができます。 たとえば、関数リストの検索ボックスに DATE と入力して、関連する関数を検索します。
日付と時刻の処理方法は、データベース関数によって異なります。 ここでは、MySQL 関数を例として使用します。
現在の日付:
CURRENT_DATE参加してからの日数:
DATEDIFF(CURRENT_DATE, [Start Date])。開始日から現在の日付までの日数を計算します。有効期限:
ADDDATE([Payment Date], 365)。支払日から 365 日後の日付を返します。
LOD 関数の詳細レベルの計算
既存の可視化とは異なる詳細レベルのディメンションを分析に含める必要がある場合、かつ現在の表示を維持したい場合は、詳細レベル式機能を使用できます。 例:
地域ごとの総売上高を計算するには、次のようになります。
lod_fixed{[Region]:SUM([Order Amount])}
顧客の再購入行動を分析するには、次のようになります。
lod_fixed{[User ID]:count(distinct([Order ID]))}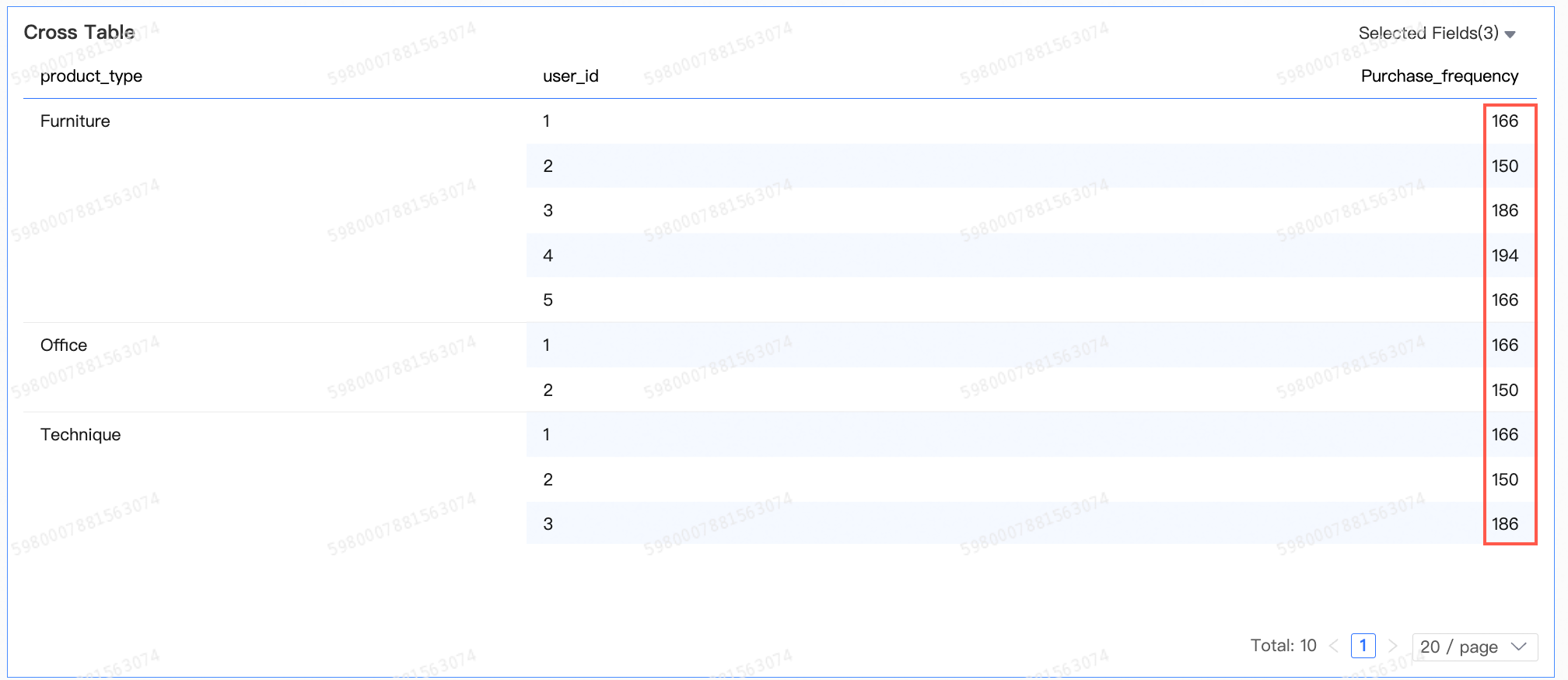
詳細については、「分析関数 (LOD 関数)」をご参照ください。