大規模言語モデル (LLM) アプリケーションでは、従来のロードバランシングポリシーでは不十分な場合があります。リクエストと応答の長さの変動、ランダムなトークン生成、予測不可能な GPU リソース使用量により、バックエンドの負荷をリアルタイムで評価することが困難です。これにより、インスタンス間で負荷の不均衡が生じ、システムスループットと応答効率が低下します。Elastic Algorithm Service (EAS) は、LLM 固有のメトリックを使用してリクエストを動的に分散する LLM インテリジェントルーターコンポーネントを導入しています。これにより、推論インスタンス全体で計算能力と VRAM 割り当てのバランスが取れ、クラスターリソース利用率とシステム安定性が向上します。
仕組み
アーキテクチャの概要
LLM インテリジェントルーターは、LLM Gateway、LLM Scheduler、および LLM Agent の 3 つのコアコンポーネントで構成されています。これらが連携して、バックエンド LLM 推論インスタンスクラスターにインテリジェントなトラフィック分散と管理を提供します。
LLM インテリジェントルーターは、EAS の特殊なサービスです。正しく機能させるには、推論サービスと同じサービスグループにデプロイする必要があります。

コアプロセスは次のとおりです。
インスタンス登録: 推論サービスが起動した後、
LLM Agentは推論エンジンが準備完了になるのを待機します。その後、インスタンスをLLM Schedulerに登録し、定期的にヘルスステータスとパフォーマンスメトリックの報告を開始します。トラフィックイングレス: ユーザーリクエストは最初に
LLM Gatewayに到達します。スケジューリング決定:
LLM GatewayはLLM Schedulerにスケジューリングリクエストを送信します。インテリジェントスケジューリング:
LLM Schedulerは、スケジューリングポリシーと、各LLM Agentから収集されたリアルタイムメトリックに基づいて、最適なターゲットインスタンスを選択します。リクエスト転送:
LLM Schedulerはその決定をLLM Gatewayに返します。LLM Gatewayは、元のユーザーリクエストをターゲットインスタンスに転送します。リクエストバッファリング: すべてのバックエンドインスタンスが高負荷の場合、新しいリクエストは一時的に
LLM Gatewayキューにバッファリングされます。リクエストは、LLM Schedulerがそれらを転送する適切な時間を特定するまで待機し、リクエストの失敗を防ぎます。
コアコンポーネント
コンポーネント | 主な役割 |
LLM Gateway | トラフィックのエントリポイントおよびリクエスト処理センター。すべてのユーザーリクエストを受信し、
|
LLM Scheduler | インテリジェントスケジューリングの頭脳。すべての |
LLM Agent | 推論インスタンスとともにデプロイされるプローブ。各推論インスタンスとともにサイドカーコンテナーとしてデプロイされます。推論エンジンからパフォーマンスメトリックを収集し、 |
フェイルオーバーメカニズム
システムには、サービス安定性を確保するための多層フォールトトレランスメカニズムが含まれています。
LLM Gateway (高可用性): ステートレスなトラフィックイングレスレイヤーとして、少なくとも 2 つのインスタンスをデプロイします。インスタンスが失敗した場合、トラフィックは自動的に他の正常なインスタンスに切り替わり、継続的なサービス可用性を維持します。
LLM Scheduler (グレースフルデグラデーション): リクエストスケジューリングコンポーネントとして、グローバルスケジューリングを可能にするために単一インスタンスとして実行されます。
LLM Schedulerが失敗した場合、LLM Gatewayはハートビート障害後に自動的にグレースフルデグラデーションし、ポーリングポリシーを使用してリクエストをバックエンドインスタンスに直接転送します。これにより、サービス可用性は確保されますが、スケジューリングパフォーマンスは低下します。LLM Schedulerが回復すると、LLM Gatewayは自動的にインテリジェントスケジューリングを再開します。推論インスタンスまたは LLM Agent (自動削除): 推論インスタンスまたはそれに関連付けられた
LLM Agentが失敗した場合、LLM AgentとLLM Scheduler間のハートビートが中断されます。LLM Schedulerは、利用可能なサービスリストからインスタンスを直ちに削除し、新しいトラフィックの割り当てを停止します。インスタンスが回復してハートビートの報告を再開すると、自動的にサービスリストに再参加します。
複数の推論エンジンのサポート
/metrics エンドポイントによって返されるメトリックは、LLM 推論エンジンによって異なります。LLM Agent はこれらのメトリックを収集し、均一にフォーマットして報告します。LLM Scheduler は特定の推論エンジンの実装の詳細を知る必要はありません。統一されたメトリックに基づいてスケジューリングアルゴリズムを実装するだけで済みます。サポートされている LLM 推論エンジンとそれに対応するメトリックは次のとおりです。
LLM 推論エンジン | メトリック | 説明 |
vLLM | vllm:num_requests_running | 実行中のリクエスト数。 |
vllm:num_requests_waiting | キューで待機中のリクエスト数。 | |
vllm:gpu_cache_usage_perc | GPU KV Cache の使用方法。 | |
vllm:prompt_tokens_total | プロンプトトークンの総数。 | |
vllm:generation_tokens_total | 生成されたトークンの総数。 | |
SGLang | sglang:num_running_reqs | 実行中のリクエスト数。 |
sglang:num_queue_reqs | キューで待機中のリクエスト数。 | |
sglang:token_usage | KV キャッシュの使用率。 | |
sglang:prompt_tokens_total | プロンプトトークンの総数。 | |
sglang:gen_throughput | 1 秒あたりに生成されるトークン数。 |
制限事項
更新中に追加できません: LLM インテリジェントルーターは、新しいサービスを作成する際にのみ構成できます。既存の推論サービスを更新する際に、追加することはできません。
推論エンジンの制限: 現在、vLLM と SGLang のみがサポートされています。
複数の推論インスタンスのデプロイを推奨: LLM インテリジェントルーターは、複数の推論インスタンスがデプロイされている場合に最大の価値を発揮します。
クイックスタート: LLM インテリジェントルーターの使用
ステップ 1: LLM インテリジェントルーターサービスをデプロイする
PAI コンソール にログインし、ページ上部でターゲットリージョンを選択します。
左側のナビゲーションウィンドウで、Elastic Algorithm Service (EAS) をクリックします。目的のワークスペースを選択して、EAS ページに移動します。
[Deploy Service] をクリックし、[Scenario-based Model Deployment] > [Deploy LLM gateway] を選択します。
パラメーターを構成します。
パラメーター
説明
Basic Information
Service Name
カスタムサービス名 (例:
llm_gateway) を入力します。Resource Information
Deployment Resources
LLM Gatewayのリソース構成。高可用性を確保するため、Number of Replicas はデフォルトで 2 です。この値を維持することを推奨します。デフォルトの CPU は 4 コア、デフォルトの Memory は 8 GB です。Scheduling configuration
LLM Schedulerのリソース構成。デフォルトの CPU は 2 コア、デフォルトの Memory は 4 GB です。Scheduling Policy
バックエンド推論インスタンスのロードバランシングポリシーを選択します。デフォルトは Prefix cache です。詳細な比較および選択に関する推奨事項については、「スケジューリングポリシーの説明」をご参照ください。
[Deploy] をクリックします。サービスのステータスが [Running] に変わると、デプロイが成功します。
デプロイメントが成功すると、システムは自動的に group_<LLM_intelligent_router_service_name> という名前のサービスグループを作成します。Elastic Algorithm Service (EAS) ページに移動し、Canary Release タブをクリックして確認できます。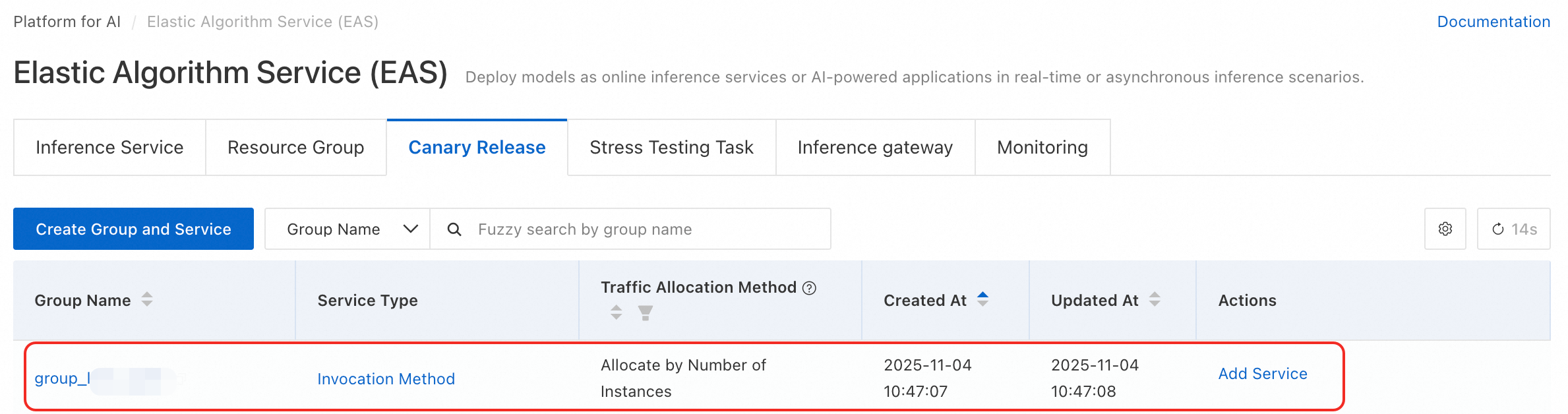
インテリジェントルーターとサービスキューは互いに競合します。同じサービスグループに共存することはできません。
ステップ 2: LLM サービスをデプロイする
新しい LLM サービスをデプロイする際に、インテリジェントルーター機能を構成する必要があります。既存の LLM サービスを更新する際に、追加することはできません。
以下の手順では、Qwen3-8B のデプロイを例として使用します。
[Deploy Service] をクリックし、[Scenario-based Model Deployment] > [LLM Deployment] を選択します。
以下の主要なパラメーターを構成します。
パラメーター
値
Basic Information
Model Settings
[Public Model]を選択します。次に、Qwen3-8B を検索して選択します。
Inference Engine
vLLM を選択します (推奨、OpenAI API と互換性があります)。
説明LLM インテリジェントルーターサービスで Prefix cache スケジューリングポリシーを選択し、LLM サービスのデプロイ時に推論エンジンとして vLLM を選択した場合は、エンジンのプレフィックスキャッシュ機能を必ず有効にしてください。
Deployment Template
[Standalone] を選択します。システムは、テンプレートに基づいて推奨されるインスタンスタイプ、イメージ、およびその他のパラメーターを自動的に入力します。
Features
LLM Intelligent Router
スイッチをオンにし、ドロップダウンリストからステップ 1 でデプロイした LLM インテリジェントルーターサービスを選択します。
「Deploy」をクリックします。サービスデプロイには約5分かかります。サービスのステータスが「Running」に変更されたら、デプロイが完了します。
ステップ 3: サービスをテストする
すべてのリクエストは、バックエンド推論サービスではなく、LLM インテリジェントルーターサービスのエンドポイントに送信してください。
アクセス認証情報を取得する。
LLM インテリジェントルーターサービスをクリックして、Overview ページに移動します。 Basic Information セクションで、View Endpoint Information をクリックします。
[エンドポイント情報] ページで、Service-specific Traffic Entry の下にある Internet Endpoint と [トークン] をコピーします。
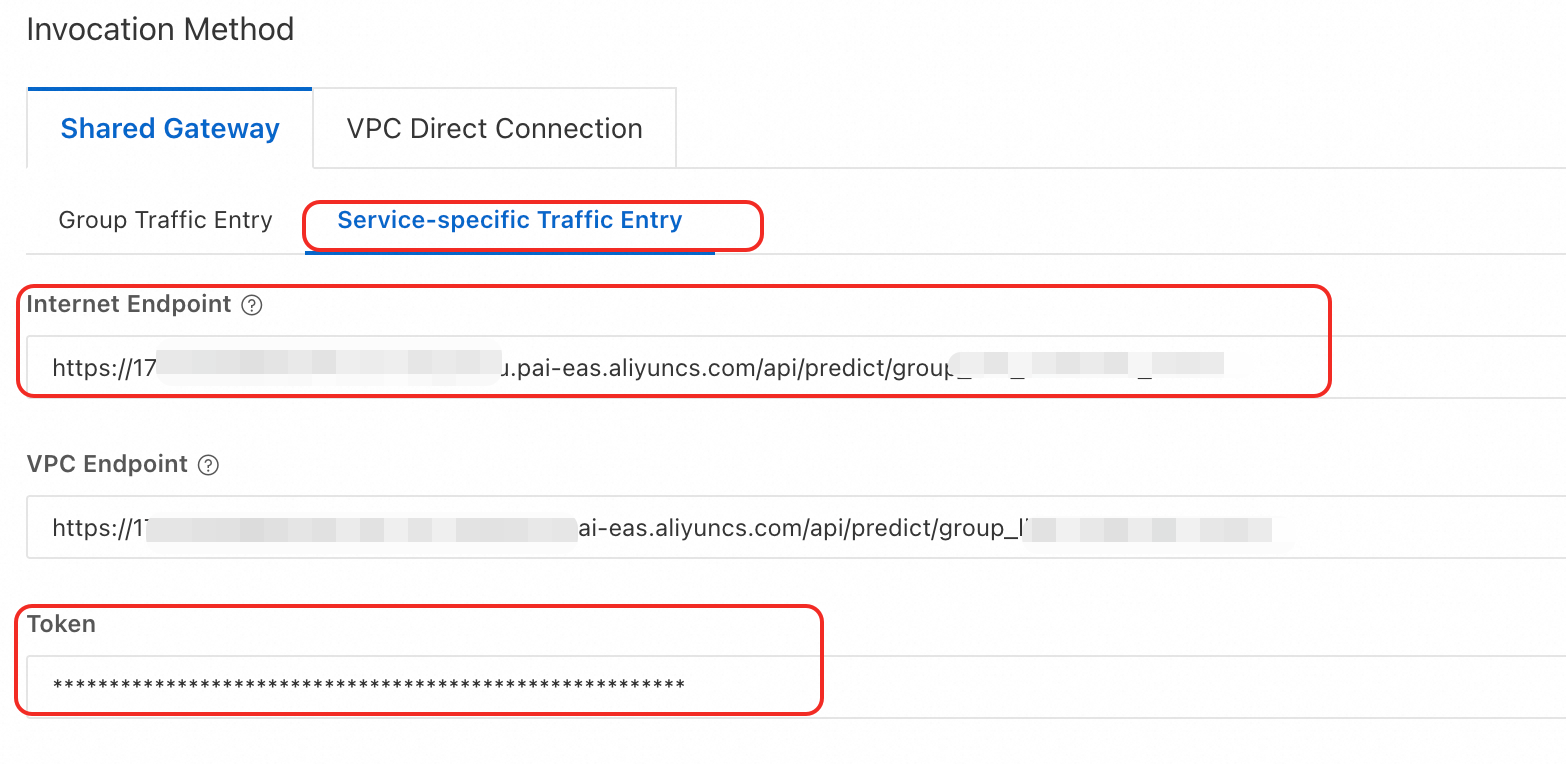
リクエスト URL を構築して呼び出す。
URL 構造:
<LLM_intelligent_router_endpoint>/<LLM_service_API_path>例:
http://********.pai-eas.aliyuncs.com/api/predict/group_llm_gateway.llm_gateway/v1/chat/completions
リクエスト例:
# <YOUR_GATEWAY_URL> と <YOUR_TOKEN> を実際の情報に置き換えてください。 curl -X POST "<YOUR_GATEWAY_URL>/v1/chat/completions" \ -H "Authorization: Bearer <YOUR_TOKEN>" \ -H "Content-Type: application/json" \ -N \ -d '{ "messages": [{"role": "user", "content": "Hello"}], "stream": true }'応答の例:
data: {"id":"chatcmpl-9a9f8299*****","object":"chat.completion.chunk","created":1762245102,"model":"Qwen3-8B","choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":null}]} data: {"id":"chatcmpl-9a9f8299*****","object":"chat.completion.chunk","created":1762245102,"model":"Qwen3-8B","choices":[{"index":0,"delta":{"content":"<think>","tool_calls":[]}}]} ... data: [DONE]
高度な構成
JSON ベースの独立したデプロイメントは、より柔軟な構成オプションを提供します。LLM Gateway のリソース仕様を指定し、そのリクエスト処理動作を微調整できます。
設定のエントリポイント: Inference Service ページで、Deploy Service をクリックします。Custom Model Deployment セクションで、JSON Deployment をクリックします。
構成例:
{ "cloud": { "computing": { "instance_type": "ecs.c7.large" } }, "llm_gateway": { "max_queue_size": 128, "retry_count": 2, "wait_schedule_timeout": 5000, "wait_schedule_try_period": 500 }, "llm_scheduler": { "cpu": 2, "memory": 4000, "policy": "prefix-cache" }, "metadata": { "group": "group_llm_gateway", "instance": 2, "name": "llm_gateway", "type": "LLMGatewayService" } }パラメーターの説明:
パラメーター
説明
metadata
type
必須。
LLMGatewayServiceに設定する必要があります。これは、LLM インテリジェントルーターサービスをデプロイしていることを示します。instance
必須。
LLM Gatewayのレプリカ数。単一障害点を防ぐため、少なくとも 2 に設定することを推奨します。cpu
各
LLM Gatewayレプリカの CPU コア数。memory
LLM Gatewayのメモリ (GB)。group
LLM インテリジェントルーターサービスが属するサービスグループ。
cloud.computing.instance_type
LLM Gatewayのリソース仕様を指定します。このパラメーターを設定した場合、metadata.cpuとmetadata.memoryを構成する必要はありません。llm_gateway
max_queue_size
LLM Gatewayキャッシュキューの最大長。デフォルトは 512 です。バックエンド推論フレームワークの処理能力を超過するリクエストは、このキューにキャッシュされ、スケジューリングを待機します。
retry_count
リトライ回数。デフォルトは 2 です。バックエンド推論インスタンスが失敗した場合、リクエストはリトライされ、新しいインスタンスに転送されます。
wait_schedule_timeout
バックエンドエンジンがフルキャパシティの場合、リクエストは間隔を置いてスケジュールされます。このパラメーターは、スケジューリング試行時間を指定します。デフォルトは 10 秒です。
wait_schedule_try_period
各スケジューリング試行間の間隔。デフォルトは 1 秒です。
llm_scheduler
cpu
LLM Schedulerの CPU コア数。デフォルトは 4 です。memory
LLM Schedulerのメモリ (GB)。デフォルトは 4 GB です。policy
スケジューリングポリシー。デフォルト値は
prefix-cacheです。オプション値と説明については、「スケジューリングポリシーの説明」をご参照ください。prefill_policy
ポリシーを pd-split に設定した場合、Prefill および Decode ステージのスケジューリングポリシーを個別に指定する必要があります。有効な値: prefix-cache、llm-metric-based、least-request、および least-token。
decode_policy
スケジューリングポリシーの説明
適切なスケジューリングポリシーを選択することは、LLM インテリジェントルーターの価値を最大化する鍵です。次の表は、最適な決定を下すのに役立つように、各ポリシーのロジック、シナリオ、利点、および欠点を比較しています。
ポリシー名 | JSON 値 | コアロジック | シナリオ | 利点 | 備考 |
Prefix cache | prefix-cache | (推奨) 同じ履歴コンテキスト (プロンプト) を持つリクエストを、すでに KV キャッシュをキャッシュしているインスタンスに送信することを優先する包括的なポリシー。 | マルチターン対話ボットや、固定システムプロンプトを持つ検索拡張生成 (RAG) システム。 | 最初のトークンまでの時間 (TTFT) を大幅に削減し、マルチターン対話のパフォーマンスとスループットを向上させます。 | 推論エンジンでプレフィックスキャッシュが有効になっている必要があります。 |
LLM Metrics | llm-metric-based | キューに入っているリクエスト数、実行中のリクエスト、KV キャッシュ使用率など、バックエンドインスタンスの包括的な負荷メトリックに基づいてインテリジェントスケジューリングを実行します。 | 多様なリクエストパターンを持ち、明確な対話機能がない一般的な LLM ワークロード。 | 異なるインスタンス間で効果的に負荷を分散し、リソース利用率を向上させます。 | スケジューリングロジックは比較的複雑であり、特定のシナリオではプレフィックスキャッシュベースのポリシーほど効果的ではない可能性があります。 |
Minimum Requests | least-request | 現在処理中のリクエストが最も少ないインスタンスに新しいリクエストを送信します。 | リクエストの計算の複雑さ (トークン長、生成長) が比較的均一なシナリオ。 | シンプルで効率的。インスタンス間のリクエスト数を迅速に分散できます。 | リクエストの実際の負荷を認識できない。これにより、短いリクエストのインスタンスがアイドル状態になり、長いリクエストのインスタンスが過負荷になる可能性があります。 |
Minimum tokens | least-token | 現在処理中の合計トークン数 (入力 + 出力) が最も少ないインスタンスに新しいリクエストを送信します。 | トークン数がリクエスト処理コストを正確に反映するシナリオ。 | 「最小リクエスト」ポリシーよりもインスタンスの真の負荷をより正確に反映します。 | トークン数の推定に依存しており、すべてのエンジンがこのメトリックを報告するわけではありません。 |
Static PD Disaggregation | pd-split | インスタンスを Prefill および Decode グループに事前に分割し、各グループのスケジューリングポリシーを指定する必要があります。 | Prefill および Decode ステージの計算およびメモリアクセス特性が大きく異なり、個別のデプロイメントが大きなメリットをもたらすシナリオ。 | ハードウェア利用率の最大化のための究極の最適化。 | 複雑な構成。モデルとビジネスロジックの深い理解、および Prefill と Decode サービスの独立したデプロイメントが必要です。 |
Dynamic PD Disaggregation | dynamic-pd-split | インスタンスに事前に割り当てられたロールは不要です。スケジューラは、リアルタイムの負荷に基づいて、リクエストの Prefill または Decode ステージを最適なインスタンスに動的にディスパッチします。 | 上記と同じですが、動的に変化する負荷のシナリオに適しています。 | 静的分割よりも柔軟で、負荷の変化に適応できます。 | より複雑な構成。スケジューラとエンジンにより高い要求を課します。 |
サービス監視メトリックの表示
サービスをデプロイした後、EAS コンソールでそのコアパフォーマンスメトリックを表示して、インテリジェントルーターの有効性を評価できます。
[Elastic Algorithm Service (EAS)] ページで、デプロイされた LLM インテリジェントルーターサービスをクリックして、サービス詳細ページに移動します。Monitoring タブで、次のコアメトリックに注目します。
トークンスループット LLM 入力および出力トークンのスループット
| GPU キャッシュ使用率 LLM エンジン GPU KV キャッシュの使用率
|
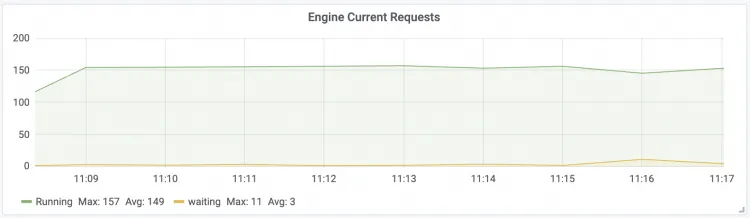
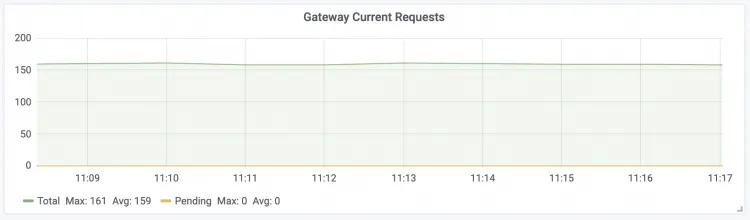
エンジン現在のリクエスト LLM エンジンのリアルタイム同時リクエスト
| Gateway 現在のリクエスト LLM インテリジェントルーターのリアルタイムリクエスト
|
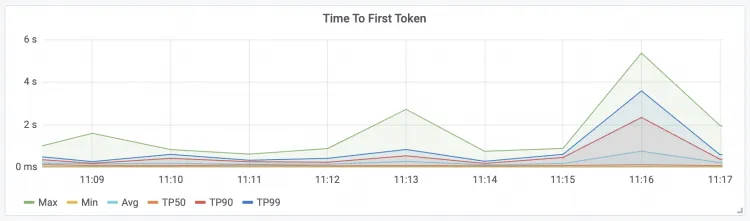
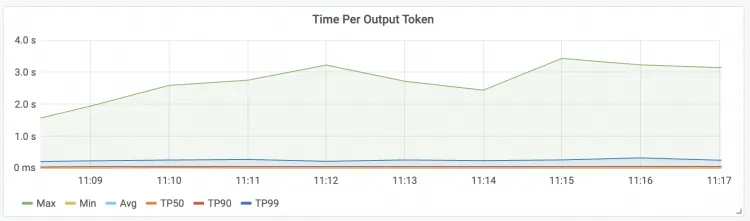
最初のトークンまでの時間 リクエストの最初のトークンまでの時間
| 出力トークンあたりの時間 パケットあたりのリクエストレイテンシー
|
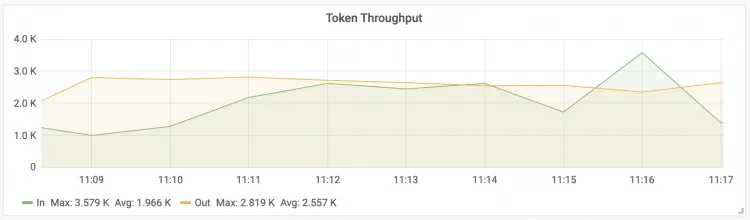
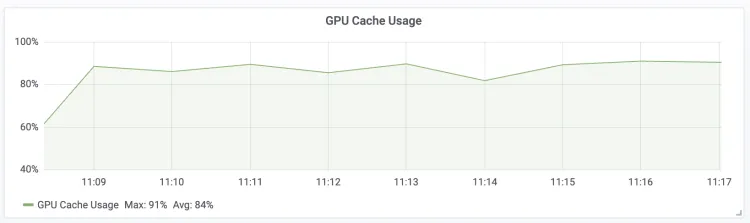
付録: Claude Code を使用して呼び出しを行う
EAS インテリジェントルーターサービスによって提供される BASE URL と TOKEN を使用するように Claude Code を構成します。
# <YOUR_GATEWAY_URL> と <YOUR_TOKEN> を実際の情報に置き換えてください。 export ANTHROPIC_BASE_URL=<YOUR_GATEWAY_URL> export ANTHROPIC_AUTH_TOKEN=<YOUR_TOKEN>Claude Code ツールを直接実行します。
claude "Write a Hello World program in Python"
付録: パフォーマンス比較テスト
Distill-Qwen-7B、QwQ-32B、および Qwen2.5-72B モデルでのテストでは、LLM インテリジェントルーターが推論サービスの速度とスループットを大幅に向上させることが示されています。テスト環境とテスト結果は次のとおりです。
以下のテスト結果は参考用です。実際のパフォーマンスはテストによって異なる場合があります。
テスト環境
スケジューリングポリシー: prefix-cache
テストデータ: ShareGPT_V3_unfiltered_cleaned_split.json (マルチターン対話データセット)
推論エンジン: vLLM (0.7.3)
バックエンドインスタンス数: 5
テスト結果
テストモデル | Distill-Qwen-7B | QwQ-32B | Qwen2.5-72b | ||||||
カードタイプ | ml.gu8tf.8.40xlarge | ml.gu8tf.8.40xlarge | ml.gu7xf.8xlarge-gu108 | ||||||
同時実行性 | 500 | 100 | 100 | ||||||
メトリック | LLM インテリジェントルーターなし | LLM インテリジェントルーターを使用 | 改善 | LLM インテリジェントルーターなし | LLM インテリジェントルーターを使用 | 改善 | LLM インテリジェントルーターなし | LLM インテリジェントルーターを使用 | 改善 |
成功したリクエスト | 3698 | 3612 | - | 1194 | 1194 | - | 1194 | 1194 | - |
ベンチマーク期間 | 460.79 s | 435.70 s | - | 1418.54 s | 1339.04 s | - | 479.53 s | 456.69 s | - |
総入力トークン数 | 6605953 | 6426637 | - | 2646701 | 2645010 | - | 1336301 | 1337015 | - |
総生成トークン数 | 4898730 | 4750113 | - | 1908956 | 1902894 | - | 924856 | 925208 | - |
リクエストスループット | 8.03 req/s | 8.29 req/s | +3.2% | 0.84 req/s | 0.89 req/s | +5.95% | 2.49 req/s | 2.61 req/s | +4.8% |
出力トークンスループット | 10631.17 tok/s | 10902.30 tok/s | +2.5% | 1345.72 tok/s | 1421.08 tok/s | +5.6% | 1928.66 tok/s | 2025.92 tok/s | +5.0% |
総トークンスループット | 24967.33 tok/s | 25652.51 tok/s | +2.7% | 3211.52 tok/s | 3396.38 tok/s | +5.8% | 4715.34 tok/s | 4953.56 tok/s | +5.0% |
平均 TTFT | 532.79 ms | 508.90 ms | +4.5% | 1144.62 ms | 859.42 ms | +25.0% | 508.55 ms | 389.66 ms | +23.4% |
中央値 TTFT | 274.23 ms | 246.30 ms | - | 749.39 ms | 565.61 ms | - | 325.33 ms | 190.04 ms | - |
P99 TTFT | 3841.49 ms | 3526.62 ms | - | 5339.61 ms | 5027.39 ms | - | 2802.26 ms | 2678.70 ms | - |
平均 TPOT | 40.65 ms | 39.20 ms | +3.5% | 68.78 ms | 65.73 ms | +4.4% | 46.83 ms | 43.97 ms | +4.4% |
中央値 TPOT | 41.14 ms | 39.61 ms | - | 69.19 ms | 66.33 ms | - | 45.37 ms | 43.30 ms | - |
P99 TPOT | 62.57 ms | 58.71 ms | - | 100.35 ms | 95.55 ms | - | 62.29 ms | 54.79 ms | - |