勾配ブースト決定木 (GBDT) バイナリ分類は、勾配ブーストに基づく古典的な教師あり学習モデルです。 バイナリ分類シナリオに適しています。
サポートされるコンピューティングリソース
GBDTバイナリ分類V2は、MaxComputeのコンピューティングリソースのみに基づいて使用できます。
アルゴリズム
GBDTバイナリ分類は、勾配ブーストに基づく古典的な教師あり学習モデルです。 バイナリ分類シナリオで使用できます。
原理
勾配ブースティング決定木モデルは、複数の決定木からなる。 各決定木は弱い学習者に対応する。 これらの弱い学習者を組み合わせることで、より良い分類と回帰の結果を得ることができます。
次の図は、グラデーションブーストの基本的な再帰構造を示しています。
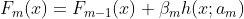
ほとんどの場合、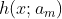 はCART決定木であり、
はCART決定木であり、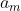 は決定木のパラメータであり、
は決定木のパラメータであり、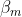 はステップサイズである。 各決定木は、前の決定木に基づいて目的関数を最適化する。 前のプロセスの後、複数の決定木を含むモデルが得られる。
はステップサイズである。 各決定木は、前の決定木に基づいて目的関数を最適化する。 前のプロセスの後、複数の決定木を含むモデルが得られる。
シナリオ
アルゴリズムは、XGBoostによって提供される2次最適化およびLightGBMによって提供されるヒストグラム近似などの最適化を含む。このアルゴリズムは高いパフォーマンスと解釈可能性を提供し、一般的なバイナリ分類に使用できます。
GBDTバイナリ分類V2は、スパースベクトル形式と複数特徴列形式の入力をサポートします。 スパースベクトル形式を使用する場合、文字列タイプの1つの列のみを選択できます。 各データエントリは、スペースで区切られたキーと値のペアです。 値はコロンで区切られます。 例: 1:0.3 3:0.9 複数フィーチャ列形式を使用する場合は、数値フィーチャやカテゴリフィーチャなど、double型、bigint型、string型の複数の列を選択できます。 アルゴリズムは、数値特徴のデータをビンに入れ、カテゴリ特徴を処理するために多対多分割戦略を使用する。 categorical機能に対してワンホットなエンコードを実行する必要はありません。
アルゴリズムは、バイナリ分類のカテゴリが0と1でなければならないことを要求する。
このコンポーネントは、GBDTバイナリ分類予測V2コンポーネントとペアで使用されます。 これらのコンポーネントを実行した後、トレーニング済みモデルをオンラインサービスとしてデプロイできます。 詳細については、「オンラインサービスとしてのパイプラインのデプロイ」をご参照ください。
Machine Learning Designerでのコンポーネントの設定
入力ポート
ポート (左から右) | データ型 | 推奨上流コンポーネント | 必須 / 任意 |
入力データ | パラメーターは返されません。 | はい |
コンポーネントパラメーター
タブ | パラメーター | 必須 / 任意 | 説明 | デフォルト値 |
フィールド設定 | スパースベクトル形式の使用 | いいえ | 入力テーブルのトレーニングに使用されるフィーチャ列がスパースベクトル形式であるかどうかを指定します。 スパースベクトルフォーマットでは、各データエントリは、スペースによって分離されたキー値ペアである。 値はコロンで区切られます。 例: | いいえ |
フィーチャー列の選択 | はい | トレーニング用に入力テーブルから選択されたフィーチャ列の名前。 スパースベクトル形式が選択されていない場合は、double型、bigint型、またはstring型の列を選択できます。 スパースベクトル形式が選択されている場合、文字列タイプの1つの列のみを選択できます。 | パラメーターは返されません。 | |
カテゴリ機能列の選択 | いいえ | カテゴリ機能として処理する列を選択します。 選択されていない列は数値特徴として処理される。 このパラメーターは、スパースベクトル形式が選択されていない場合に有効です。 | パラメーターは返されません。 | |
ラベル列の選択 | はい | トレーニング用に入力テーブルから選択されたラベル列の名前。 | パラメーターは返されません。 | |
重量列の選択 | いいえ | トレーニング用に入力テーブルから選択された重み列の名前。 | パラメーターは返されません。 | |
パラメーター設定 | ツリー数 | いいえ | モデル内のツリーの数。 | 1 |
リーフノードの最大数 | いいえ | 各ツリーのリーフノードの最大数。 | 32 | |
学習率 | いいえ | 学習率。 | 0.05 | |
比率のサンプル | いいえ | トレーニングのために選択されたサンプルの割合。 有効な値: (0,1) 。 | 0.6 | |
特徴の比率 | いいえ | トレーニングのために選択された特徴の割合。 有効な値: (0,1) 。 | 0.6 | |
リーフノードの最小サンプル数 | いいえ | 各リーフノードの最小サンプル数。 | 500 | |
最大ビン数 | いいえ | 連続フィーチャを離散化するときに許可されるビンの最大数。 値が大きいほど、より正確な分割を示す。 より正確な分割は、より高いコストを生み出す。 | 32 | |
異なるカテゴリの最大数 | いいえ | カテゴリ機能に許可される個別のカテゴリの最大数。 各カテゴリ特徴について、カテゴリは頻度に基づいてソートされる。 この値より大きいランクを持つカテゴリは、1つのバケットに結合されます。 値が大きいほど、より正確な分割を示す。 より正確な分割は、オーバーフィッティングの可能性が高くなり、コストが高くなります。 | 1024 | |
機能の数 | いいえ | このパラメーターは、スパースベクトル形式が選択されている場合に有効です。 パラメータを最大フィーチャID + 1の値として指定します。 このパラメータが空のままである場合、システムは自動的にデータをスキャンして計算します。 | 数は入力データに基づいて自動的に計算されます。 | |
初期予測 | いいえ | 陽性サンプルの確率。 システムは自動的にデータをスキャンして、このパラメータが空のままであるかを推定します。 | 数は入力データに基づいて自動的に計算されます。 | |
ランダムシード | いいえ | サンプリングに使用されるランダムシード。 | 0 | |
チューニング | [実行モードの選択] | いいえ | 実行モードを選択します。 有効な値:
| MaxCompute |
インスタンス数 | いいえ | ジョブの実行に使用されるインスタンスの数。 | 数は入力データに基づいて自動的に計算されます。 | |
インスタンスごとのメモリ | いいえ | 各インスタンスのメモリサイズ。 単位:MB。 | 数は入力データに基づいて自動的に計算されます。 | |
Num of Threads | いいえ | マルチスレッドが使用される場合、より高いコストが発生する。 ほとんどの場合、パフォーマンスはスレッド数とともに直線的に増加しません。 最適なスレッド数よりも多くのスレッドが使用されると、性能が低下する。 | 1 |
出力ポート
出力ポート | 保管場所 | 推奨下流コンポーネント | データ型 |
出力モデル | 非該当 | MaxComputeテーブル | |
出力機能の重要性 | 非該当 | パラメーターは返されません。 下流のコンポーネントは、GBDT機能重要度V2などのPAIコマンドベースのコンポーネントに接続できません。 | MaxComputeテーブル |
との比較PS-SMARTバイナリ分類トレーニング
PS-SMARTバイナリ分類トレーニングコンポーネントを使用するときに処理が難しい問題が発生した場合は、GBDTバイナリ分類V2コンポーネントを使用できます。 詳細については、「PS-SMARTバイナリ分類トレーニング」をご参照ください。 次の表に、2つのコンポーネントの機能とパラメーターを示します。
パラメータのPS-SMARTバイナリ分类トレーニング | GBDTバイナリ分類V2 |
スパース形式の使用 | スパースベクトル形式の使用 |
フィーチャー列 | フィーチャー列 |
ラベル列 | ラベル列 |
重量コラム | 重量列の選択 |
評価インジケータタイプ | サポートされていません。 曲線下面積 (AUC) は、デフォルトで使用される。 ワーカーログでメトリックを表示できます。 |
木 | ツリー数 |
最大ツリー深さ | リーフノードの最大数: |
データサンプリング分画 | 比率のサンプル |
特徴サンプリング分数 | 特徴の比率 |
L1ペナルティ係数 | 非対応 |
L2ペナルティ係数 | 非対応 |
学習率 | 学習率 |
スケッチベースの近似精度 | 最大ビン数: |
最小スプリット損失変更 | Minimum Number of Samples in a Leaf Node: 直接最小分割損失変化に変換することはできませんが、両方のパラメータを使用してオーバーフィッティングを防ぐことができます。 |
機能 | 機能 |
グローバルオフセット | グローバルオフセット |
ランダムシード | ランダムシード |
機能重要性タイプ | 非該当 デフォルト値: gain。 |
コア | インスタンス数: コアと同じ値ではありません。 システムによって自動的に生成された値に基づいて数値を調整することをお勧めします。 |
コアあたりのメモリサイズ | インスタンスあたりのメモリ: コアあたりのメモリサイズと同じ値ではありません。 システムによって自動的に生成された値に基づいて数値を調整することをお勧めします。 |