Elastic Algorithm Service (EAS) では、共有ゲートウェイと専用ゲートウェイの両方が提供されています。どちらもインターネットおよびイントラネット経由でのサービス呼び出しをサポートしており、呼び出しフローはほぼ同一です。ご要件に応じて、適切なゲートウェイおよびエンドポイントを選択してください。
ゲートウェイの選択
EAS では、共有ゲートウェイと専用ゲートウェイの 2 種類のゲートウェイが利用可能です。主な違いは以下のとおりです:
比較項目 | 共有ゲートウェイ | 専用ゲートウェイ |
インターネット経由の呼び出し | デフォルトでサポートされます。 | 有効化後にサポートされます。 |
イントラネット経由の呼び出し | デフォルトでサポートされます。 | 有効化後にサポートされます。 |
コスト | 無料です。 | 有料です。 |
適用シナリオ | 帯域幅を共有します。トラフィック量が少なく、カスタムアクセスポリシーの設定が不要なサービスに最適です。テスト環境でのご利用を推奨します。 | 専用帯域幅を提供します。高いセキュリティ性・安定性・パフォーマンスが求められ、大量のトラフィックを処理するサービスに最適です。本番環境でのご利用を推奨します。 |
サービス構成方法 | デフォルト構成です。そのままご利用いただけます。 | 事前に作成する必要があります。その後、サービスのデプロイ時に選択します。詳細については、「専用ゲートウェイの使用」をご参照ください。 |
エンドポイントの選択
インターネットエンドポイント:インターネットに接続可能な任意の環境でご利用ください。リクエストは EAS 共有ゲートウェイを経由し、オンラインの EAS サービスに送信されます。
VPC エンドポイント:呼び出し元プログラムと EAS サービスが同一リージョンにデプロイされている場合にご利用ください。同一リージョン内の VPC は相互に接続可能です。
VPC 内部ネットワーク経由の呼び出しは、ネットワークパフォーマンスのオーバーヘッドを回避できるため、インターネット経由の呼び出しよりも高速です。また、内部ネットワークトラフィックは通常無料であるため、コストも低減できます。
サービスの呼び出し手順
サービスを呼び出すには、まずそのエンドポイントとトークンを取得します。その後、ご使用のモデルサービスに応じたリクエストを構築します。
ステップ 1:エンドポイントとトークンの取得
サービスをデプロイすると、EAS が自動的に必要なエンドポイントおよび認証トークンを生成します。
コンソールに表示されるエンドポイントはベース URL です。完全なリクエスト URL を構成するには、正しい API パスを追加する必要があります。404 Not Found エラーの最も一般的な原因は、誤ったパスの指定です。
Inference Service タブで、対象のサービス名をクリックして Overview ページを開きます。Basic Information セクションで、View Endpoint Information をクリックします。
Invocation Method パネルから、エンドポイントとトークンを取得します。ご要件に応じて、インターネットエンドポイントまたは VPC エンドポイントのいずれかを選択してください。以降、これらの値をそれぞれ <EAS_ENDPOINT> および <EAS_TOKEN> と表記します。

ステップ 2:リクエストの構築と送信
インターネットエンドポイントまたは VPC エンドポイントのいずれを利用する場合でも、リクエスト構造はほぼ同一です。異なるのは URL のみです。標準的なリクエストには、以下の 4 つのコア要素があります:
HTTP メソッド:最も一般的なのは POST および GET です。
URL:ベースエンドポイント <EAS_ENDPOINT> に特定の API パスを結合します。
リクエストヘッダー:最低限、Authorization: <Token> を含める必要があります。
リクエストボディ:そのフォーマット(例:JSON)は、デプロイ済みのモデルの API 仕様によって異なります。
重要ゲートウェイを介して呼び出す場合、リクエストボディは 1 MB を超えてはなりません。
サンプル
サンプル 1:Model Gallery からモデルを呼び出す
Model Gallery のモデルの Overview ページに移動します。このページには、curl または Python コードによる正確な API 呼び出し例(完全な URL パスおよびリクエストボディのフォーマットを含む)が通常表示されます。
cURL コマンド
cURL の基本構文は curl [options] [URL] です:
オプションは任意です。代表的なものとして、
-X(HTTP メソッドの指定)、-H(ヘッダーの指定)、-d(リクエストボディの指定)などがあります。URL は、呼び出す HTTP エンドポイントです。
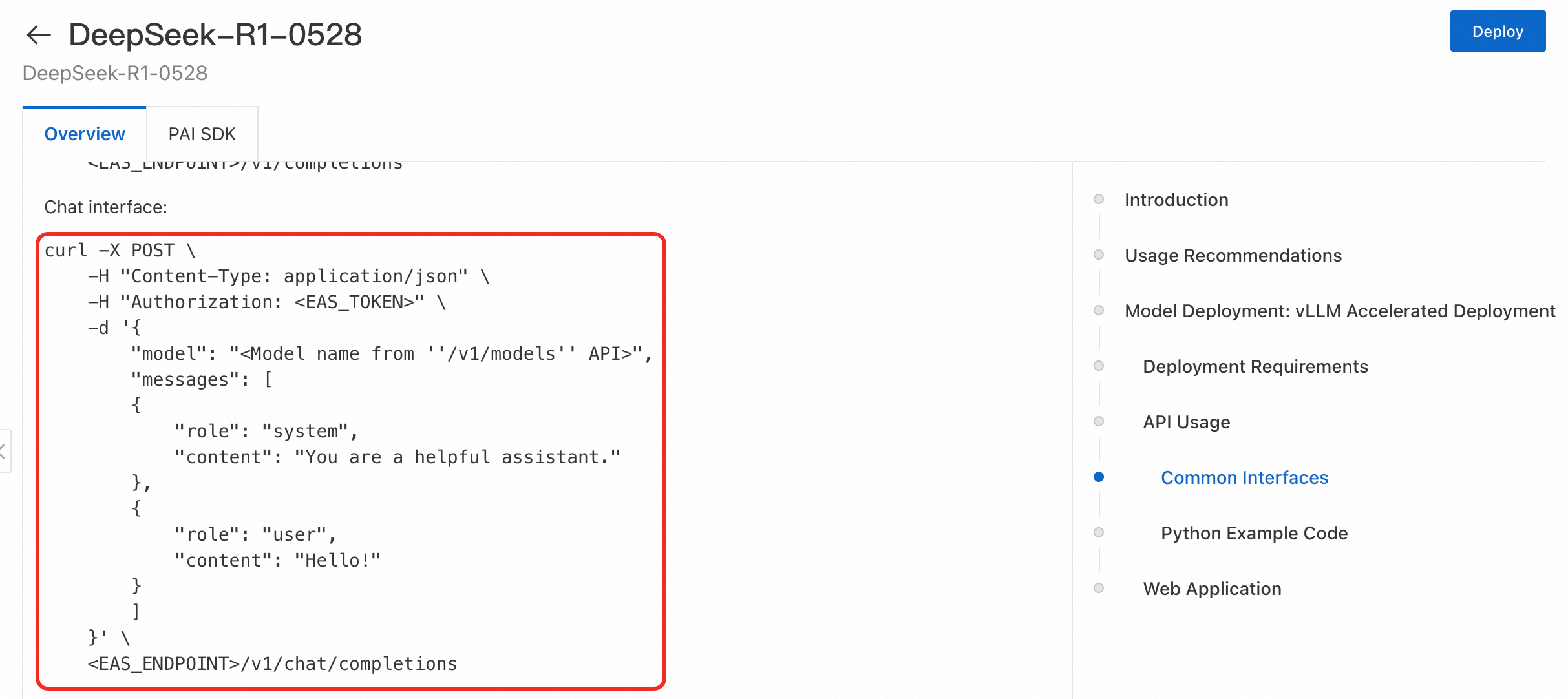
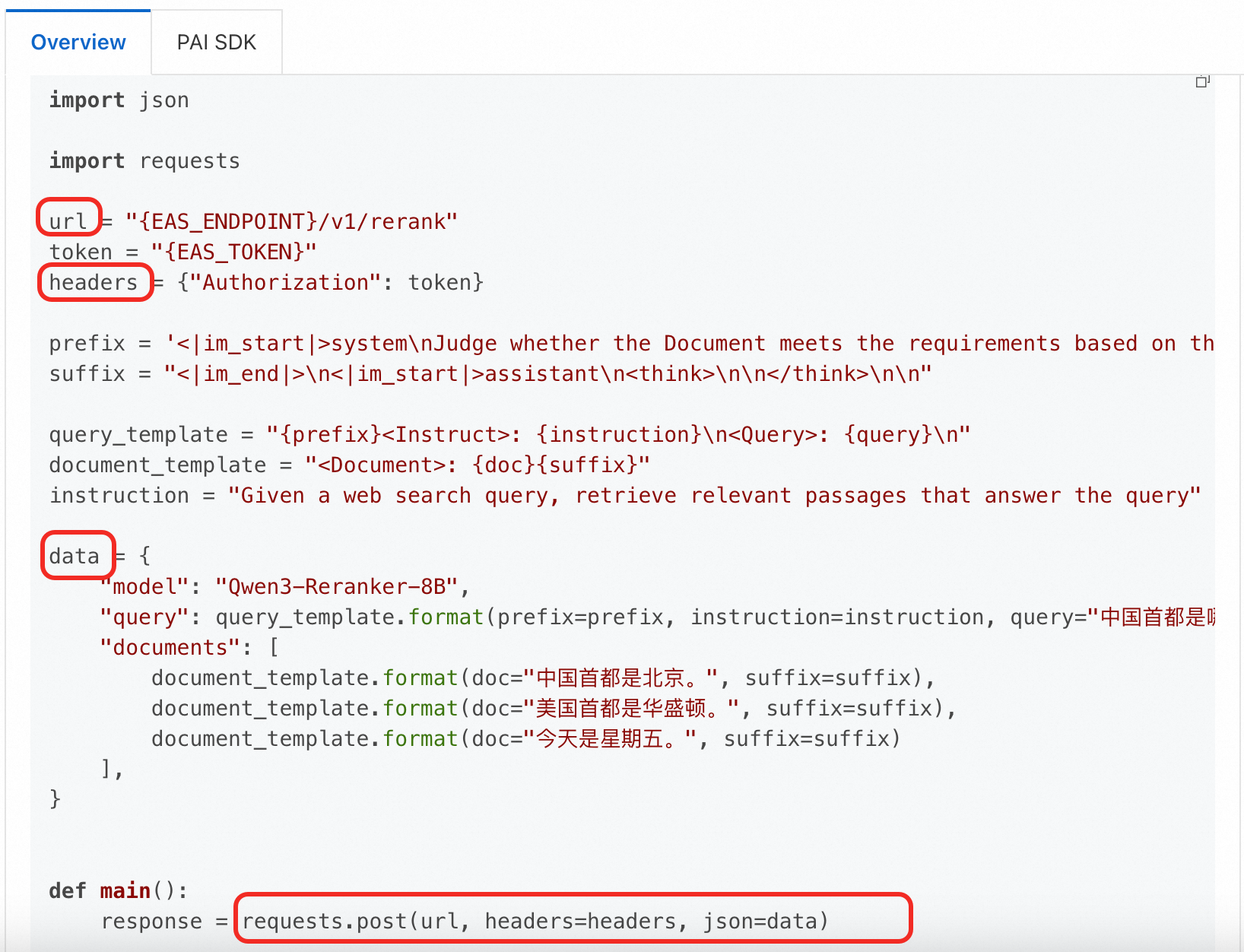
Python コード
この例では Qwen3-Reranker-8B モデルを使用します。URL およびリクエストボディは cURL の例とは異なります。必ずモデルの説明ページをご確認ください。
サンプル 2:大規模言語モデル(LLM)の呼び出し
大規模言語モデル(LLM)サービスでは、OpenAI 互換 API が提供されることが多く、チャット完了エンドポイント(/v1/chat/completions)や完了エンドポイント(/v1/completions)などが該当します。
たとえば、vLLM を使用してデプロイされた DeepSeek-R1-Distill-Qwen-7B モデルのチャット完了エンドポイントを呼び出す場合、以下の要素を使用します(詳細については、「LLM の呼び出し」をご参照ください):
HTTP メソッド: POST
URL: <EAS_ENDPOINT>/v1/chat/completions
リクエストヘッダー: Authorization: <Token> および Content-Type: application/json
リクエストボディ:
{ "model": "DeepSeek-R1-Distill-Qwen-7B", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "hello!" } ] }
例: <EAS_ENDPOINT> が http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/test の場合です。
curl http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/test/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: *********5ZTM1ZDczg5OT**********" \
-X POST \
-d '{
"model": "DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "hello!"
}
]
}' import requests
# 実際のエンドポイントに置き換えてください
url = 'http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/test/v1/chat/completions'
# 実際のトークンに置き換えて Authorization を設定してください
headers = {
"Content-Type": "application/json",
"Authorization": "*********5ZTM1ZDczg5OT**********",
}
# モデルの要求するデータ形式に基づいてリクエストボディを構築します。
data = {
"model": "DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "hello!"
}
]
}
# リクエストを送信します
resp = requests.post(url, json=data, headers=headers)
print(resp)
print(resp.content)その他のユースケース
TensorFlow、Caffe、PMML などの汎用プロセッサでデプロイされたサービス:「汎用プロセッサを使用したサービスリクエストの構築」をご参照ください。
ご自身で学習したモデル:元のモデルと同様の方法で呼び出せます。
その他のカスタムサービス:リクエストフォーマットは、カスタムイメージまたはコード内で定義したデータ入力フォーマットに依存します。
よくある質問
「サービス呼び出しに関するよくある質問」をご参照ください。