MaxCompute は、MaxCompute V2.0 コンピュートエンジンをベースにしたユーザー定義関数 (UDF) フレームワークにユーザー定義の結合 (UDJ) を導入しています。UDJ は、テーブルを柔軟に結合することで、より多くのユーザー定義操作を可能にし、基盤となる分散システムでの MapReduce ベースの操作を簡素化します。
背景情報
MaxCompute は、INNER JOIN、RIGHT JOIN、LEFT JOIN、FULL JOIN、SEMI JOIN、ANTI-SEMI JOIN など、複数の組み込み Join 操作を提供します。これらの組み込み Join 操作は強力ですが、その標準的な実装では、クロステーブル操作を伴う多くのシナリオの要件を満たすことができません。
ほとんどの場合、UDF を使用してコードフレームワークを記述できます。ただし、現在の UDF、ユーザー定義のテーブル値関数 (UDTF)、およびユーザー定義の集計関数 (UDAF) フレームワークは、一度に 1 つのテーブルしか処理できません。複数のテーブルに対してユーザー定義の操作を実行するには、組み込みの [JOIN メソッド、UDF、UDTF]、および複雑な SQL 文を使用する必要があります。このようなシナリオでは、SQL の代わりにカスタム MapReduce フレームワークを使用して、必要なコンピューティングタスクを完了する必要があります。
シナリオに関係なく、この操作には [技術的な専門知識] が必要であり、次の問題が発生する可能性があります。
[組み込みの JOIN メソッド、UDF、UDTF、および複雑な SQL 文] を使用するシナリオでは、SQL 文で複数の JOIN メソッドとコードを使用すると、論理的なブラックボックスが生じ、最適な実行計画の生成が困難になります。
カスタム MapReduce フレームワークを使用するシナリオでは、実行計画の最適化が困難です。ほとんどの MapReduce コードは Java で記述されています。ネイティブランタイムコードのディープな最適化中、MapReduce コードの実行は、Low Level Virtual Machine (LLVM) コードジェネレータによって生成される MaxCompute コードの実行よりも効率が低くなります。
制限
UDF、UDAF、または UDTF を使用して、次の種類のテーブルからデータを読み取ることはできません。
スキーマ進化が実行されたテーブル
複雑なデータ型を含むテーブル
JSON データ型を含むテーブル
トランザクションテーブル
UDJ のパフォーマンス
実際のオンライン MapReduce ジョブを例として使用して、UDJ のパフォーマンスを検証します。このジョブは、複雑なアルゴリズムに基づいて実行されます。この例では、2 つのテーブルが結合され、UDJ を使用して MapReduce ジョブが再書き込みされ、UDJ の結果の正当性がチェックされます。次の図は、同じデータ並行性における MapReduce と UDJ のパフォーマンスを示しています。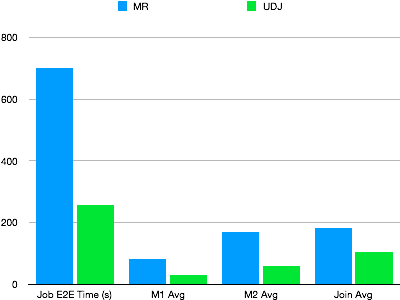
図に示すように、UDJ は複数のテーブルを処理するための複雑なロジックを簡単に記述し、パフォーマンスを大幅に向上させます。コードは UDJ 内でのみ呼び出されます。この例の mapper 全体のロジックは、MaxCompute のネイティブランタイムによって実行されます。MaxCompute UDJ ランタイムエンジンと Java インターフェイス間のデータ交換ロジックは、Java コードで最適化されています。UDJ の JOIN ロジックは、reducer の JOIN ロジックよりも効率的です。
UDJ を使用したクロス結合操作
次の例では、MaxCompute で UDJ を使用する方法について説明します。
たとえば、payment と user_client_log という名前の 2 つのログテーブルが存在します。
payment テーブルには、ユーザーの支払いレコードが格納されます。各支払いレコードには、ユーザー ID、支払い時間、および支払い内容が含まれます。次の表にサンプルデータを示します。
user_id
time
pay_info
2656199
2018-02-13 22:30:00
gZhvdySOQb
8881237
2018-02-13 08:30:00
pYvotuLDIT
8881237
2018-02-13 10:32:00
KBuMzRpsko
user_client_log テーブルには、ユーザーのクライアントログが格納されます。各ログには、ユーザー ID、ログ記録時間、およびログ内容が含まれます。次の表にサンプルデータを示します。
user_id
time
content
8881237
2018-02-13 00:30:00
click MpkvilgWSmhUuPn
8881237
2018-02-13 06:14:00
click OkTYNUHMqZzlDyL
8881237
2018-02-13 10:30:00
click OkTYNUHMqZzlDyL
要件: user_client_log テーブルの各レコードについて、payment テーブル内でこのレコードに最も近い時間の支払いレコードを見つけます。次に、2 つのレコードを結合して結果を生成します。次の表に結果を示します。
user_id | time | content |
8881237 | 2018-02-13 00:30:00 | click MpkvilgWSmhUuPn, pay pYvotuLDIT |
8881237 | 2018-02-13 06:14:00 | click OkTYNUHMqZzlDyL, pay pYvotuLDIT |
8881237 | 2018-02-13 10:30:00 | click OkTYNUHMqZzlDyL, pay KBuMzRpsko |
この要件を満たすには、次のいずれかのメソッドを使用します。
組み込みの JOIN メソッドを使用します。SQL 擬似コードのサンプル:
SELECT p.user_id, p.time, MERGE(p.pay_info, u.content) FROM payment p RIGHT OUTER JOIN user_client_log u ON p.user_id = u.user_id AND ABS(p.time - u.time) = MIN(ABS(p.time - u.time))テーブル内の 2 つのレコードを結合する場合、同じ user_id に対応する p.time と u.time の間の最小の差を計算する必要があります。ただし、JOIN 条件では集計関数を呼び出すことはできません。したがって、標準の JOIN メソッドを使用してこのタスクを完了することはできません。
UDJ メソッドを使用します。
UDJ 関数を作成します。
新しいバージョンの SDK を設定します。
<dependency> <groupId>com.aliyun.odps</groupId> <artifactId>odps-sdk-udf</artifactId> <version>0.29.10-public</version> <scope>provided</scope> </dependency>UDJ コードを記述し、コードを odps-udj-example.jar としてパッケージ化します。
package com.aliyun.odps.udf.example.udj; import com.aliyun.odps.Column; import com.aliyun.odps.OdpsType; import com.aliyun.odps.Yieldable; import com.aliyun.odps.data.ArrayRecord; import com.aliyun.odps.data.Record; import com.aliyun.odps.udf.DataAttributes; import com.aliyun.odps.udf.ExecutionContext; import com.aliyun.odps.udf.UDJ; import com.aliyun.odps.udf.annotation.Resolve; import java.util.ArrayList; import java.util.Iterator; /** 右側のテーブルの各レコードについて、左側のテーブルで最も近いレコードを見つけて、2 つのレコードをマージします。 */ @Resolve("->string,bigint,string") public class PayUserLogMergeJoin extends UDJ { private Record outputRecord; /** このメソッドは、データ処理フェーズの前に呼び出されます。このメソッドを実装して初期化を実行できます。 */ @Override public void setup(ExecutionContext executionContext, DataAttributes dataAttributes) { // outputRecord = new ArrayRecord(new Column[]{ new Column("user_id", OdpsType.STRING), new Column("time", OdpsType.BIGINT), new Column("content", OdpsType.STRING) }); } /** このメソッドをオーバーライドして、結合ロジックを実装します。 * @param key 現在の結合キー * @param left 現在のキーに対応する左テーブルのレコードのグループ * @param right 現在のキーに対応する右テーブルのレコードのグループ * @param output UDJ の結果を出力するために使用されます */ @Override public void join(Record key, Iterator<Record> left, Iterator<Record> right, Yieldable<Record> output) { outputRecord.setString(0, key.getString(0)); if (!right.hasNext()) { // 右側のグループは空です。何もしません。 return; } else if (!left.hasNext()) { // 左側のグループは空です。マージせずに右側のグループからすべてのレコードを出力します。 while (right.hasNext()) { Record logRecord = right.next(); outputRecord.setBigint(1, logRecord.getDatetime(0).getTime()); outputRecord.setString(2, logRecord.getString(1)); output.yield(outputRecord); } return; } ArrayList<Record> pays = new ArrayList<>(); // 左側のレコードグループは、最初から最後まで反復処理されます。 // イテレータは、右側のグループの各レコードに対してリセットできません。 // したがって、左側のテーブルの各レコードを ArrayList に保存します。 left.forEachRemaining(pay -> pays.add(pay.clone())); while (right.hasNext()) { Record log = right.next(); long logTime = log.getDatetime(0).getTime(); long minDelta = Long.MAX_VALUE; Record nearestPay = null; // 左側のすべてのレコードを反復処理して、時間差が最も小さいレコードを見つけます。 for (Record pay: pays) { long delta = Math.abs(logTime - pay.getDatetime(0).getTime()); if (delta < minDelta) { minDelta = delta; nearestPay = pay; } } // ログレコードを最も近い支払いレコードとマージし、結果を出力します。 outputRecord.setBigint(1, log.getDatetime(0).getTime()); outputRecord.setString(2, mergeLog(nearestPay.getString(1), log.getString(1))); output.yield(outputRecord); } } String mergeLog(String payInfo, String logContent) { return logContent + ", pay " + payInfo; } @Override public void close() { } }MaxCompute に JAR パッケージリソースを追加します。
ADD jar odps-udj-example.jar;MaxCompute に UDJ 関数 pay_user_log_merge_join を登録します。
CREATE FUNCTION pay_user_log_merge_join AS 'com.aliyun.odps.udf.example.udj.PayUserLogMergeJoin' USING 'odps-udj-example.jar';
サンプルデータを準備します。
payment テーブルと user_client_log テーブルを作成します。
CREATE TABLE payment(user_id STRING,time DATETIME,pay_info STRING); CREATE TABLE user_client_log(user_id STRING,time DATETIME,content STRING);テーブルにデータを挿入します。
--payment テーブルにデータを挿入します。 INSERT OVERWRITE TABLE payment VALUES ('1335656', datetime '2018-02-13 19:54:00', 'PEqMSHyktn'), ('2656199', datetime '2018-02-13 12:21:00', 'pYvotuLDIT'), ('2656199', datetime '2018-02-13 20:50:00', 'PEqMSHyktn'), ('2656199', datetime '2018-02-13 22:30:00', 'gZhvdySOQb'), ('8881237', datetime '2018-02-13 08:30:00', 'pYvotuLDIT'), ('8881237', datetime '2018-02-13 10:32:00', 'KBuMzRpsko'), ('9890100', datetime '2018-02-13 16:01:00', 'gZhvdySOQb'), ('9890100', datetime '2018-02-13 16:26:00', 'MxONdLckwa') ; --user_client_log テーブルにデータを挿入します。 INSERT OVERWRITE TABLE user_client_log VALUES ('1000235', datetime '2018-02-13 00:25:36', 'click FNOXAibRjkIaQPB'), ('1000235', datetime '2018-02-13 22:30:00', 'click GczrYaxvkiPultZ'), ('1335656', datetime '2018-02-13 18:30:00', 'click MxONdLckpAFUHRS'), ('1335656', datetime '2018-02-13 19:54:00', 'click mKRPGOciFDyzTgM'), ('2656199', datetime '2018-02-13 08:30:00', 'click CZwafHsbJOPNitL'), ('2656199', datetime '2018-02-13 09:14:00', 'click nYHJqIpjevkKToy'), ('2656199', datetime '2018-02-13 21:05:00', 'click gbAfPCwrGXvEjpI'), ('2656199', datetime '2018-02-13 21:08:00', 'click dhpZyWMuGjBOTJP'), ('2656199', datetime '2018-02-13 22:29:00', 'click bAsxnUdDhvfqaBr'), ('2656199', datetime '2018-02-13 22:30:00', 'click XIhZdLaOocQRmrY'), ('4356142', datetime '2018-02-13 18:30:00', 'click DYqShmGbIoWKier'), ('4356142', datetime '2018-02-13 19:54:00', 'click DYqShmGbIoWKier'), ('8881237', datetime '2018-02-13 00:30:00', 'click MpkvilgWSmhUuPn'), ('8881237', datetime '2018-02-13 06:14:00', 'click OkTYNUHMqZzlDyL'), ('8881237', datetime '2018-02-13 10:30:00', 'click OkTYNUHMqZzlDyL'), ('9890100', datetime '2018-02-13 16:01:00', 'click vOTQfBFjcgXisYU'), ('9890100', datetime '2018-02-13 16:20:00', 'click WxaLgOCcVEvhiFJ') ;
SQL で UDJ を使用します。
SELECT r.user_id, FROM_UNIXTIME(time/1000) AS time, content FROM ( SELECT user_id, time AS time, pay_info FROM payment ) p JOIN ( SELECT user_id, time AS time, content FROM user_client_log ) u ON p.user_id = u.user_id USING pay_user_log_merge_join(p.time, p.pay_info, u.time, u.content) r AS (user_id, time, content);USING 句のパラメーター:
pay_user_log_merge_joinは、登録された UDJ 関数の名前です。(p.time, p.pay_info, u.time, u.content)は、UDJ で使用される左テーブルと右テーブルの列を指定します。rは UDJ 結果のエイリアスです。このエイリアスは他の場所で参照できます。(user_id, time, content)は、UDJ によって生成された結果の列名を指定します。
この例では、次の結果が返されます。
+---------+------------+---------+ | user_id | time | content | +---------+------------+---------+ | 1000235 | 2018-02-13 00:25:36 | click FNOXAibRjkIaQPB | | 1000235 | 2018-02-13 22:30:00 | click GczrYaxvkiPultZ | | 1335656 | 2018-02-13 18:30:00 | click MxONdLckpAFUHRS, pay PEqMSHyktn | | 1335656 | 2018-02-13 19:54:00 | click mKRPGOciFDyzTgM, pay PEqMSHyktn | | 2656199 | 2018-02-13 08:30:00 | click CZwafHsbJOPNitL, pay pYvotuLDIT | | 2656199 | 2018-02-13 09:14:00 | click nYHJqIpjevkKToy, pay pYvotuLDIT | | 2656199 | 2018-02-13 21:05:00 | click gbAfPCwrGXvEjpI, pay PEqMSHyktn | | 2656199 | 2018-02-13 21:08:00 | click dhpZyWMuGjBOTJP, pay PEqMSHyktn | | 2656199 | 2018-02-13 22:29:00 | click bAsxnUdDhvfqaBr, pay gZhvdySOQb | | 2656199 | 2018-02-13 22:30:00 | click XIhZdLaOocQRmrY, pay gZhvdySOQb | | 4356142 | 2018-02-13 18:30:00 | click DYqShmGbIoWKier | | 4356142 | 2018-02-13 19:54:00 | click DYqShmGbIoWKier | | 8881237 | 2018-02-13 00:30:00 | click MpkvilgWSmhUuPn, pay pYvotuLDIT | | 8881237 | 2018-02-13 06:14:00 | click OkTYNUHMqZzlDyL, pay pYvotuLDIT | | 8881237 | 2018-02-13 10:30:00 | click OkTYNUHMqZzlDyL, pay KBuMzRpsko | | 9890100 | 2018-02-13 16:01:00 | click vOTQfBFjcgXisYU, pay gZhvdySOQb | | 9890100 | 2018-02-13 16:20:00 | click WxaLgOCcVEvhiFJ, pay MxONdLckwa | +---------+------------+---------+
UDJ の事前ソート
時間差が最も小さいレコードを見つけるには、イテレータを使用して `payment` テーブルのデータを繰り返し走査する必要があります。したがって、同じ `user_id` を持つすべての支払いレコードは、事前に `ArrayList` にロードされます。このメソッドは、ユーザーが 1 日のうちに少数の支払い動作しか行わないシナリオに適用できます。他のシナリオでは、同じグループ内のデータ量が多すぎてメモリに格納できない場合があります。この場合、`SORT BY` 事前ソートを使用してこの問題を解決できます。
ユーザーの支払いレコード数が過度に多く、メモリに格納できず、テーブル内のすべてのデータが時間でソートされている場合、ArrayList の最初の要素を比較するだけで済みます。
次の例は、Java UDJ コードを示しています。
@Override
public void join(Record key, Iterator<Record> left, Iterator<Record> right, Yieldable<Record> output) {
outputRecord.setString(0, key.getString(0));
if (!right.hasNext()) {
return;
} else if (!left.hasNext()) {
while (right.hasNext()) {
Record logRecord = right.next();
outputRecord.setBigint(1, logRecord.getDatetime(0).getTime());
outputRecord.setString(2, logRecord.getString(1));
output.yield(outputRecord);
}
return;
}
long prevDelta = Long.MAX_VALUE;
Record logRecord = right.next();
Record payRecord = left.next();
Record lastPayRecord = payRecord.clone();
while (true) {
long delta = logRecord.getDatetime(0).getTime() - payRecord.getDatetime(0).getTime();
if (left.hasNext() && delta > 0) {
// 2 つのレコード間の時間差は減少しているため、処理を続行できます。
// 左側のグループを探索して、より小さいデルタを取得しようとします。
lastPayRecord = payRecord.clone();
prevDelta = delta;
payRecord = left.next();
} else {
// 最小デルタポイントに到達しました。最後のレコードを確認し、
// マージされた結果を出力し、次のレコードを処理する準備をします
// 右側のグループから。
Record nearestPay = Math.abs(delta) < prevDelta ? payRecord : lastPayRecord;
outputRecord.setBigint(1, logRecord.getDatetime(0).getTime());
String mergedString = mergeLog(nearestPay.getString(1), logRecord.getString(1));
outputRecord.setString(2, mergedString);
output.yield(outputRecord);
if (right.hasNext()) {
logRecord = right.next();
prevDelta = Math.abs(
logRecord.getDatetime(0).getTime() - lastPayRecord.getDatetime(0).getTime()
);
} else {
break;
}
}
}
}Java UDJ コードを変更した後、新しいロジックを有効にするには、対応する JAR パッケージを更新する必要があります。
UDJ 文の末尾に SORT BY 句を追加して、UDJ グループ内の左テーブルと右テーブルをそれぞれの時間フィールドでソートします。以下は SQL コードです。
SELECT r.user_id, from_unixtime(time/1000) AS time, content FROM (
SELECT user_id, time AS time, pay_info FROM payment
) p JOIN (
SELECT user_id, time AS time, content FROM user_client_log
) u
ON p.user_id = u.user_id
USING pay_user_log_merge_join(p.time, p.pay_info, u.time, u.content)
r
AS (user_id, time, content)
SORT BY p.time, u.time;結果は、「UDJ を使用したクロス結合操作」セクションの例の結果と一致しています。このメソッドは、`SORT BY` 句を使用して UDJ データを事前ソートします。このプロセスでは、前のアルゴリズムと同じ機能を実装するために、一度に最大 3 つのレコードをキャッシュするだけで済みます。