このトピックでは、MaxCompute Studioを使用してMapReduceプログラムを作成し、JARファイルを生成してから、MaxComputeクライアントでMapReduceジョブを実行する方法について説明します。 このトピックでは、WordCount MapReduceジョブを使用します。
前提条件
MaxComputeクライアントがインストールされ、設定されます。 詳細については、「MaxComputeクライアント (odpscmd) 」をご参照ください。
MaxCompute Studioがインストールされ、使用するMaxComputeプロジェクトに接続されています。 詳細については、「MaxCompute Studioのインストール」および「プロジェクト接続の管理」をご参照ください。
ソースデータファイルが準備され、オンプレミスのマシンに保存されます。
このトピックでは、内容が
hello,odpsであるサンプルファイルdata.txtを使用します。 このようなファイルを準備し、MaxComputeクライアントのbinディレクトリに保存できます。
注意事項
MavenでMapReduceプログラムを開発するには、Maven Central Repositoryでodps-sdk-mapred、odps-sdk-commons、およびodps-sdk-coreを検索し、必要なSDK for Javaのバージョンを見つけます。 この例では、バージョン0.36.4-publicを使用します。 pom.xmlファイルで次の依存関係を設定する必要があります。
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-mapred</artifactId>
<version>0.36.4-public</version>
</dependency>
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-commons</artifactId>
<version>0.36.4-public</version>
</dependency>
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-core</artifactId>
<version>0.36.4-public</version>
</dependency>手順
MaxCompute Studioを使用してMapReduceプログラムを作成、実行、およびデバッグします。
手順2: MapReduce JARファイルの生成とアップロード
コンパイルしたWordCount.javaスクリプトをJARファイルにパッケージ化し、そのファイルをMaxComputeプロジェクトにアップロードします。
MaxComputeプロジェクトにアップロードされたJARファイルに基づいて
JARコマンドを実行し、MapReduceジョブを実行します。
ステップ1: MapReduceプログラムの開発
MaxCompute Javaモジュールを作成します。
IntelliJ IDEAを開始します。 上部のナビゲーションバーで、 を選択します。
の左側のナビゲーションウィンドウで、新しいモジュールダイアログボックスで、MaxCompute Java.を選択します。
設定モジュールSDKをクリックし、次へ.をクリックします。
などのモジュール名を入力します。mapreduceで、モジュール名フィールドをクリックし、仕上げ.をクリックします。
WordCount MapReduceプログラムを作成、実行、およびデバッグします。
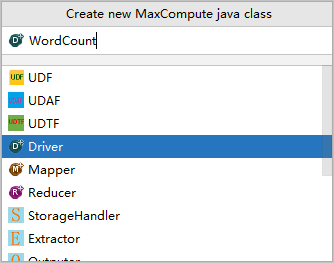
[プロジェクト] ウィンドウで、MaxCompute Javaモジュールを展開し、 を選択します。 次に、javaを右クリックし、 を選択します。
[新しいMaxCompute javaクラスの作成] ダイアログボックスで、[ドライバ] をクリックし、作成するMaxCompute Javaクラスの名前を [名前] フィールドに入力して、enterキーを押します。 たとえば、名前としてWordCountを入力できます。
WordCount.javaのコードエディターで、WordCount MapReduceプログラムを作成して単語数をカウントします。
完全なWordCountサンプルコードについては、「サンプルコード」をご参照ください。
左側のナビゲーションウィンドウで、WordCount.javaを右クリックし、実行.を選択します。
実行 /デバッグ設定ダイアログボックスで, MaxComputeプロジェクトを使用するMaxComputeプロジェクトに追加します。
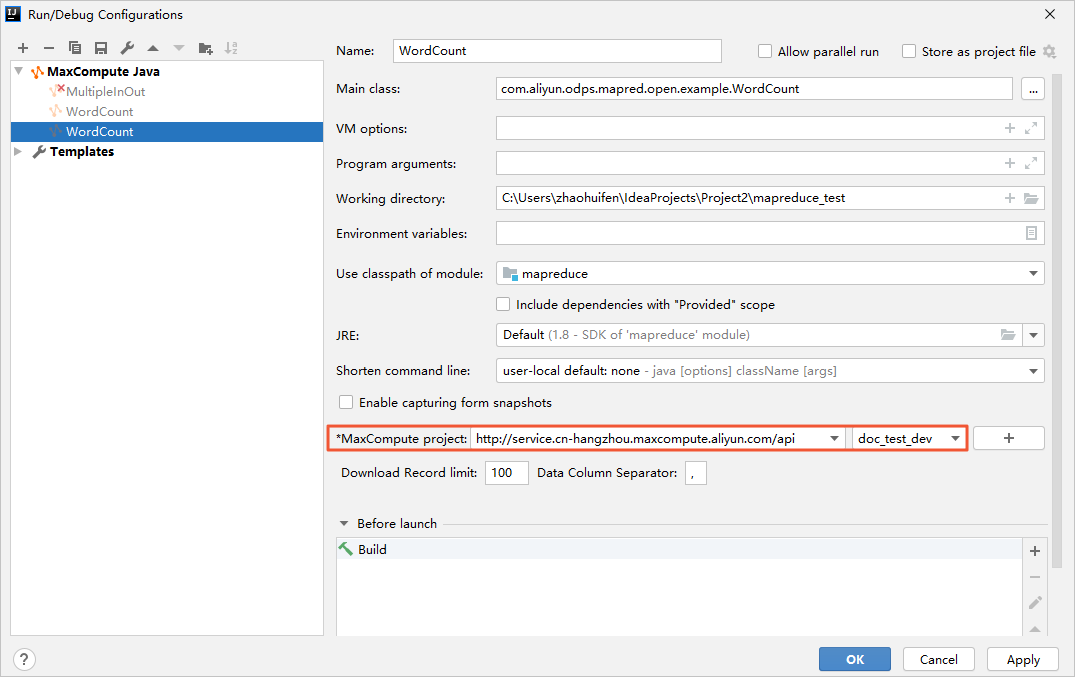
OKをクリックして、WordCount.javaスクリプトを実行およびデバッグして、スクリプトが期待どおりに実行できるようにします。
ステップ2: MapReduce JARファイルの生成とアップロード
IntelliJ IDEAの左側のナビゲーションウィンドウで、WordCount.javaを右クリックし、サーバーにデプロイ. を選択します。
では、jarをパッケージ化してリソースを送信するダイアログボックスでパラメーターを設定し、OKスクリプトをパッケージ化してアップロードします。
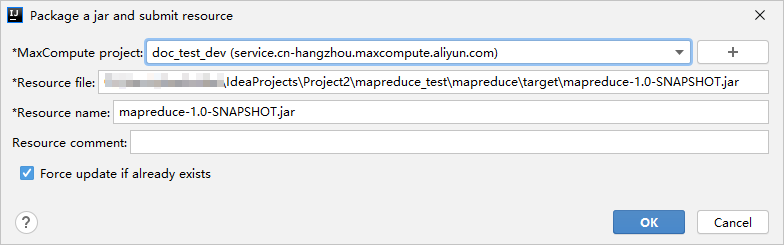
ステップ3: MapReduceジョブを実行する
MaxComputeクライアントにログインするか、MaxCompute StudioでMaxComputeクライアントを起動します。
MaxComputeクライアントはMaxCompute Studioに統合されています。 MaxCompute StudioでMaxComputeクライアントを実行できます。 詳細については、「MaxComputeクライアントの統合」をご参照ください。
入出力テーブルを作成します。
入力テーブルには、MapReduceジョブのソースデータが含まれます。 出力テーブルには、MapReduceジョブの処理結果が含まれます。 サンプルコマンド:
--Create an input table named wc_in. create table wc_in (key STRING, value STRING); --Create an output table named wc_out. create table wc_out (key STRING, cnt BIGINT);テーブルの作成構文の詳細については、「テーブルの作成」をご参照ください。
Tunnel Uploadコマンドを実行して、wc_inテーブルにデータを挿入します。
JARコマンドを実行して、アップロードされたJARファイルを呼び出し、MapReduceジョブを実行します。サンプルコマンド:
jar -resources mapreduce-1.0-SNAPSHOT.jar -classpath mapreduce-1.0-SNAPSHOT.jar com.aliyun.odps.mapred.open.example.WordCount wc_in wc_out;-resources mapreduce-1.0-SNAPSHOT.jar:-resourcesオプションは、MapReduceジョブによって呼び出されるリソースの名前を指定します。 この例では、リソースはステップ2でアップロードされたmapreduce-1.0-SNAPSHOT.jarファイルです。-classpath mapreduce-1.0-SNAPSHOT.jar:-classpathオプションは、MainClassを含むJARファイルのパスを指定します。com.aliyun.odps.mapred.open.example.WordCount: MapReduceプログラムで定義されているMainClass。wc_in wc_out: 入力テーブルと出力テーブル。
JARコマンドの詳細については、「構文」をご参照ください。次のコマンドを実行して、wc_outテーブルに書き込まれた結果データを表示します。
select * from wc_out;次の応答が返されます。
+------------+------------+ | key | cnt | +------------+------------+ | hello | 1 | | odps | 1 | +------------+------------+