Alibaba Cloud Elasticsearch (ES) を使用して、MySQL データベースのデータに対して全文検索、多次元クエリ、または統計分析を実行できます。このトピックでは、DataWorks の Data Integration サービスを使用して、MySQL データベースから Alibaba Cloud ES クラスターに数分でデータを同期する方法について説明します。
背景情報
DataWorks は、ビッグデータエンジン上に構築された、エンドツーエンドのビッグデータ開発およびガバナンスプラットフォームです。データ開発、タスクスケジューリング、データ管理などの機能を統合しています。DataWorks の同期タスクを使用すると、さまざまなデータソースから Alibaba Cloud ES クラスターにデータを迅速に同期できます。
サポートされているデータソースは次のとおりです:
ApsaraDB データベース (MySQL、PostgreSQL、SQL Server、MongoDB、および HBase)
Alibaba Cloud PolarDB-X (旧 DRDS からアップグレード)
Alibaba Cloud MaxCompute
Alibaba Cloud OSS
Alibaba Cloud Tablestore
Hadoop 分散ファイルシステム (HDFS)、Oracle、FTP、DB2、および上記のデータベースタイプの自己管理バージョン
シナリオ:
Alibaba Cloud ES クラスターへのビッグデータのオフライン同期。データベース全体または特定のテーブルを同期できます。詳細については、「MySQL データベース全体の Elasticsearch へのオフライン同期」をご参照ください。
Alibaba Cloud ES クラスターへのビッグデータのリアルタイム同期。このメソッドは、完全同期と増分同期の両方をサポートします。詳細については、「MySQL データベース全体の Elasticsearch へのリアルタイム同期」をご参照ください。
前提条件
ApsaraDB RDS for MySQL インスタンスが作成されていること。詳細については、「ApsaraDB RDS for MySQL インスタンスの作成」をご参照ください。このトピックでは、MySQL 5.7 を例として使用します。
Alibaba Cloud ES インスタンスが作成され、インスタンスの自動インデックス作成機能が有効になっていること。詳細については、「Alibaba Cloud Elasticsearch インスタンスの作成」および「YML ファイルの設定」をご参照ください。
DataWorks ワークスペースが作成されていること。詳細については、「ワークスペースの作成」をご参照ください。
データは Alibaba Cloud ES にのみ同期できます。自己管理の Elasticsearch クラスターはサポートされていません。
ApsaraDB RDS for MySQL インスタンス、ES インスタンス、および DataWorks ワークスペースは、同じリージョンにある必要があります。
ApsaraDB RDS for MySQL インスタンス、ES インスタンス、および DataWorks ワークスペースは、同じタイムゾーンにある必要があります。そうでない場合、時間関連のデータを同期する際に、ソースデータと宛先データの間でタイムゾーンの差異が生じる可能性があります。
課金
ES インスタンス料金の詳細については、「ES 課金項目」をご参照ください。
Data Integration リソースグループ料金の詳細については、「リソースグループ料金」をご参照ください。
操作手順
このトピックでは、オフライン同期を例として説明します。リアルタイムでデータを同期するには、「MySQL データベース全体の Elasticsearch へのリアルタイム同期」をご参照ください。
ステップ1:ソースデータの準備
ApsaraDB RDS for MySQL インスタンスにデータベースとテーブルを作成します。
ApsaraDB for RDS データベースまたはローカルサーバー上の自己管理データベースを使用できます。このトピックでは、ApsaraDB RDS for MySQL データベースを例に、データベースとテーブルの作成方法を説明します。詳細については、「クイックスタート」をご参照ください。
次の文を使用して、テーブルを作成し、データを挿入できます。
-- テーブルの作成 CREATE TABLE `es_test` ( `id` bigint(32) NOT NULL, `name` varchar(32) NULL, `age` bigint(32) NULL, `hobby` varchar(32) NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARACTER SET=utf8; -- データの挿入 INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (1,'user1',22,'music'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (2,'user2',23,'sport'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (3,'user3',43,'game'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (4,'user4',24,'run'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (5,'user5',42,'basketball');
ステップ2:リソースグループの購入と設定
Data Integration リソースグループを購入し、それに VPC とワークスペースをアタッチします。
DataWorks コンソールにログインします。
トップメニューバーでリージョンを選択します。左側のナビゲーションウィンドウで、[リソースグループ] をクリックします。
[リソースグループの作成] をクリックし、必須パラメーターを設定します。
作成したリソースグループの [操作] 列で、[ネットワーク設定] をクリックして、リソースグループに VPC をアタッチします。詳細については、「ネットワーク設定」をご参照ください。
リソースグループは、データを同期するために ApsaraDB RDS for MySQL および ES インスタンスの VPC に接続できる必要があります。[VPC]、[ゾーン]、および [VSwitch] を、ApsaraDB RDS for MySQL および ES インスタンスが属するものにアタッチする必要があります。インスタンスの VPC 情報を表示するには、「ApsaraDB RDS for MySQL インスタンスの VPC と vSwitch の切り替え」および「Elasticsearch インスタンスの基本情報の表示」をご参照ください。
重要VPC をアタッチした後、VPC の [VSwitch CIDR ブロック] を ApsaraDB RDS for MySQL および ES インスタンスの内部向けホワイトリストに追加する必要があります。詳細については、「ApsaraDB RDS for MySQL インスタンスの IP アドレスホワイトリストの設定」および「ES インスタンスのパブリックまたは内部向けアクセスホワイトリストの設定」をご参照ください。
ページの左上隅にある戻るアイコンをクリックして、[リソースグループ] ページに戻ります。
作成したリソースグループの [操作] 列で、[ワークスペースのアタッチ] をクリックして、ターゲットワークスペースをリソースグループにアタッチします。
ステップ3:データソースの追加
ApsaraDB RDS for MySQL と ES のデータソースを DataWorks の Data Integration サービスに追加します。
DataWorks の [Data Integration] ページに移動します。
DataWorks コンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。
ターゲットワークスペースの [操作] 列で、 を選択します。
左側のナビゲーションウィンドウで、[データソース] をクリックします。
MySQL データソースを追加します。
[データソースリスト] ページで、[データソースの追加] をクリックします。
[データソースの追加] ページで、[MySQL] を検索して選択します。
[MySQL データソースの追加] ダイアログボックスで、[基本情報] セクションのデータソースパラメーターを設定します。
設定の詳細については、「MySQL データソースの設定」をご参照ください。
[接続設定] セクションで、[接続テスト] をクリックします。接続ステータスが [接続済み] の場合、接続は成功です。
[完了] をクリックします。
同様の方法で ES データソースを追加します。設定の詳細については、「ES データソースの設定」をご参照ください。
ステップ4:オフラインデータ同期タスクの設定と実行
オフラインデータ同期タスクは、リソースグループを使用して実行されます。リソースグループは Data Integration のデータソースからデータを取得し、そのデータを ES クラスターに書き込みます。
オフライン同期タスクは 2 つの方法で設定できます。このトピックでは、コードレス UI を例として説明します。コードエディタを使用してオフライン同期タスクを設定することもできます。詳細については、「コードエディタでの同期ノードの設定」、「MySQL Reader」、および「Elasticsearch Writer」をご参照ください。
このトピックでは、旧バージョンの Data Studio ページを例に、オフライン同期タスクの作成方法を説明します。
DataWorks の [データ開発] ページに移動します。
DataWorks コンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。
ターゲットワークスペースの [操作] 列で、 を選択します。
オフライン同期タスクを作成します。
左側のナビゲーションウィンドウの [データ開発] (
 アイコン) タブで、 を選択します。画面の指示に従ってビジネスフローを作成します。
アイコン) タブで、 を選択します。画面の指示に従ってビジネスフローを作成します。作成したビジネスフローを右クリックし、 を選択します。
[ノードの作成] ダイアログボックスで、ノード名を入力し、[確認] をクリックします。
ネットワークとリソースを設定します。
[データソース] セクションで、[データソース] を [MySQL] に、[データソース名] をデータを同期するデータソースの名前に設定します。
[マイリソースグループ] セクションで、リソースグループを選択します。
[データ宛先] セクションで、[データ宛先] を Elasticsearch に、[データソース名] をデータを同期するデータソースの名前に設定します。
[次へ] をクリックします。
タスクを設定します。
[データソース] セクションで、データを同期するテーブルを選択します。
[データ宛先] セクションで、データ宛先のパラメーターを設定します。
[フィールドマッピング] セクションで、[ソースフィールド] と [宛先フィールド] の間のマッピング関係を設定します。
[チャネル制御] セクションで、チャネルパラメーターを設定します。
設定の詳細については、「コードレス UI での同期ノードの設定」をご参照ください。
タスクを実行します。
(オプション) タスクのスケジューリングプロパティを設定します。右側のペインで [スケジューリング] をクリックし、必要に応じてスケジューリングパラメーターを設定します。パラメーターの詳細については、「スケジューリング」をご参照ください。
ノードエリアの左上隅にある保存アイコンをクリックして、タスクを保存します。
ノードエリアの左上隅にあるコミットアイコンをクリックして、タスクをコミットします。
タスクにスケジューリングプロパティを設定した場合、タスクは定期的に自動実行されます。ノードエリアの左上隅にある実行アイコンをクリックして、タスクをすぐに実行することもできます。
ログに
Shell run successfully!が含まれている場合、タスクが正常に実行されたことを示します。
ステップ5:データ同期結果の検証
宛先の Alibaba Cloud ES インスタンスの Kibana コンソールにログインします。詳細については、「Kibana コンソールへのログイン」をご参照ください。
Kibana ページの左上隅にあるアイコンをクリックし、[開発ツール] を選択します。
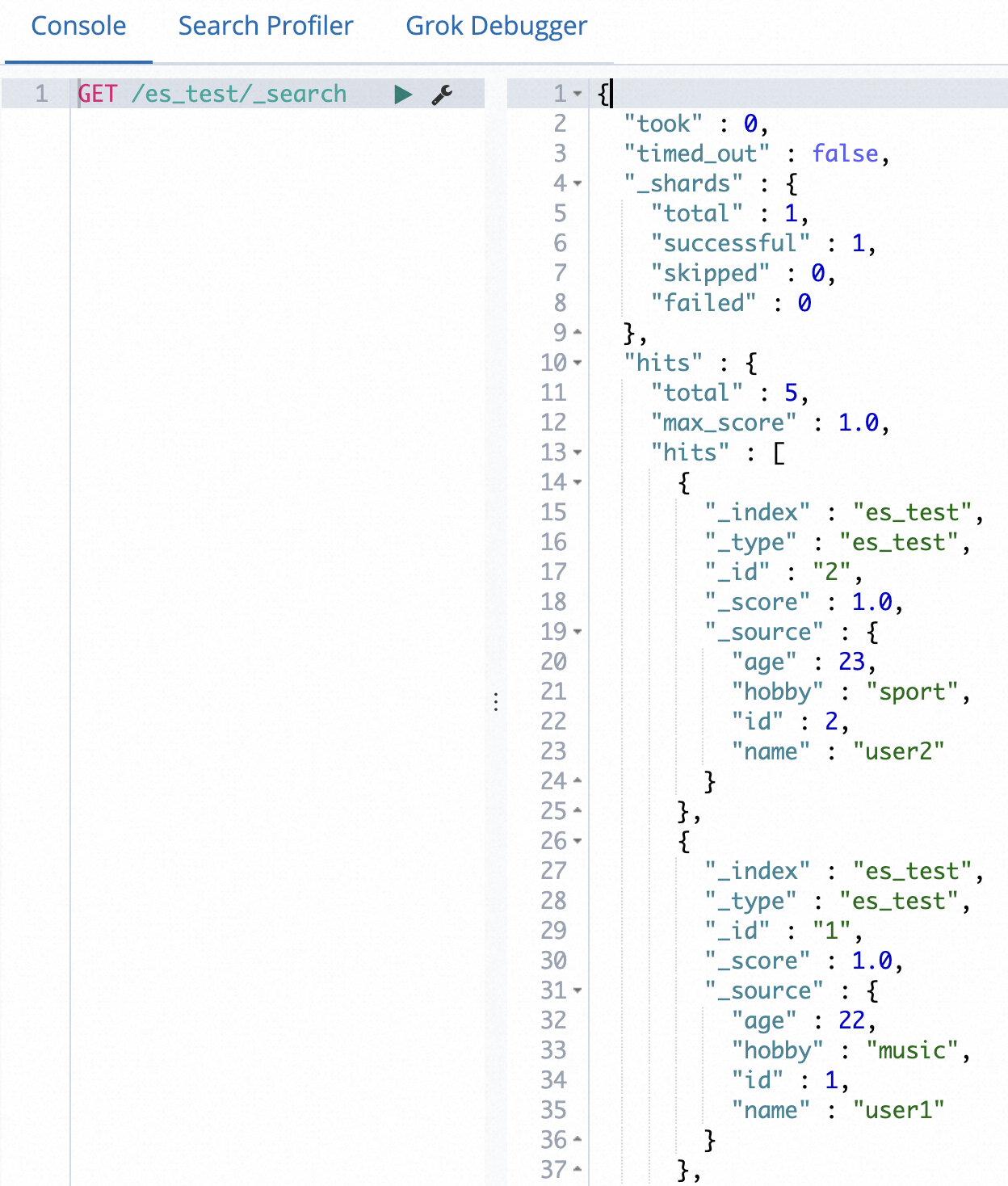
[コンソール] で、次のコマンドを実行して同期されたデータを表示します。
POST /es_test/_search?pretty { "query": { "match_all": {}} }説明es_testをデータ同期タスクで指定したインデックス名に置き換えてください。データが正常に同期されると、次の結果が返されます。