Alibaba Cloud E-MapReduce (EMR) では、DataServingクラスターのデータをHadoop分散ファイルシステム (HDFS) のOSS-HDFSおよびWALログに保存できます。 このトピックでは、OSS-HDFSをHBaseのストレージバックエンドとして使用する方法について説明します。
背景情報
OSS-HDFSは、クラウドネイティブのデータレイクストレージサービスです。 OSS-HDFSは統合メタデータ管理機能を提供し、HDFS APIと完全に互換性があります。 OSS-HDFSはまた携帯用オペレーティングシステムインターフェイス (POSIX) を支えます。 OSS-HDFSにより、ビッグデータおよびAI分野のさまざまなデータレイクベースのコンピューティングシナリオでデータを管理できます。 詳細については、「概要」をご参照ください。
制限事項
この機能は、EMR V3.42、EMR V5.8.0、およびそれ以降のマイナーバージョンのDataServingクラスターでのみサポートされます。
手順
OSS-HDFSを有効にし、アクセス権限を付与します。 詳細については、「OSS-HDFSの有効化とアクセス許可の付与」をご参照ください。
OSS-HDFSのエンドポイントを取得します。
Object Storage Service (OSS) コンソールのバケットの [概要] ページで、OSS-HDFSのドメイン名をコピーします。 この方法では、EMR hbaseクラスターを作成するときに、HBase. rootdirパラメーターの値としてドメイン名を使用できます。

OSS-HDFSを使用します。
DataServingクラスターを作成します。 詳細については、「クラスターの作成」をご参照ください。
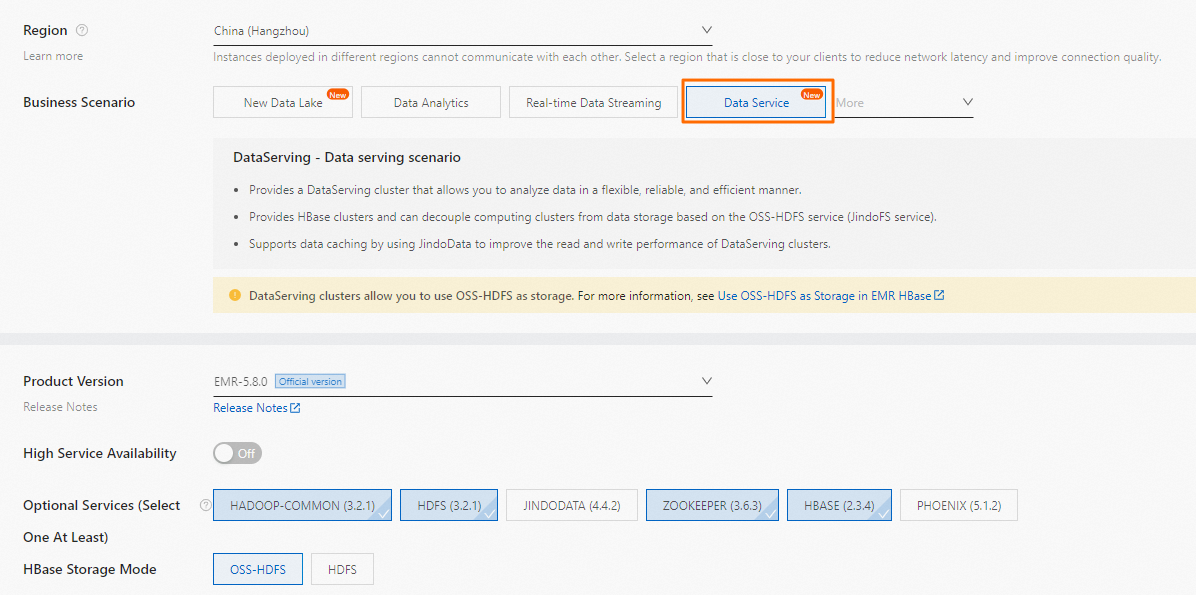 クラスター作成時に次のパラメーターを設定します。
クラスター作成時に次のパラメーターを設定します。オプションサービス (少なくとも1つ選択): JindoData以外のすべてのオプションを選択します。
HBaseストレージモード: [OSS-HDFS] を選択します。
ルートディレクトリ: OSS-HDFSが有効になっているOSSバケットのディレクトリを入力します。 ディレクトリはoss://${OSS-HDFSエンドポイント}/${dir} 形式です。 例: oss:// test_bucket.cn-hangzhou.oss-dls.aliyuncs.com/hbase。
説明実際の運用では、次の項目に注意してください。
${OSS-HDFSエンドポイント} を、ステップ2で取得したOSS-HDFSのエンドポイントに置き換えます。
${dir} をHBaseのルートディレクトリに置き換えます。
HBaseテーブルを作成します。
DataServingクラスターにログインします。 詳細については、「クラスターへのログイン」をご参照ください。
次のコマンドを実行してHBaseシェルにアクセスします。
hbaseシェル次のコマンドを実行して、fという名前の列ファミリを持つbarという名前のHBaseテーブルを作成します。
作成 'bar' 、'f'listコマンドを実行して、HBaseテーブルに関する情報を表示します。次の情報が返されます。
かかりましたテーブル バー 1行 0.0138秒
HBaseシェルを終了し、次のコマンドを実行してHBaseテーブルのデータを確認し。
構文:
hadoop fs -ls oss://${OSS-HDFSエンドポイント}/{dir}例:
hadoop fs -ls oss:// test_bucket.cn-hangzhou.oss-dls.aliyuncs.com/hbase/data/default次の出力と同様の情報が返された場合、HBaseテーブルはOSS-HDFSで作成されます。
が1商品見つかりました drwxrwxrwx - hbaseスーパーグループ0 2022-07-28 14:45 oss:// test_bucket.cn-hangzhou.oss-dls.aliyuncs.com/hbase/data/default/bar
オプション: EMR HBaseクラスターを削除し、新しいクラスターを作成します。
EMR HBaseクラスターのデータがOSS-HDFSに保存された後、クラスターを削除し、OSS-HDFSが有効になっているOSSバケットのディレクトリに新しいクラスターを作成できます。
重要削除されたクラスターと新しいクラスターのHBaseバージョンは同じである必要があります。 そうしないと、新しいクラスターで非互換性などの問題が発生し、新しいクラスターが使用できなくなる可能性があります。

1つのディレクトリで同時に使用できるHBaseクラスターは1つだけです。 一度にディレクトリ内の複数のHBaseクラスターにデータを書き込むと、クラスターに書き込まれたメタデータまたはデータが元のものと異なる場合があり、クラスターが使用できなくなります。
DataServingクラスターにログインします。 詳細については、「クラスターへのログイン」をご参照ください。
次のコマンドを実行してHBase Shellにアクセスします。
hbaseシェル次のコマンドを実行してFLUSH操作を実行します。 これにより、メモリ内のすべてのテーブルのデータがHFileにフラッシュされます。
フラッシュ「バー」次のコマンドを実行して、関連テーブルを無効にします。 これにより、新しいデータがテーブルに書き込まれるのを防ぎます。
'bar' を無効にする削除されたクラスターと同じバージョンのHbaseを持つ新しいクラスターを作成します。 データを格納する新しいクラスターに同じディレクトリを指定します。

新しいクラスターが作成された後も、OSS-HDFSに保存されているデータを引き続き使用できます。