このトピックでは、Hive クライアント、Beeline、および Java Database Connectivity (JDBC) を使用して E-MapReduce (EMR) クラスタの Hive に接続する方法について説明します。
前提条件
Hive を含む EMR クラスタが作成され、クラスタのマスターノードで [パブリックネットワーク IP の割り当て] スイッチがオンになっています。クラスタの作成方法については、「クラスタを作成する」をご参照ください。
共通クラスタ: [kerberos 認証] と [高サービス可用性] がオンになっていないクラスタ。
高セキュリティクラスタ: [kerberos 認証] がオンになっているクラスタ。
高可用性クラスタ: [高サービス可用性] がオンになっているクラスタ。高可用性クラスタを作成する場合は、ZooKeeper を選択する必要があります。
クラスタのマスターノードにログインしています。詳細については、「クラスタにログインする」をご参照ください。
注意事項
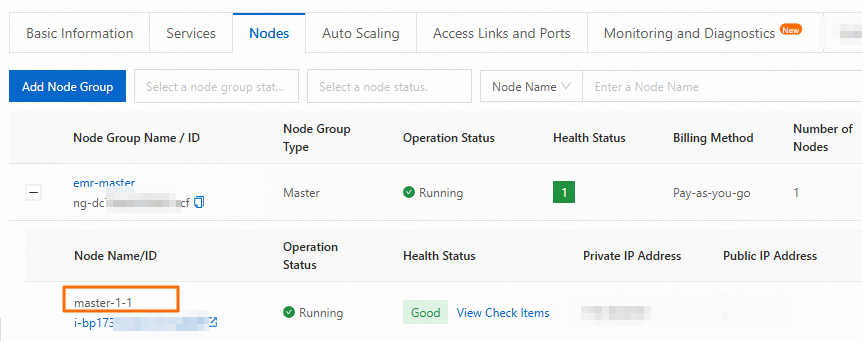
[ノード] タブで、クラスタのマスターノードの名前とパブリック IP アドレスを取得できます。詳細については、「クラスタにログインする」をご参照ください。
ほとんどの場合、マスターノードの名前は master-1-1 です。クラスタが Hadoop クラスタの場合、マスターノードの名前は emr-header-1 です。
デフォルトでは、HiveServer2 はユーザー名とパスワードを検証しません。ユーザー名とパスワードを認証する必要がある場合は、Lightweight Directory Access Protocol (LDAP) 認証を有効にする必要があります。詳細については、「LDAP 認証を使用する」をご参照ください。
手順
共通クラスタ
Hive クライアントを使用して Hive に接続する
次のコマンドを実行して Hive に接続します。
hiveオプション。
quit;またはexit;コマンドを実行して、Hive クライアントを終了します。
Beeline クライアントを使用して Hive に接続する
次のコマンドを実行して Hive に接続します。
beeline -u jdbc:hive2://master-1-1:10000オプション。
!quitまたは!exitコマンドを実行して、Beeline クライアントを終了します。
Hive への JDBC 接続を使用する
次の手順を実行する前に、Java 環境をセットアップし、Java プログラミングツールをインストールし、環境変数を構成していることを確認してください。
pom.xmlファイルで hadoop-common および hive-jdbc プロジェクトの依存関係を構成します。例:<dependencies> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>3.1.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.2.1</version> </dependency> </dependencies>hadoop-common および hive-jdbc のバージョン情報が、EMR クラスタの [hadoop-common] および [hive] のバージョン情報と一致していることを確認してください。Hadoop-Common および Hive のバージョン情報は、EMR コンソールのクラスタの [ソフトウェア情報] セクションの [基本情報] タブで確認できます。
HiveServer2 に接続し、Hive テーブルのデータに対して操作を実行するコードを記述します。サンプルコード:
import java.sql.*; public class App { private static String driverName = "org.apache.hive.jdbc.HiveDriver"; public static void main(String[] args) throws SQLException { try { Class.forName(driverName); } catch (ClassNotFoundException e) { e.printStackTrace(); } Connection con = DriverManager.getConnection( "jdbc:hive2://<マスターノードのパブリック IP アドレス>:10000", "root", ""); Statement stmt = con.createStatement(); String sql = "select * from sample_tbl limit 10"; ResultSet res = stmt.executeQuery(sql); while (res.next()) { System.out.println(res.getString(1) + "\t" + res.getString(2)); } } }説明ポート 10000 を有効にする必要があります。詳細については、「セキュリティグループを管理する」をご参照ください。
プロジェクトをパッケージ化して JAR ファイルを生成し、JAR ファイルを実行するためにホストにアップロードします。
重要JAR ファイルを実行するには、hadoop-common および hive-jdbc の依存関係が必要です。ホストの環境変数に 2 つの依存関係が構成されていない場合は、ホストに依存関係をダウンロードして構成する必要があります。または、2 つの依存関係とプロジェクトを同じ JAR ファイルにパッケージ化することもできます。JAR ファイルの実行時に依存関係のいずれかが欠落している場合は、エラーメッセージが表示されます。
hadoop-commonが欠落している場合は、「java.lang.NoClassDefFoundError: org/apache/hadoop/conf/Configuration」というエラーメッセージが表示されます。hive-jdbcが欠落している場合は、「java.lang.ClassNotFoundException: org.apache.hive.jdbc.HiveDriver」というエラーメッセージが表示されます。
この例では、
emr-hiveserver2-1.0.jarという JAR ファイルが生成されます。このファイルを EMR クラスタの master-1-1 ノードにアップロードする必要があります。JAR ファイルが正しく実行できるかどうかを確認します。
重要EMR クラスタと同じ Virtual Private Cloud (VPC) およびセキュリティグループにあるホストで JAR ファイルを実行することをお勧めします。ホストと EMR クラスタが相互に通信できることを確認してください。ホストと EMR クラスタが異なる VPC にある場合、または異なるネットワークタイプの場合は、インターネット経由でのみ通信できます。この場合、Alibaba Cloud ネットワークサービスを使用して接続する必要があります。こうすることで、内部ネットワーク経由で通信できます。次の方法を使用して接続性をテストします。
インターネット:
telnet master-1-1 ノードのパブリック IP アドレス 10000内部ネットワーク:
telnet master-1-1 ノードの内部 IP アドレス 10000
java -jar emr-hiveserver2-1.0.jar
高セキュリティクラスタ
Hive クライアントを使用して Hive に接続する
Kerberos の admin.local CLI を開きます。
Key Distribution Center (KDC) サーバーが存在する master-1-1 ノードに root ユーザーとしてログインしている場合は、次のコマンドを実行して admin.local CLI を開きます。KDC は Kerberos サーバーです。
kadmin.local出力に次の情報が含まれている場合、admin.local CLI が開かれています。
Authenticating as principal hadoop/admin@EMR.C-85D4B8D74296****.COM with password. kadmin.local:master-1-1 以外のノードにログインしている場合、またはゲートウェイを使用している場合は、次のコマンドを実行して admin.local CLI を開きます。admin-user パラメーターと admin-password パラメーターを実際のユーザー名とパスワードに置き換えます。
kadmin -p <admin-user> -w <admin-password>説明EMR でセルフマネージド KDC サーバーを使用する場合は、次の項目に注意してください。
<admin-user>: 値をroot/adminに設定します。<admin-password>: [admin_pwd] パラメーターの値を入力します。この値は、EMR コンソールの Kerberos サービスの [構成] タブで取得できます。
出力に次の情報が含まれている場合、admin.local CLI が開かれています。
Authenticating as principal root/admin with password. kadmin:
test という名前のプリンシパルを作成します。
この例では、パスワードは 123456 です。
addprinc -pw 123456 test出力に次の情報が含まれている場合、プリンシパルが作成されています。
Principal "test@EMR.C-85D4B8D74296****.COM" created.説明チケット交付チケット (TGT) を作成するときに必要なユーザー名とパスワードを記録する必要があります。
admin.local CLI を終了するには、
quitコマンドを実行します。Hive クライアントを実行するノードにログインします。次のコマンドを実行して、test という名前のユーザーを作成し、切り替えます。
useradd test su test次のコマンドを実行して TGT を作成します。
kinitEnter キーを押して、test ユーザーのパスワードを入力します。この例では、パスワードは 123456 です。
hiveコマンドを実行して、Hive クライアントに接続します。hive
Beeline クライアントを使用して Hive に接続する
Kerberos の admin.local CLI を開きます。
Key Distribution Center (KDC) サーバーが存在する master-1-1 ノードに root ユーザーとしてログインしている場合は、次のコマンドを実行して admin.local CLI を開きます。KDC は Kerberos サーバーです。
kadmin.local出力に次の情報が含まれている場合、admin.local CLI が開かれています。
Authenticating as principal hadoop/admin@EMR.C-85D4B8D74296****.COM with password. kadmin.local:master-1-1 以外のノードにログインしている場合、またはゲートウェイを使用している場合は、次のコマンドを実行して admin.local CLI を開きます。admin-user パラメーターと admin-password パラメーターを実際のユーザー名とパスワードに置き換えます。
kadmin -p <admin-user> -w <admin-password>説明EMR でセルフマネージド KDC サーバーを使用する場合は、次の項目に注意してください。
<admin-user>: 値をroot/adminに設定します。<admin-password>: [admin_pwd] パラメーターの値を入力します。この値は、EMR コンソールの Kerberos サービスの [構成] タブで取得できます。
出力に次の情報が含まれている場合、admin.local CLI が開かれています。
Authenticating as principal root/admin with password. kadmin:
test という名前のプリンシパルを作成します。
この例では、パスワードは 123456 です。
addprinc -pw 123456 test出力に次の情報が含まれている場合、プリンシパルが作成されています。
Principal "test@EMR.C-85D4B8D74296****.COM" created.説明チケット交付チケット (TGT) を作成するときに必要なユーザー名とパスワードを記録する必要があります。
admin.local CLI を終了するには、
quitコマンドを実行します。Hive クライアントを実行するノードにログインします。次のコマンドを実行して、test という名前のユーザーを作成し、切り替えます。
useradd test su test次のコマンドを実行して TGT を作成します。
kinitEnter キーを押して、test ユーザーのパスワードを入力します。この例では、パスワードは 123456 です。
次のコマンドを実行して Hive クライアントに接続します。
beeline -u "jdbc:hive2://master-1-1.c-56187feb57f0****.cn-hangzhou.emr.aliyuncs.com:10000/;principal=hive/_HOST@EMR.c-56187feb57f0****.COM"ビジネス要件に基づいて次の情報を置き換えます。
master-1-1.c-56187feb57f0****.cn-hangzhou.emr.aliyuncs.com: ドメイン名を含む完全修飾ホスト名。ホスト名は、HiveServer2 サービスがデプロイされているノードでhostname -fコマンドを実行することで取得できます。このサービスは、ほとんどの場合、master-1-1 ノードにデプロイされています。EMR.c-56187feb57f0****.COM: レルム名。レルム パラメーターは、EMR コンソールの Kerberos サービス ページの 構成する タブで検索できます。このパラメーターの値がレルム名です。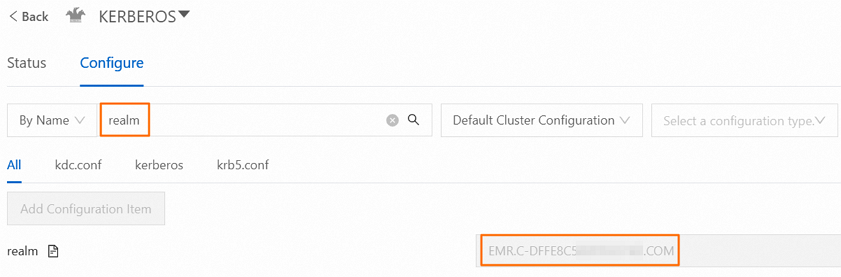
高可用性クラスタ
Beeline クライアントを使用して Hive に接続する
選択したサービス検出モードに基づいて、対応するコマンドを実行して JDBC を使用して Hive に接続します。
ZooKeeper
beeline -u 'jdbc:hive2://master-1-1:2181,master-1-2:2181,master-1-3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2'マルチサーバー
beeline -u 'jdbc:hive2://master-1-1:10000,master-1-2:10000,master-1-3:10000/default;serviceDiscoveryMode=multiServers'