Alibaba Cloud E-MapReduce (EMR) on ACK provides a new platform that you can use to develop and run big data jobs. You can deploy open source big data services on top of Alibaba Cloud Container Service for Kubernetes (ACK). You can use ACK to deploy services and manage containerized applications. This reduces the O&M costs of underlying cluster resources and helps you focus on big data jobs.
Comparison between EMR on ECS and EMR on ACK
To meet the requirements of different users, Alibaba Cloud provides EMR on ECS and EMR on ACK.
If you use an EMR cluster that is hosted on Elastic Compute Service (ECS) instances to run jobs, you can also run your Spark and Presto jobs on an ACK cluster. This way, different applications can share one ACK cluster, and computing resources are shared across zones.
If you run big data jobs, such as Spark and Presto jobs, on ACK clusters, EMR on ACK can automatically deploy and manage the clusters. If EMR on ACK is used together with EMR Shuffle Service, the performance of Spark jobs can be significantly improved.
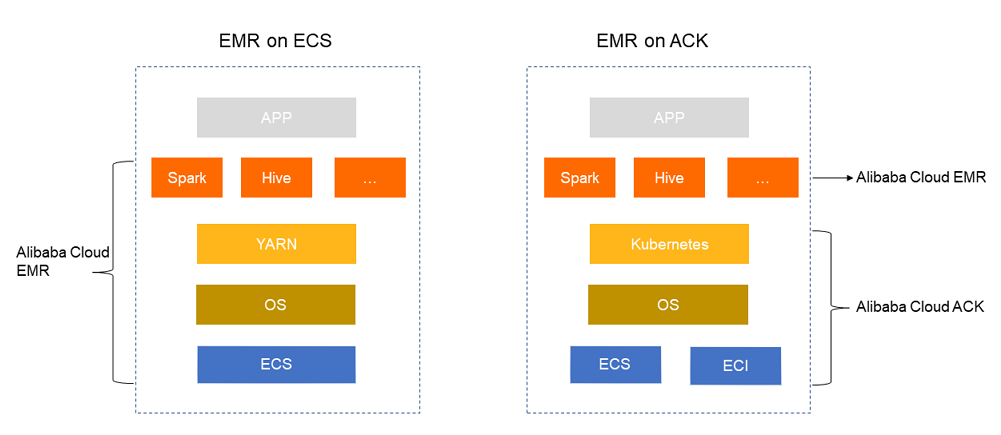
Item | Description |
EMR on ECS | When you create an EMR cluster, the EMR system deploys components of the open source Hadoop ecosystem on ECS instances based on your configurations and starts the components as services in the cluster. You can perform O&M operations on the services and ECS instances of the EMR cluster in the EMR console. When you run big data jobs, the jobs are committed to EMR clusters. |
EMR on ACK | Before you use EMR on ACK, make sure that an ACK cluster is deployed. After the ACK cluster is deployed, you can create an EMR cluster to deploy big data components based on ACK resources and run the components in related containers. |
Advantages of EMR on ACK
Advantage | Description |
Cost-effectiveness | You can run big data jobs on existing ACK clusters based on simple configurations without the need to purchase ACK clusters for big data components. This reduces costs. You can use the idle resources of an existing ACK cluster to run EMR jobs, such as Spark and Presto jobs, with a few clicks. Big data and online applications can share cluster resources. Cluster resources can be fully utilized in scenarios in which both online and offline jobs are run. In addition, big data and online applications can share cluster resources to maximize resource utilization. |
Simplified O&M | A unified O&M and cluster management system is provided for both big data and online business. This simplifies O&M. |
Optimized user experience | The EMR console provides the following Infrastructure as a Service (IaaS) models: EMR on ECS and EMR on ACK. You can seamlessly switch between the two models. ACK and Elastic Container Instance allow you to obtain elastic computing resources within a short period of time. This ensures that computing resources are sufficient during peak hours. You can adjust the version of Spark at the job level to adapt to new features and different business requirements. |
Deep integration | EMR on ACK adopts a cloud-native data lake architecture. The architecture integrates ACK to scale out computing resources without a limit, integrates Object Storage Service (OSS) to separate computing resources from storage resources, and integrates Data Lake Formation (DLF) to help you build data lakes. |