Data Transmission Service (DTS) の使用中にエラーメッセージが表示された場合は、「一般的なエラー」をご参照ください。特定のエラーメッセージが表示されない場合は、以下のカテゴリから問題を特定してください。
問題のカテゴリ
一般的な問題は、以下のカテゴリに分類されます。
事前チェックに関する問題の詳細については、「事前チェックとトラブルシューティング方法」をご参照ください。
課金に関する問題
DTS の課金方法について
DTS には、サブスクリプションと従量課金の 2 種類の課金方法があります。詳細については、「課金の概要」をご参照ください。
DTS の請求書の確認方法
DTS の請求書の確認方法については、「請求書の確認」をご参照ください。
DTS インスタンスを一時停止した後も課金されますか?
移行インスタンスは、一時停止中は課金されません。
データ同期インスタンスは、一時停止中でも課金されます。これは、データベースに接続できるかどうかに関係なく、DTS がターゲットデータベースへのデータ書き込みのみを一時停止しているためです。DTS は引き続きリソース(CPU やメモリなど)を消費して、データベースへの継続的な接続やソースデータベースからのログ取得を行います。これにより、再開時に迅速に処理を再開できます。
データ同期の料金がデータ移行よりも高い理由
データ同期の料金が高いのは、オンラインでの同期オブジェクトの調整や MySQL データベース間の双方向同期などの高度な機能が含まれているためです。また、データ同期では内部ネットワークを使用して転送を行うため、ネットワーク遅延が低くなります。
アカウントの支払いが滞納した場合の影響
支払い滞納の影響については、「有効期限切れまたは支払い滞納」をご参照ください。
サブスクリプションベースのタスクを早期にリリースする方法
これを行うには、まずサブスクリプションタスクを従量課金タスクに変換してから、サブスクリプションを解除する必要があります。変換方法の詳細については、「課金方法の切り替え」をご参照ください。
サブスクリプションタスクを従量課金に変換できますか?
はい、可能です。詳細については、「課金方法の切り替え」をご参照ください。
従量課金タスクをサブスクリプションに変換できますか?
データ同期または追跡タスクの課金方法を切り替えることができます。詳細については、「課金方法の切り替え」をご参照ください。
データ移行タスクは、従量課金方式のみをサポートしています。
DTS タスクの課金が突然開始された理由
無料トライアル期間が終了した可能性があります。DTS では、Alibaba Cloud 独自のデータベースエンジンを宛先として使用するタスクに対して、期間限定の無料トライアルを提供しています。無料トライアル終了後は、自動的に課金が開始されます。
リリース済みのタスクに対して課金が継続される理由
DTS では、従量課金タスクを日単位で課金します。リリース当日に DTS タスクを使用していた場合、その日の利用料金が発生します。
従量課金の仕組み
DTS では、増分タスクが正常に動作している間のみ課金されます(増分同期中の一時停止を含みますが、増分移行中の一時停止は除きます)。詳細については、「課金方法」をご参照ください。
DTS はデータ転送料金を請求しますか?
一部の DTS タスクでは、ソースおよびターゲットリージョンに関係なく、パブリックネットワークおよびデータ転送料金が発生します。移行タスクでは、ターゲットデータベースの アクセス方法 が パブリック IP アドレス に設定されている場合、パブリックネットワークトラフィック料金が発生します。行サンプリングによるフルフィールド検証 モードを使用する完全検証タスクでは、検証されたデータ量に基づいてデータ転送料金が発生します。詳細については、「課金項目」をご参照ください。
パフォーマンスおよび仕様に関する問題
インスタンス仕様の違い
インスタンス仕様の違いについては、「データ移行リンク仕様」および「データ同期リンク仕様」をご参照ください。
インスタンス仕様をアップグレードできますか?
はい、可能です。詳細については、「インスタンスリンク仕様のアップグレード」をご参照ください。
インスタンス仕様をダウングレードできますか?
現在、同期インスタンスのみがサポートされています。詳細については、「インスタンスリンクのダウングレード仕様」をご参照ください。
DTS タスクをダウングレード(仕様を下げること)できますか?
対象となる DTS タスクでは、ダウングレード(リンク仕様の縮小)がサポートされています。詳細については、「インスタンスリンク仕様のダウングレード」をご参照ください。
DTS タスクをミディアム仕様より下にダウングレードできますか?
サポートされていません。
データ同期または移行にかかる時間
DTS タスクのパフォーマンスは、DTS の内部処理、ソースおよびターゲットデータベースの負荷、データ量、増分タスクの実行状況、ネットワーク状況など、複数の要因に依存します。そのため、タスクの正確な所要時間を推定することはできません。高いパフォーマンスが必要な場合は、より高い仕様のインスタンスを選択してください。仕様の詳細については、「データ移行リンク仕様」および「データ同期リンク仕様」をご参照ください。
データ移行または同期タスクのパフォーマンスメトリクスの確認方法
パフォーマンスメトリクスの確認方法については、「増分移行リンクのステータスとパフォーマンスの確認」または「同期リンクのステータスとパフォーマンスの確認」をご参照ください。
コンソールで特定の DTS インスタンスが見つからない理由
考えられる原因:サブスクリプション DTS インスタンスの有効期限が切れ、リリースされています。
選択したリソースグループが正しくありません。アカウント配下のすべてのリソース を選択してください。
誤ったリージョンを選択している可能性があります。選択したリージョンが宛先インスタンスが配置されているリージョンであることを確認してください。
タスクタイプを誤って選択している可能性があります。正しいタスクリストページを表示していることを確認してください。たとえば、同期インスタンスは データ同期タスク リストにのみ表示されます。
有効期限切れまたは支払い滞納によりインスタンスがリリースされています。DTS インスタンスの有効期限が切れたり、支払いが滞納されたりすると、データ転送タスクは停止します。7 日以内にアカウントに資金を追加しない場合、システムはインスタンスをリリースして削除します。詳細については、「有効期限切れおよび支払い滞納」をご参照ください。
事前チェックに関する問題
Redis の立ち退きポリシー事前チェックでアラートが表示される理由
ターゲットデータベースの立ち退きポリシー (maxmemory-policy) が noeviction 以外に設定されている場合、ソースデータベースとターゲットデータベースの間にデータ不整合が発生する可能性があります。立ち退きポリシーの詳細については、「Redis データ立ち退きポリシーの紹介」をご参照ください。
増分データ移行中に Binlog 関連の事前チェックが失敗した場合の対処方法
ソースデータベースのバイナリログが有効になっており、期待通りに動作しているかどうかを確認してください。詳細については、「ソースデータベースのバイナリログチェック」をご参照ください。
データベース接続に関する問題
ソースデータベースの接続に失敗した場合の対処方法
ソースデータベースの情報および設定が正しく構成されているかどうかを確認してください。詳細については、「ソースデータベースの接続性チェック」をご参照ください。
ターゲットデータベースの接続に失敗した場合の対処方法
ターゲットデータベースの情報および設定が正しく構成されているかどうかを確認してください。詳細については、「ターゲットデータベースの接続性チェック」をご参照ください。
ソースまたはターゲットインスタンスが DTS でまだサポートされていないリージョンにある場合のデータ移行または同期方法
データ移行タスクの場合、データベースインスタンス(RDS MySQL など)にパブリック IP アドレスを取得し、パブリック IP を使用してインスタンスに接続します。DTS がサポートするリージョンをインスタンス用に選択し、対応する DTS サーバーの IP アドレス範囲をインスタンスのホワイトリストに追加します。必要な IP アドレスについては、「DTS サーバーの IP アドレスをホワイトリストに追加」をご参照ください。
データ同期タスクの場合、同期は現在 パブリック IP を使用したデータベースインスタンスへの接続をサポートしていないため、これらのリージョンでの同期はサポートされていません。
データ同期に関する問題
DTS が同期をサポートするデータベースインスタンス
DTS は、リレーショナルデータベース管理システム (RDBMS)、NoSQL データベース、オンライン分析処理 (OLAP) データベースなど、さまざまなデータソース間のデータ同期をサポートしています。サポートされているデータベースインスタンスの詳細については、「同期シナリオの概要」をご参照ください。
データ移行とデータ同期の違い
次の表は、データ移行とデータ同期の違いを示しています。
自己管理データベース:DTS インスタンスを構成する際に、アクセス方法 が Alibaba Cloud インスタンス ではないデータベースインスタンス。自己管理データベースには、サードパーティクラウドデータベース、オンプレミスデータベース、ECS インスタンスにデプロイされたデータベースが含まれます。
比較項目 | データ移行 | データ同期 |
ユースケース | 主にクラウド移行に使用されます。たとえば、オンプレミスデータベース、ECS インスタンス上の自己管理データベース、またはサードパーティクラウドデータベースを Alibaba Cloud データベースに移行できます。 | 主に 2 つのデータソース間のリアルタイムデータ同期に使用されます。これは、アクティブ地理的冗長性、データディザスタリカバリ、クロスボーダーデータ同期、クエリおよびレポートのオフロード、クラウドビジネスインテリジェンス (BI)、リアルタイムデータウェアハウスなどのシナリオに適しています。 |
サポートされるデータベース | 詳細については、「移行シナリオの概要」をご参照ください。 説明 データ同期でサポートされていない一部のデータベースについては、データ移行を使用して同期を実現できます。例:スタンドアロン MongoDB データベースおよび OceanBase (MySQL モード) データベース。 | 詳細については、「同期シナリオの概要」をご参照ください。 |
サポートされるデータベースデプロイメント場所(接続タイプ) |
|
説明 データ同期では内部ネットワークを使用して転送を行うため、ネットワーク遅延が低くなります。 |
機能の違い |
|
|
課金方法 | 従量課金方式のみをサポートします。 | 従量課金およびサブスクリプションの両方の課金方法をサポートします。 |
課金対象ですか? | 増分移行タスクを持つ移行インスタンスのみが課金対象です。 | はい。同期インスタンスにはデフォルトで増分同期が含まれるため、常に課金されます。 |
課金ルール | 増分データ移行タスクが実行されている場合にのみ課金されます。一時停止中のタスクは課金されません。スキーマ移行または完全なデータ移行中は課金されません。 |
|
データ同期の仕組み
データ同期の仕組みの詳細については、「サービスアーキテクチャと機能原理」をご参照ください。
同期遅延の計算方法
同期遅延は、ターゲットデータベースに同期された最新のデータエントリのタイムスタンプと、ソースデータベースの現在のタイムスタンプとの差(ミリ秒単位)です。
通常の遅延は 1,000 ミリ秒未満です。
実行中の同期タスクで同期オブジェクトを変更できますか?
はい、可能です。同期オブジェクトの変更方法については、「同期オブジェクトの追加」および「同期オブジェクトの削除」をご参照ください。
既存の同期タスクに新しいテーブルを追加できますか?
はい、可能です。新しいテーブルの追加方法については、「同期オブジェクトの追加」をご参照ください。
実行中の同期タスクでテーブルおよびフィールドを変更する方法
完全同期フェーズが完了し、タスクが増分同期フェーズに入った後に同期オブジェクトを変更できます。手順については、「同期オブジェクトの追加」および「同期オブジェクトの削除」をご参照ください。
同期タスクを一時停止して後で再開した場合、データ不整合が発生しますか?
タスクの一時停止中にソースデータベースのデータが変更された場合、ソースデータベースとターゲットデータベースの間にデータ不整合が発生する可能性があります。タスクを再開して増分データが同期されると、ターゲットデータベースのデータはソースデータベースのデータと一致します。
増分同期タスクのソースデータベースからデータを削除した場合、ターゲットデータベースの同期データも削除されますか?
同期する DML 操作に delete が含まれていない場合、ターゲットではデータが削除されません。それ以外の場合、ターゲットの対応するデータが削除されます。
Redis-to-Redis 同期中に、ターゲット Redis インスタンスのデータは上書きされますか?
はい、同じキーを持つデータは上書きされます。DTS は事前チェック中にターゲットデータベースをチェックし、ターゲットデータベースに既存のデータが存在する場合、エラーを報告します。
同期タスクで特定のフィールドまたはデータをフィルタリングできますか?
はい、可能です。オブジェクト名マッピング機能を使用して、同期したくない列をフィルタリングできます。また、SQL WHERE 条件を指定して同期するデータをフィルタリングすることもできます。詳細については、「特定の列の同期または移行」および「SQL 条件を使用したタスクデータのフィルタリング」をご参照ください。
同期タスクを移行タスクに変換できますか?
いいえ、できません。1 つのタイプのタスクを別のタイプに変換することはできません。
スキーマを同期せずにデータのみを同期できますか?
はい、可能です。同期タスクを構成する際に、スキーマ同期 オプションのチェックを外してください。
データ同期インスタンスでソースとターゲットの間にデータ不整合が発生する原因
データ不整合が発生する可能性のある原因は次のとおりです。
タスクを構成する前にターゲットデータベースをクリアしておらず、ターゲットデータベースに既存のデータが存在していました。
タスク構成時に完全同期ではなく、増分同期のみを選択しました。
タスク構成時に増分同期ではなく、完全同期のみを選択し、タスク完了後にソースデータが変更されました。
DTS タスク以外のソースからターゲットデータベースにデータが書き込まれました。
増分書き込みが遅延しており、すべての増分データがターゲットデータベースに書き込まれていません。
同期中にソースデータベースの名前をターゲットで変更できますか?
はい、可能です。ターゲットデータベースでソースデータベースの名前を変更する方法については、「宛先インスタンスでの同期オブジェクトの名前設定」をご参照ください。
DTS は DML または DDL 操作のリアルタイム同期をサポートしていますか?
はい、サポートしています。リレーショナルデータベース間のデータ同期では、INSERT、UPDATE、DELETE などのデータ操作言語 (DML) 操作と、CREATE、DROP、ALTER、RENAME、TRUNCATE などのデータ定義言語 (DDL) 操作をサポートしています。
サポートされる DML または DDL 操作はシナリオによって異なります。「同期シナリオの概要」で、ビジネスシナリオに一致するリンクを選択し、特定のリンク構成ドキュメントでサポートされる DML または DDL 操作を確認してください。
読み取り専用インスタンスを同期タスクのソースとして使用できますか?
同期タスクにはデフォルトで増分データ同期が含まれます。これにより、次の 2 つのシナリオが考えられます。
トランザクションログを記録する読み取り専用インスタンス(RDS for MySQL 5.7 または 8.0 など)は、ソースとして使用できます。
トランザクションログを記録しない読み取り専用インスタンス(RDS for MySQL 5.6 など)は、ソースとして使用できません。
DTS はシャード化されたデータベースおよびテーブルの同期をサポートしていますか?
はい、対応しています。たとえば、MySQL または PolarDB for MySQL データベースからシャード化されたデータベースおよびテーブルを AnalyticDB for MySQL データベースに同期して、複数のテーブルをマージできます。
同期後にターゲットインスタンスのデータ量がソースより小さい理由
同期中にデータをフィルタリングした場合、またはソースインスタンスに大きなテーブル断片化が存在していた場合、移行完了後のターゲットインスタンスのデータ量がソースインスタンスより小さくなる可能性があります。
クロスアカウントデータ同期は双方向同期をサポートしていますか?
現在、双方向のクロスアカウント同期は、RDS MySQL インスタンス間、PolarDB for MySQL クラスター間、Tair (Enterprise Edition) インスタンス間、ApsaraDB for MongoDB (ReplicaSet アーキテクチャ) インスタンス間、および ApsaraDB for MongoDB (シャードクラスター アーキテクチャ) インスタンス間でのみサポートされています。
双方向同期における逆方向同期は DDL 同期をサポートしていますか?
いいえ、サポートしていません。DDL 同期をサポートするのは、ソースからターゲットへのフォワード同期タスクのみです。ターゲットからソースへの逆方向同期タスクは DDL 同期をサポートせず、DDL 操作を自動的にフィルタリングします。
現在の逆方向同期タスクで DDL 操作を同期する必要がある場合は、ビジネスが許容する場合、 双方向同期インスタンスの方向を逆にする ことを試してください。
逆方向同期タスクを手動で構成する必要がありますか?
必要です。フォワード同期タスクの初期同期が完了するまで待ち(ステータス が 実行中 になるまで)、逆方向同期タスクに移動して、タスクの設定 をクリックして構成してください。
逆方向同期タスクは、フォワード同期タスクの遅延がない(0 ミリ秒)状態になってから構成することを推奨します。
DTS はクロスボーダー双方向同期タスクをサポートしていますか?
サポートされていません。
双方向同期タスクで一方のデータベースに追加されたレコードがもう一方のデータベースに表示されない理由
これは、逆方向タスクが構成されていない可能性があります。
増分同期の進捗率が 100% に到達しない理由
増分同期タスクは、ソースデータベースからターゲットデータベースにリアルタイムのデータ変更を継続的に同期し、自動的には終了しません。そのため、完了進捗率は 100% に到達しません。継続的なリアルタイム同期が不要な場合は、DTS コンソールでタスクを手動で終了できます。
増分同期タスクがデータを同期できない理由
DTS インスタンスが増分同期のみに構成されている場合、DTS はタスク開始後に生成されたデータのみを同期します。既存のデータは同期されません。データ整合性を確保するには、タスクを構成する際に 増分同期、スキーマ同期、および 完全同期 を選択することを推奨します。
RDS からの完全データ同期はソース RDS のパフォーマンスに影響しますか?
はい、影響します。ソースデータベースのクエリパフォーマンスに影響を与えます。DTS タスクがソースデータベースに与える影響を軽減するには、次のいずれかの方法を使用できます。
ソースデータベースインスタンスの仕様を向上させます。
DTS タスクを一時的に一時停止し、ソースデータベースの負荷が低下した後に再開します。
DTS タスクのレートを下げます。手順については、「完全移行レートの調整」をご参照ください。
PolarDB-X 1.0 をソースとする同期インスタンスで遅延が表示されない理由
PolarDB-X 1.0 をソースとするインスタンスは分散タスクであり、DTS モニタリングメトリックはサブタスクでのみ存在します。したがって、PolarDB-X 1.0 のソースインスタンスではレイテンシ情報は表示されません。インスタンス ID をクリックし、[タスク管理] セクション内の [サブタスクの詳細] でレイテンシ情報をご確認ください。
マルチテーブルマージタスクでエラー DTS-071001 が発生する理由
マルチテーブルマージタスクの実行中に、オンライン DDL 操作によってソーステーブル構造が変更されたが、ターゲットデータベースで対応する手動変更が行われなかった可能性があります。
旧コンソールでタスクを構成する際にホワイトリスト追加が失敗する場合の対処方法
新しいコンソールを使用してタスクを構成できます。
DTS データ同期中にソースデータベースで DDL 操作が原因でタスクが失敗した場合の対処方法
ソースデータベースで実行されたのと同じ DDL 操作をターゲットデータベースで手動で実行し、その後タスクを再開してください。データ同期中は、pt-online-schema-change などのツールを使用してソースデータベースの同期オブジェクトでオンライン DDL 変更を実行しないでください。これにより、同期が失敗する可能性があります。DTS 以外のデータがターゲットデータベースに書き込まれていない場合、Data Management (DMS) を使用してオンライン DDL 変更を実行するか、影響を受けたテーブルを同期オブジェクトから削除できます。テーブルの削除方法については、「同期オブジェクトの削除」をご参照ください。
DTS データ同期中にターゲットデータベースで DDL 操作が原因でタスクが失敗した場合の対処方法
DTS 増分同期中にターゲットデータベースからデータベースまたはテーブルが削除され、タスク例外が発生した場合は、次のいずれかの解決策を使用できます。
方法 1:タスクを再構成し、失敗の原因となったデータベースまたはテーブルを同期オブジェクトから除外します。
方法 2:同期オブジェクトを変更して、問題のあるデータベースまたはテーブルを削除します。手順については、「同期オブジェクトの削除」をご参照ください。
リリース済みの同期タスクを復元できますか?タスクを再構成した場合、データ整合性を保証できますか?
リリース済みの同期タスクは復元できません。完全同期 を選択せずにタスクを再構成した場合、タスクリリースから新しいタスク起動までの間に生成されたデータはターゲットデータベースに同期されず、データ整合性が損なわれます。ビジネスで正確なデータが必要な場合は、ターゲットデータベースのデータを削除してから同期タスクを再構成してください。タスクステップ で、スキーマ同期 および 完全同期(増分同期 はデフォルトで選択されています)を選択します。
DTS 完全同期タスクの進捗が長時間表示されない場合の対処方法
同期したいテーブルにプライマリキーがない場合、完全同期は非常に遅くなります。同期を開始する前に、ソーステーブルにプライマリキーを追加することを推奨します。
同じ名前のテーブルを同期する場合、DTS はターゲットテーブルに存在しない場合にのみソーステーブルデータを転送できますか?
はい、可能です。タスク構成中に、ターゲットの既存テーブルの処理モード を エラーを無視して続行 に設定します。テーブル構造が一致する場合、完全同期中に、ターゲットに同じプライマリキー値を持つレコードがすでに存在する場合、ソースレコードは同期されません。
クロスアカウント同期タスクの構成方法
まず、クロスアカウントタスクのシナリオを特定する必要があります。次に、データベースインスタンスを所有する Alibaba Cloud アカウントを使用して、クロスアカウントタスクの RAM 権限付与を設定します。最後に、クロスアカウントタスクを設定できます。
DMS LogicDB インスタンスを選択できない場合の対処方法
インスタンスの正しいリージョンを選択していることを確認してください。それでもインスタンスを選択できない場合は、利用可能なインスタンスが 1 つしかない可能性があります。他のパラメーターの構成を続行できます。
SQL Server をソースとする同期タスクは関数の同期をサポートしていますか?
いいえ、サポートしていません。テーブル粒度で同期オブジェクトを選択する場合、ビュー、トリガー、ストアドプロシージャなどの他のオブジェクトはターゲットデータベースに同期されません。
同期タスクエラーの対処方法
エラーメッセージに基づいて、「一般的なエラー」を確認して解決策を見つけてください。
同期タスクでホットスポットマージを有効にする方法
trans.hot.merge.enable パラメーターを true に設定します。詳細については、「パラメーター値の変更」をご参照ください。
ソースデータベースにトリガーが存在する場合の同期方法
データベース全体を同期し、そのデータベース内のトリガー (TRIGGER) が同じデータベース内のテーブルを更新する場合、ソースデータベースとターゲットデータベースの間にデータ不整合が発生する可能性があります。同期手順の詳細については、「ソースデータベースにトリガーが存在する場合の同期または移行ジョブの構成方法」をご参照ください。
DTS は sys データベースおよびシステムデータベースの同期をサポートしていますか?
いいえ、そうではありません。
DTS は MongoDB の admin および local データベースの同期をサポートしていますか?
いいえ、サポートしていません。DTS は、MongoDB の admin および local データベースをソースまたはターゲットとして使用することをサポートしていません。
双方向同期タスクの逆方向タスクを構成できるタイミング
フォワード増分タスクの遅延がゼロになった後のみ、双方向同期タスクの逆方向タスクを構成できます。
PolarDB-X 1.0 をソースとする同期タスクはノードのスケーリングをサポートしていますか?
いいえ、サポートしていません。PolarDB-X 1.0 ソースでノードスケーリングが発生した場合は、タスクを再構成する必要があります。
DTS は Kafka に同期されたデータの一意性を保証できますか?
いいえ、保証できません。Kafka に書き込まれるデータは追加されるため、DTS タスクが再起動またはソースログを再取得した場合、重複データが発生する可能性があります。DTS はデータのべき等性を保証します。つまり、データは順序通りに並び、重複データの最新値が最後に表示されます。
DTS は、RDS MySQL から AnalyticDB for MySQL への同期をサポートしていますか?
はい、サポートしています。構成手順については、「RDS MySQL から AnalyticDB for MySQL 3.0 への同期」をご参照ください。
Redis-to-Redis 同期で完全同期が表示されない理由
Redis-to-Redis 同期は完全データ同期と増分データ同期の両方をサポートしており、増分同期 として表示されます。
完全同期をスキップできますか?
はい、可能です。完全同期をスキップすると増分同期を続行できますが、エラーが発生する可能性があります。完全同期をスキップしないことを推奨します。
DTS はスケジュールされた自動同期をサポートしていますか?
DTS はデータ同期タスクのスケジュールされた起動をサポートしていません。
同期はテーブル断片化スペースをデータとともに転送しますか?
いいえ、そうではありません。
MySQL 8.0 から MySQL 5.6 への同期時に注意すべき点
同期を開始する前に、MySQL 5.6 にデータベースを作成する必要があります。ソースとターゲットのバージョンを一致させるか、低いバージョンから高いバージョンへデータを同期することを推奨します。これにより互換性が確保されます。高いバージョンから低いバージョンへのデータ同期は、互換性の問題を引き起こす可能性があります。
ソースデータベースのアカウントをターゲットデータベースに同期できますか?
現在、RDS for MySQL インスタンス間の同期タスクのみがアカウント同期をサポートしています。他の同期タスクはこの機能をサポートしていません。
クロスアカウント双方向同期タスクを構成できますか?
現在、双方向のクロスアカウント同期は、RDS MySQL インスタンス間、PolarDB for MySQL クラスター間、Tair (Enterprise Edition) インスタンス間、ApsaraDB for MongoDB (ReplicaSet アーキテクチャ) インスタンス間、および ApsaraDB for MongoDB (シャードクラスター アーキテクチャ) インスタンス間でのみサポートされています。
Alibaba Cloud アカウント間でデータを複製 設定オプションがないタスクについては、CEN を使用してクロスアカウント双方向同期を実装できます。詳細については、「Alibaba Cloud アカウントまたはリージョン間でのデータベースリソースへのアクセス」をご参照ください。
Message Queue for Apache Kafka をターゲットとする場合のパラメーター構成方法
必要に応じてパラメーターを構成できます。特殊なパラメーター構成方法の詳細については、「Message Queue for Apache Kafka インスタンスのパラメーター構成」をご参照ください。
DTS を使用して Redis データ同期または移行タスクを実行する際に、エラー ERR invalid DB indexが発生した場合の対処方法
原因:ERR invalid DB index エラーは、ターゲットデータベースが SELECT DB 操作を実行する際に発生します。このエラーは通常、ターゲットデータベースの databases 数が不足しているために発生します。ターゲットデータベースがプロキシを使用している場合、プロキシが databases 数の制限を解除できるかどうかを確認してください。
解決策:ターゲットデータベースの databases 構成を変更します。ソースデータベースと一致するように拡張し、その後 DTS タスクを再起動することを推奨します。次のコマンドを使用して、ターゲットデータベースの databases 構成を照会できます。
CONFIG GET databases;SQL Server データを AnalyticDB for PostgreSQL に同期または移行する際に、エラー IDENTIFIER CLUSTEREDが発生した場合の対処方法
原因:SQL Server データを AnalyticDB for PostgreSQL に同期または移行する際、CREATE CLUSTERED INDEX コマンドがサポートされていないため、タスクが失敗します。
解決策: 遅延期間中に他の DDL 文が存在しないことを確認した後、インスタンス パラメーターを変更する sink.ignore.failed.ddl を true に設定して、すべての DDL 文の実行をスキップします。増分同期またはマイグレーション オフセットが進んだ後、sink.ignore.failed.ddl パラメーターを false にリセットします。
Redis 同期または移行タスク中にターゲットデータベースのキーの有効期限を延長する場合、実際の効果がありますか?
はい、あります。完全データ同期中にキーが期限切れにならないようにするには、ターゲットデータベースのキーの有効期限を延長できます。増分同期または移行を含む DTS タスクの場合、ソースデータベースでキーが期限切れになり削除されると、ターゲットデータベースの対応するキーも解放されます。
ターゲットデータベースのキーの有効期限を延長した後、ソースデータベースのキーが期限切れになると、ターゲットのキーはすぐに解放されますか?
いいえ、ターゲットデータベースのキーが必ずしもすぐに解放されるわけではありません。ソースデータベースのキーが期限切れになりクリアされた後、ターゲットデータベースの対応するキーが解放されます。
たとえば、ソースデータベースのキーの有効期限が 5 秒で、ターゲットキーの有効期限が 30 秒に延長されている場合、ソースキーが 5 秒後に自動的にクリアされると、ターゲットキーはすぐに解放されます。ソースキーが期限切れになり自動的にクリアされると、システムは AOF ファイルに削除操作を追加します。この操作は同期され、ターゲットデータベースで実行されます。
SelectDB に同期する際に DTS を使用して、エラー column_name[xxx], the length of input string is too long than vec schema が発生した場合の対処方法
詳細なエラー:
Reason: column_name[xxx], the length of input string is too long than vec schema. first 32 bytes of input str: [01a954b4-xxx-xxx-xxx-95b675b9] schema length: 2147483643; limit length: 1048576; actual length: 7241898; . src line [];原因:ソースの xxx フィールドの増分サイズが、ターゲットの xxx フィールドタイプの長さ制限を超えています。
解決策:フィールドが
STRINGタイプの場合、SelectDB コンソールで string_type_length_soft_limit_bytes パラメーターの値をactual length(7241898) より大きい値に増やすことができます。
SelectDB に同期する際に DTS を使用して、エラー column(xxx) values is null while columns is not nullable. が発生した場合の対処方法
詳細なエラー:
Reason: column(xxx) values is null while columns is not nullable. src line [ xxx ];原因:ターゲットの xxx フィールドは
NOT NULLですが、NULL値が書き込まれています。説明一般的なシナリオ:ソースに
0000-0000-0000のような不正な日付形式のデータが書き込まれ、DTS が自動的にそれをNULLに変換してエラーをトリガーします。解決策:
ターゲットフィールドタイプを変更して NULL 値を許可します。
同期オブジェクトを変更します:問題のあるテーブルを削除し、ソースデータを修正してから、ターゲットデータベースのテーブルを削除します。その後、テーブルを同期オブジェクトに再度追加し、完全および増分同期を再実行します。
データ移行に関する問題
データ移行タスクを実行した後、ソースデータベースのデータは残りますか?
DTS は、ソースデータベースからターゲットデータベースにデータを移行および同期しますが、ソースデータには影響を与えません。
DTS が移行をサポートするデータベースインスタンス
DTS は、リレーショナルデータベース管理システム (RDBMS)、NoSQL データベース、オンライン分析処理 (OLAP) データベースなど、さまざまなデータソース間のデータ移行をサポートしています。サポートされている移行インスタンスの詳細については、「移行シナリオの概要」をご参照ください。
データ移行の仕組み
データ移行の仕組みの詳細については、「サービスアーキテクチャと機能原理」をご参照ください。
実行中の移行タスクで移行オブジェクトを変更できますか?
いいえ、できません。
既存の移行タスクに新しいテーブルを追加できますか?
いいえ、できません。
実行中の移行タスクでテーブルおよびフィールドを変更する方法
データ移行タスクは、移行オブジェクトの変更をサポートしていません。
移行タスクを一時停止して後で再開した場合、データ不整合が発生しますか?
タスクの一時停止中にソースデータベースのデータが変更された場合、ソースデータベースとターゲットデータベースの間にデータ不整合が発生する可能性があります。タスクを再開して増分データが移行されると、ターゲットデータベースのデータはソースデータベースのデータと一致します。
移行タスクを同期タスクに変換できますか?
いいえ、できません。1 つのタイプのタスクを別のタイプに変換することはできません。
スキーマを移行せずにデータのみを移行できますか?
はい、可能です。移行タスクを構成する際に、スキーマ移行 オプションのチェックを外してください。
データ移行インスタンスでソースとターゲットの間にデータ不整合が発生する原因
データ不整合が発生する可能性のある原因は次のとおりです。
タスクを構成する前にターゲットデータベースをクリアしておらず、ターゲットデータベースに既存のデータが存在していました。
タスク構成時に完全移行ではなく、増分移行のみを選択しました。
タスク構成時に増分移行ではなく、完全移行のみを選択し、タスク完了後にソースデータが変更されました。
DTS タスク以外のソースからターゲットデータベースにデータが書き込まれました。
増分書き込みが遅延しており、すべての増分データがターゲットデータベースに書き込まれていません。
移行中にソースデータベースの名前をターゲットで変更できますか?
はい、可能です。ターゲットデータベースでソースデータベースの名前を変更する方法については、「データベース、テーブル、および列のマッピング」をご参照ください。
DTS は同一インスタンス内でのデータ移行をサポートしていますか?
はい、サポートしています。同一インスタンスでのデータ移行手順については、「異なるデータベース名間でのデータ同期または移行」をご参照ください。
DTS は DML または DDL 操作のリアルタイム移行をサポートしていますか?
はい、サポートしています。リレーショナルデータベース間のデータ移行では、INSERT、UPDATE、DELETE などの DML 操作と、CREATE、DROP、ALTER、RENAME、TRUNCATE などの DDL 操作をサポートしています。
サポートされる DML または DDL 操作はシナリオによって異なります。「移行シナリオの概要」で、ビジネスシナリオに一致するリンクを選択し、特定のリンク構成ドキュメントでサポートされる DML または DDL 操作を確認してください。
読み取り専用インスタンスを移行タスクのソースとして使用できますか?
増分データ移行を必要としない移行タスクの場合、読み取り専用インスタンスをソースとして使用できます。増分データ移行が必要な場合、次の 2 つのシナリオが考えられます。
トランザクションログを記録する読み取り専用インスタンス(RDS for MySQL 5.7 または 8.0 など)は、ソースとして使用できます。
トランザクションログを記録しない読み取り専用インスタンス(RDS for MySQL 5.6 など)は、ソースとして使用できません。
DTS はシャード化されたデータベースおよびテーブルの移行をサポートしていますか?
はい、対応しています。たとえば、MySQL または PolarDB for MySQL データベースから、AnalyticDB for MySQL データベースにシャード化されたデータベースおよびテーブルを移行して、複数のテーブルをマージできます。
移行タスクで特定のフィールドまたはデータをフィルタリングできますか?
はい、可能です。オブジェクト名マッピング機能を使用して、移行したくない列をフィルタリングできます。また、SQL WHERE 条件を指定して移行するデータをフィルタリングすることもできます。詳細については、「特定の列の同期または移行」および「移行するデータのフィルタリング」をご参照ください。
移行後にターゲットインスタンスのデータ量がソースより小さい理由
移行中にデータをフィルタリングした場合、またはソースインスタンスに大きなテーブル断片化が存在していた場合、移行完了後のターゲットインスタンスのデータ量がソースインスタンスより小さくなる可能性があります。
移行タスク完了後に完了値が合計値を超える理由
表示される合計値は推定値です。移行タスクが完了すると、合計値は正確な値に調整されます。
データ移行中にターゲットデータベースに作成される increment_trx テーブルの目的
データ移行中に、DTS はターゲットインスタンスに `increment_trx` テーブルを作成します。このテーブルは、増分移行のチェックポイントテーブルとして機能し、タスクが失敗した場合にブレークポイントから再開できるように、増分移行チェックポイントを記録します。移行中にこのテーブルを削除しないでください。削除すると、移行タスクが失敗します。
DTS は完全移行フェーズ中にブレークポイントから再開をサポートしていますか?
はい、サポートしています。完全移行フェーズ中にタスクを一時停止して再開すると、最初からではなく、中断したところから再開します。
非 Alibaba Cloud インスタンスを Alibaba Cloud に移行する方法
非 Alibaba Cloud インスタンスを Alibaba Cloud に移行する手順については、「サードパーティクラウドから Alibaba Cloud への移行」をご参照ください。
オンプレミス Oracle データベースを PolarDB に移行する方法
オンプレミス Oracle データベースを PolarDB に移行する手順については、「自己管理 Oracle から PolarDB for PostgreSQL (Oracle 互換) への移行」をご参照ください。
完全移行が完了する前にデータ移行タスクを一時停止できますか?
はい、可能です。
RDS MySQL から自己管理 MySQL に部分的なデータを移行する方法
タスク構成中に、ソースオブジェクト で移行するオブジェクトを選択するか、[選択済みオブジェクト] で必要に応じてフィルタリングできます。MySQL-to-MySQL 移行のプロセスは同様です。詳細については、「自己管理 MySQL から RDS MySQL への移行」をご参照ください。
同一 Alibaba Cloud アカウント配下の RDS インスタンス間で移行する方法
DTS は RDS インスタンス間の移行および同期をサポートしています。構成方法の詳細については、「移行シナリオの概要」の関連構成ドキュメントをご参照ください。
移行タスクを開始した後、ソースデータベースに IOPS アラートが表示される場合のソースデータベースの安定性確保方法
DTS タスク実行中にソースデータベースインスタンスの負荷が高い場合、DTS タスクがソースデータベースに与える影響を軽減するために、次のいずれかの方法を使用できます。
ソースデータベースインスタンスの仕様を向上させます。
DTS タスクを一時的に一時停止し、ソースデータベースの負荷が低下した後に再開します。
DTS タスクのレートを低減します。手順については、「完全移行レートの調整」をご参照ください。
データ移行のために test という名前のデータベースを選択できない理由
DTS データ移行は、システムデータベースの移行をサポートしていません。移行にはユーザー作成のデータベースを選択する必要があります。
PolarDB-X 1.0 をソースとする移行インスタンスで遅延が表示されない理由
PolarDB-X 1.0 をソースとするインスタンスは分散タスクであり、DTS モニタリングメトリックはサブタスクにのみ存在するため、PolarDB-X 1.0 ソースインスタンスでは遅延情報は表示されません。 インスタンス ID をクリックし、[サブタスク詳細] の [タスク管理] セクションで遅延情報を確認します。
DTS が MongoDB データベースを移行できない理由
移行対象のデータベースが local または admin データベースである可能性があります。DTS は、MongoDB の admin および local データベースをソースまたはターゲットとして使用することをサポートしていません。
マルチテーブルマージタスクでエラー DTS-071001 が発生する理由
マルチテーブルマージタスクの実行中に、オンライン DDL 操作によってソーステーブル構造が変更されたが、ターゲットデータベースで対応する手動変更が行われなかった可能性があります。
旧コンソールでタスクを構成する際にホワイトリスト追加が失敗する場合の対処方法
新しいコンソールを使用してタスクを構成できます。
DTS データ移行中にソースデータベースで DDL 操作が原因でタスクが失敗した場合の対処方法
ソースデータベースで実行されたのと同じ DDL 操作をターゲットデータベースで手動で実行し、その後タスクを再開してください。データ移行中は、pt-online-schema-change などのツールを使用してソースデータベースの移行オブジェクトでオンライン DDL 変更を実行しないでください。これにより、移行が失敗する可能性があります。DTS 以外のデータがターゲットデータベースに書き込まれていない場合、Data Management (DMS) を使用してオンライン DDL 変更を実行できます。
DTS データ移行中にターゲットデータベースで DDL 操作が原因でタスクが失敗した場合の対処方法
DTS 増分移行中にターゲットデータベースからデータベースまたはテーブルが削除され、タスク例外が発生した場合は、タスクを再構成し、失敗の原因となったデータベースまたはテーブルを移行オブジェクトから除外する必要があります。
リリース済みの移行タスクを復元できますか?タスクを再構成した場合、データ整合性を保証できますか?
リリース済みの移行タスクは復元できません。完全移行 を選択せずにタスクを再構成した場合、タスクリリースから新しいタスク開始までの間に生成されたデータはターゲットデータベースに移行されず、データ整合性が損なわれます。ビジネスで高いデータ精度が必要な場合は、ターゲットデータベースのデータを削除してから移行タスクを再構成してください。タスクステップ セクションで、スキーマ移行、増分移行、および 完全移行 を選択します。
DTS 完全移行タスクの進捗が長時間表示されない場合の対処方法
移行したいテーブルにプライマリキーがない場合、完全移行は非常に遅くなります。移行を開始する前に、ソーステーブルにプライマリキーを追加することを推奨します。
同じ名前のテーブルを移行する場合、DTS はターゲットテーブルに存在しない場合にのみソーステーブルデータを転送できますか?
はい、可能です。タスク構成中に、ターゲットの既存テーブルの処理モード を エラーを無視して続行 に設定します。テーブル構造が一致する場合、完全移行中に、ターゲットに同じプライマリキー値を持つレコードがすでに存在する場合、ソースレコードは移行されません。
クロスアカウント移行タスクの構成方法
まず、クロスアカウントタスクのシナリオを理解する必要があります。次に、データベースインスタンスを所有する Alibaba Cloud アカウントを使用して、クロスアカウントタスクの RAM 権限付与を設定します。最後に、クロスアカウントタスクを設定できます。
データ移行タスクのためにオンプレミスデータベースに接続する方法
接続タイプ を パブリック IP に設定して、移行タスクを構成します。詳細については、「自己管理 MySQL から RDS MySQL への移行」をご参照ください。
エラー DTS-31008 でデータ移行が失敗した場合の対処方法
理由を表示 をクリックするか、「一般的なエラー」を確認して、エラーメッセージの解決策を見つけてください。
専用回線を使用して自己管理データベースに接続する際のネットワーク接続問題の対処方法
専用回線が DTS 関連の IP ホワイトリストを正しく構成しているかどうかを確認してください。必要な IP アドレス範囲の詳細については、「 自己管理データベースの IP ホワイトリストに DTS サーバーの IP アドレス範囲を追加」をご参照ください。
SQL Server をソースとする移行タスクは関数の移行をサポートしていますか?
いいえ、サポートしていません。テーブル粒度で移行オブジェクトを選択する場合、ビュー、トリガー、ストアドプロシージャなどの他のオブジェクトはターゲットデータベースに移行されません。
DTS 完全移行速度が遅い場合の対処方法
データ量が大きいため、移行には時間がかかる場合があります。完全移行 の タスク管理 セクションにあるタスク詳細ページで、移行進捗を確認できます。
スキーマ移行エラーの対処方法
インスタンス ID をクリックしてタスク詳細ページに移動し、タスク管理 セクションでスキーマ移行の具体的なエラーメッセージを確認してから、エラーを解決してください。一般的なエラーの解決策については、「一般的なエラー」をご参照ください。
スキーマ移行および完全移行は課金対象ですか?
いいえ、課金されません。課金の詳細については、「課金項目」をご参照ください。
Redis-to-Redis データ移行中に、ターゲットの zset データは上書きされますか?
ターゲットの zset は上書きされます。ターゲットデータベースにソースデータベースと同じキーがすでに存在する場合、DTS はまずターゲットデータベースの対応する zset を削除し、その後ソース zset コレクションの各オブジェクトをターゲットデータベースに追加します。
完全移行がソースデータベースに与える影響
DTS 完全移行プロセスでは、まずデータをスライスし、その後各スライス範囲内でデータを読み取りおよび書き込みます。ソースデータベースにとって、スライスは IOPS を増加させます。スライス範囲内のデータ読み取りは、IOPS、CachePool、アウトバウンド帯域幅に影響を与えます。DTS の実践経験に基づくと、これらの影響は無視できる程度です。
PolarDB-X 1.0 をソースとする移行タスクはノードのスケーリングをサポートしていますか?
いいえ、サポートしていません。PolarDB-X 1.0 ソースでノードスケーリングが発生した場合は、タスクを再構成する必要があります。
DTS は Kafka に移行されたデータの一意性を保証できますか?
いいえ、保証できません。Kafka に書き込まれるデータは追加されるため、DTS タスクが再起動またはソースログを再取得した場合、重複データが発生する可能性があります。DTS はデータのべき等性を保証します。つまり、データは順序通りに並び、重複データの最新値が最後に表示されます。
まず完全移行タスクを構成し、その後増分データ移行タスクを構成した場合、データ不整合が発生しますか?
はい、データ不整合が発生する可能性があります。増分データ移行タスクを別途構成した場合、データ移行は増分移行タスクが開始された後からのみ開始されます。増分移行タスク開始前にソースインスタンスで生成されたデータは、ターゲットインスタンスに同期されません。ダウンタイムゼロの移行を行うには、タスクを構成する際にスキーマ移行、完全データ移行、および増分データ移行を選択することを推奨します。
増分移行タスクを構成する際に、スキーマ移行を選択する必要がありますか?
スキーマ移行は、データ移行開始前に Table A の定義などのオブジェクト定義をターゲットインスタンスに転送します。増分移行のデータ整合性を確保するには、スキーマ移行、完全データ移行、および増分データ移行を選択することを推奨します。
自己管理データベースから RDS への移行中に、RDS のストレージスペースがソースデータベースより多く使用される理由
DTS は論理移行を実行します。つまり、移行対象のデータを SQL 文としてパッケージ化し、その後ターゲット RDS インスタンスに移行します。このプロセスにより、ターゲット RDS インスタンスでバイナリログ (binlog) データが生成されます。そのため、移行中に RDS インスタンスのストレージスペース使用量がソースデータベースより多くなる場合があります。
DTS は VPC ネットワーク内の MongoDB の移行をサポートしていますか?
はい、サポートしています。DTS は、VPC ベースの ApsaraDB for MongoDB インスタンスを移行のソースデータベースとして使用することをサポートしています。
データ移行中にソースデータベースが変更された場合、移行されたデータはどうなりますか?
タスクがスキーマ移行、完全移行、および増分移行に構成されている場合、移行中にソースデータベースで発生したすべてのデータ変更は、DTS によってターゲットデータベースに移行されます。
完了した移行タスクをリリースしても、移行されたデータベースの使用に影響しますか?
いいえ、影響しません。移行タスクが完了した後(実行ステータス が 完了 を示す)、移行タスクを安全にリリースできます。
DTS は MongoDB 増分移行をサポートしていますか?
はい、サポートしています。構成例については、「移行シナリオの概要」をご参照ください。
移行タスクのソースインスタンスとして使用する RDS インスタンスと、パブリック IP を持つ自己管理データベースの違い
RDS インスタンスを使用して移行タスクを構成する場合、DTS は DNS 変更やネットワークタイプの切り替えなどの RDS インスタンスの変更に自動的に適応し、リンクの信頼性を確保します。
DTS は VPC 内の ECS 上の自己管理データベースから RDS インスタンスへの移行をサポートしていますか?
サポートされています。
ソース ECS インスタンスとターゲット RDS インスタンスが同じリージョンにある場合、DTS は VPC 内の ECS インスタンス上の自己管理データベースに直接アクセスできます。
ソース ECS インスタンスとターゲット RDS インスタンスが異なるリージョンにある場合、ECS インスタンスに EIP を必要とします。移行タスクを構成する際に、ECS インスタンスをソースとして選択すると、DTS は自動的に ECS インスタンスの EIP を使用してデータベースにアクセスします。
DTS は移行中にテーブルをロックしますか?ソースデータベースに影響しますか?
いいえ、DTS は完全データ移行および増分データ移行のどちらのフェーズでも、ソースデータベースのテーブルをロックしません。移行中、ソースデータベースのテーブルは読み取りおよび書き込みが可能です。
RDS 移行を実行する際、DTS は RDS プライマリまたはセカンダリデータベースからデータを取得しますか?
DTS はデータ移行中に RDS プライマリデータベースからデータを取得します。
DTS はスケジュールされた自動移行をサポートしていますか?
DTS はデータ移行タスクのスケジュールされた起動をサポートしていません。
DTS は VPC モードの RDS インスタンスのデータ移行をサポートしていますか?
はい、サポートしています。移行タスクを構成するには、RDS インスタンス ID を提供するだけで済みます。
同一アカウントまたはクロスアカウントの移行/同期の場合、ECS/RDS インスタンスに対して内部ネットワークまたはパブリックネットワークを使用しますか?トラフィック料金は発生しますか?
同期または移行タスクで使用されるネットワーク(内部またはパブリック)は、アカウントがクロスアカウントかどうかとは関係ありません。トラフィック料金はタスクタイプに依存します。
使用されるネットワーク
移行タスク:同一リージョンの移行の場合、DTS は内部ネットワークを使用して ECS および RDS インスタンスに接続します。クロスリージョンの移行の場合、DTS はパブリックネットワークを使用してソースインスタンス(ECS または RDS)に接続し、内部ネットワークを使用してターゲット RDS インスタンスに接続します。
同期タスクはプライベートネットワークを使用します。
トラフィック料金
移行タスクの場合、ターゲットデータベースインスタンスの アクセス方法 が パブリック IP アドレス に設定されている場合、パブリックネットワークのアウトバウンドトラフィック料金が発生します。他の DTS インスタンスタイプではトラフィック料金は発生しません。
同期タスク:トラフィック料金は発生しません。
DTS を使用してデータ移行を行う際、移行後にソースデータベースのデータは削除されますか?
いいえ、影響しません。DTS は、ソースデータベースからターゲットデータベースへデータをコピーしますが、ソースデータベースのデータには影響を与えません。
RDS インスタンス間でデータ移行を実行する際、ターゲットデータベース名を指定できますか?
はい、可能です。RDS インスタンス間でデータ移行を実行する際、DTS のデータベース名マッピング機能を使用してターゲットデータベース名を指定できます。詳細については、「異なるデータベース名間でのデータ同期または移行」をご参照ください。
DTS 移行タスクのソースが ECS インスタンスに接続できない場合の対処方法
ECS インスタンスでパブリック IP アドレスが有効になっていない可能性があります。ECS インスタンスに EIP をバインドして再試行できます。EIP のバインド方法の詳細については、「Elastic IP Address」をご参照ください。
Redis-to-Redis 移行で完全移行が表示されない理由
Redis-to-Redis 移行は完全データ移行と増分データ移行の両方をサポートしており、増分移行 として一緒に表示されます。
完全移行をスキップできますか?
はい、可能です。完全移行をスキップすると増分移行を続行できますが、エラーが発生する可能性があります。完全移行をスキップしないことを推奨します。
Redis Cluster Edition は DTS へのパブリック IP 接続をサポートしていますか?
いいえ、サポートしていません。現在、Redis Basic Edition のみが DTS 移行インスタンスへのパブリック IP 接続をサポートしています。
MySQL 8.0 から MySQL 5.6 への移行時に注意すべき点
移行を開始する前に、MySQL 5.6 にデータベースを作成する必要があります。ソースとターゲットのバージョンを一致させるか、低いバージョンから高いバージョンへデータを移行することを推奨します。これにより互換性が確保されます。高いバージョンから低いバージョンへのデータ移行は、互換性の問題を引き起こす可能性があります。
ソースデータベースのアカウントをターゲットデータベースに移行できますか?
現在、RDS for MySQL インスタンス間の移行タスクのみがアカウント移行をサポートしています。他の移行タスクはこの機能をサポートしていません。
Message Queue for Apache Kafka をターゲットとする場合のパラメーター構成方法
必要に応じてパラメーターを構成できます。特殊なパラメーター構成方法の詳細については、「Message Queue for Apache Kafka インスタンスのパラメーター構成」をご参照ください。
完全移行をスケジュールする方法
データ統合のスケジューリング戦略を使用して、ソースデータベースのスキーマおよび既存データを定期的にターゲットデータベースに移行できます。詳細については、「RDS MySQL インスタンス間のデータ統合タスクの構成」をご参照ください。
DTS は ECS 自己管理 SQL Server からオンプレミス自己管理 SQL Server への移行をサポートしていますか?
はい、サポートしています。オンプレミス自己管理 SQL Server は Alibaba Cloud に接続されている必要があります。詳細については、「準備の概要」をご参照ください。
DTS は他のクラウドの PostgreSQL データベースの移行をサポートしていますか?
他のクラウドの PostgreSQL データベースが DTS パブリックネットワークアクセスを許可している場合、DTS はデータ移行をサポートします。
PostgreSQL バージョンが 10.0 より古い場合、増分移行はサポートされません。
変更追跡に関する問題
変更追跡の仕組み
詳細については、「サービスアーキテクチャと機能」をご参照ください。
変更追跡タスクの有効期限が切れた後、コンシューマーグループは削除されますか?
DTS 変更追跡タスクの有効期限が切れると、関連するデータコンシューマーグループは 7 日間保持されます。有効期限切れ後 7 日以内にインスタンスを更新しない場合、インスタンスはリリースされ、対応するコンシューマーグループは削除されます。
読み取り専用インスタンスをサブスクリプションタスクのソースとして使用できますか?
次の 2 つのシナリオが考えられます。
トランザクションログを記録する読み取り専用インスタンス(RDS for MySQL 5.7 または 8.0 など)は、ソースとして使用できます。
トランザクションログを記録しない読み取り専用インスタンス(RDS for MySQL 5.6 など)は、ソースとして使用できません。
サブスクライブされたデータの使用方法
詳細については、「サブスクライブされたデータの使用」をご参照ください。
変更追跡を使用してデータを転送した後、日付データ形式が変更される理由
DTS は日付データをデフォルト形式 YYYY:MM:DD で保存します。YYYY-MM-DD は表示形式ですが、実際の保存形式は YYYY:MM:DD です。したがって、入力形式に関係なく、データはデフォルト形式に変換されます。
サブスクリプションタスクの問題のトラブルシューティング方法
サブスクリプションタスクのトラブルシューティング方法の詳細については、「サブスクリプションタスクのトラブルシューティング」をご参照ください。
SDK の通常のデータダウンロードが突然一時停止し、データをサブスクライブできなくなった場合の対処方法
SDK コードが消費チェックポイントを報告するために `ackAsConsumed` インターフェイスを呼び出しているかどうかを確認してください。`ackAsConsumed` インターフェイスを呼び出してチェックポイントを報告しない場合、SDK のレコードキャッシュスペースはクリアされません。キャッシュがいっぱいになると、新しいデータをプルできなくなります。これにより、SDK が一時停止し、データのサブスクライブが停止します。
SDK を再起動した後、データを正常にサブスクライブできない場合の対処方法
SDK を起動する前に、消費チェックポイントを変更して、それがデータ範囲内にあることを確認する必要があります。変更方法の詳細については、「消費チェックポイントの保存と照会」をご参照ください。
クライアントがデータ使用の時点を指定する方法
サブスクライブされたデータを使用する際、initCheckpoint パラメーターを使用して時点を指定できます。詳細については、「SDK サンプルコードを使用したサブスクライブデータの使用」をご参照ください。
DTS サブスクリプションタスクにデータが蓄積されています。チェックポイントをリセットする方法
SDK クライアントの使用モードに基づいて、対応するコードファイルを開きます。例:DTSConsumerAssignDemo.java または DTSConsumerSubscribeDemo.java。
説明詳細については、「SDK サンプルコードを使用したサブスクライブデータの使用」をご参照ください。
サブスクリプションタスクリストで、ターゲットサブスクリプションインスタンスの データ範囲 列の変更可能なチェックポイント範囲を確認します。
必要に応じて新しい消費チェックポイントを選択し、Unix タイムスタンプに変換します。
コードファイル内の古い消費チェックポイント (initCheckpoint パラメーター) を新しいものに置き換えます。
クライアントを再起動します。
サブスクリプションタスクの VPC アドレスを使用してクライアントが接続できない場合の対処方法
クライアントマシンがサブスクリプションタスク構成時に指定された VPC 内にない可能性があります(例:VPC の置き換えによる)。タスクを再構成する必要があります。
コンソールの消費チェックポイントが最大データ範囲値より大きい理由
サブスクリプションチャネルのデータ範囲は 1 分ごとに更新されますが、消費チェックポイントは 10 秒ごとに更新されます。リアルタイムで消費している場合、消費チェックポイント値がサブスクリプションチャネルデータ範囲の最大値を超えることがあります。
DTS は SDK が完全なトランザクションを受信することをどのように保証しますか?
提供された消費チェックポイントに基づいて、サーバーはこのチェックポイントに対応する完全なトランザクションを検索し、トランザクションの BEGIN 文からデータの配信を開始します。これにより、トランザクションの完全な内容が受信されることを保証します。
データが正常に使用されていることを確認する方法
データが正常に使用されている場合、Data Transmission Service コンソールの消費チェックポイントが予想通りに進みます。
変更追跡 SDK で usePublicIp=true とは何を意味しますか?
変更追跡 SDK 構成で usePublicIp=true を設定すると、SDK がパブリックネットワーク経由で DTS サブスクリプションチャネルにアクセスすることを意味します。
RDS プライマリ-セカンダリ切り替えまたはプライマリ再起動が変更追跡タスク中にビジネスに影響しますか?
RDS for MySQL、RDS for PostgreSQL、PolarDB for MySQL、PolarDB for PostgreSQL、および PolarDB-X 1.0 (RDS for MySQL ストレージタイプ) インスタンスの場合、DTS はプライマリ-セカンダリ切り替えまたは再起動に自動的に適応し、ビジネスに影響を与えません。
RDS は自動的に Binlog をローカルサーバーにダウンロードできますか?
DTS 変更追跡は RDS binlog のリアルタイムサブスクリプションをサポートしています。DTS 変更追跡サービスを有効にして、DTS SDK を使用して RDS binlog データをサブスクライブし、ローカルサーバーにリアルタイムで同期できます。
変更追跡のリアルタイム増分データは新規データのみを指しますか、変更されたデータも含まれますか?
DTS 変更追跡は、すべての挿入、削除、更新、スキーマ変更 (DDL) を含む増分データをサブスクライブできます。
変更追跡タスクで 1 つのレコードが ACK されなかった場合、SDK 再起動後に重複データを受信する理由
SDK に ACK されていないメッセージがある場合、サーバーはバッファ内のすべてのメッセージをプッシュします。このプロセスが完了すると、SDK は新しいメッセージを受信できなくなります。サーバーは、ACK されていないメッセージの直前の最後のメッセージのチェックポイントとして消費チェックポイントを保存します。SDK を再起動すると、サーバーはメッセージ損失を防ぐために、ACK されていないメッセージの直前のチェックポイントからデータの再プッシュを開始します。これにより、SDK は重複データを受信します。
変更追跡 SDK は消費チェックポイントをどのくらいの頻度で更新しますか?SDK 再起動時に重複データを受信することがあるのはなぜですか?
各メッセージを消費した後、変更追跡 SDK は `ackAsConsumed` を呼び出して ACK 返信をサーバーに送信する必要があります。サーバーが ACK を受信すると、メモリ内の消費チェックポイントを更新し、10 秒ごとに永続化します。最新の ACK が永続化される前に SDK が再起動した場合、サーバーはメッセージ損失を防ぐために、最後に永続化されたチェックポイントからメッセージのプッシュを開始します。これにより、SDK は重複メッセージを受信します。
1 つの変更追跡インスタンスで複数の RDS インスタンスをサブスクライブできますか?
いいえ、できません。1 つの変更追跡インスタンスは、1 つの RDS インスタンスのみをサブスクライブできます。
変更追跡インスタンスでデータ不整合が発生しますか?
いいえ、発生しません。変更追跡タスクはソースデータベースの変更のみをキャプチャし、データ不整合は関係ありません。使用されたデータが期待と異なる場合は、独自に問題をトラブルシューティングする必要があります。
サブスクリプションデータを使用する際に UserRecordGenerator を処理する方法
サブスクリプションデータを使用する際に、UserRecordGenerator: haven't receive records from generator for 5s のようなメッセージが表示された場合は、消費チェックポイントが増分データ収集モジュールのチェックポイント範囲内にあるかどうかを確認し、コンシューマーが期待通りに実行されていることを確認してください。
1 つの Topic で複数のパーティションを作成できますか?
いいえ、できません。グローバルメッセージ順序を保証するために、各サブスクリプショントピックにはパーティションが 1 つしかなく、パーティション 0 に固定されています。
変更追跡 SDK は Go 言語をサポートしていますか?
サンプルコードは dts-subscribe-demo にあります。
変更追跡 SDK は Python 言語をサポートしていますか?
サンプルコードについては、dts-subscribe-demo をご参照ください。
flink-dts-connector はサブスクリプションデータのマルチスレッド同時使用をサポートしていますか?
いいえ、サポートしていません。
データ検証に関する問題
データ検証タスクでデータ不整合が発生する一般的な原因
一般的な原因は次のとおりです。
移行または同期タスクに遅延があります。
ソースデータベースでデフォルト値付きのカラム追加が実行され、タスクに遅延があります。
DTS 以外のソースからターゲットデータベースにデータが書き込まれました。
マルチテーブルマージが有効なタスクのソースデータベースで DDL 操作が実行されました。
移行または同期タスクでデータベース、テーブル、および列名マッピング機能が使用されました。
スキーマ検証で isRelHasoids の違いが検出される理由
PostgreSQL 12 より前のバージョンでは、テーブル作成時に WITH OIDS を指定することで、グローバルに一意なオブジェクト識別子 (OID) フィールドを追加できます。ソースデータベースでテーブル作成時に WITH OIDS を指定し、ターゲットデータベースが WITH OIDS をサポートしない PostgreSQL の新しいバージョンである場合、`isRelHasoids` の違いが検出されます。
スキーマ検証タスクで検出された isRelHasoids の違いを懸念する必要がありますか?
いいえ、すべきではありません。
DTS はオブジェクト識別子 (OID) フィールドを同期または移行しますか?
いいえ、同期または移行しません。オブジェクト識別子 (OID) フィールドは WITH OIDS を指定した際に自動的に生成されます。DTS は、ターゲットデータベースがこのフィールドをサポートしているかどうかに関係なく、このデータを同期または移行しません。
テーブルにオブジェクト識別子 (OID) フィールドがあるかどうかを確認する方法
コマンド内の <table_name> を照会したいテーブル名に置き換えてください。
SQL コマンド:
SELECT relname AS table_name, relhasoids AS has_oids FROM pg_class WHERE relname = '<table_name>' AND relkind = 'r';クライアントコマンド:
\d+ <table_name>
その他の問題
データ同期または移行タスク中にターゲットデータベースのデータを変更した場合の影響
ターゲットデータベースのデータを変更すると、DTS タスクが失敗する可能性があります。移行または同期中にターゲットオブジェクトに対する操作を行うと、プライマリキーの競合や更新レコードの欠落が発生し、DTS タスクが失敗する可能性があります。ただし、DTS タスクを中断しない操作(例:移行または同期オブジェクトではないターゲットインスタンスのテーブルの作成およびデータ書き込み)は許可されています。
DTS はソースインスタンスからデータを読み取り、完全データ、スキーマデータ、および増分データをターゲットインスタンスに移行または同期するため、タスク中にターゲットデータに対して行われた変更は、ソースからのデータによって上書きされる可能性があります。
データ同期または移行タスク中にソースおよびターゲットデータベースの両方に同時に書き込みできますか?
はい、可能です。ただし、タスク実行中に DTS 以外のデータソースがターゲットデータベースに書き込むと、ターゲットデータまたは DTS インスタンスが異常になる可能性があります。
DTS インスタンス実行中にソースまたはターゲットデータベースのパスワードを変更した場合の影響
DTS インスタンスがエラーを報告し、タスクが中断されます。問題を解決するには、インスタンス ID をクリックしてインスタンス詳細を開きます。基本情報 タブで、ソースまたはターゲットアカウントのパスワードを変更します。その後、タスク管理 タブに移動し、失敗したタスクを 基本情報 セクションから再開します。
一部のソースまたはターゲットデータベースにパブリック IP が接続オプションとして表示されない理由
これは、ソースまたはターゲットデータベースの接続タイプ、タスクタイプ、およびデータベースタイプによって異なります。たとえば、MySQL データベースソースの場合、移行およびサブスクリプションタスクはパブリック IP 接続を使用できますが、同期タスクはパブリック IP 接続をサポートしていません。
DTS はクロスアカウントデータ移行または同期をサポートしていますか?
はい、サポートしています。構成方法の詳細については、「Alibaba Cloud アカウント間のタスク構成」をご参照ください。
ソースおよびターゲットデータベースを同じデータベースインスタンスにできますか?
はい、可能です。ソースおよびターゲットデータベースが同じインスタンスである場合、DTS インスタンスの失敗またはデータ損失を防ぐために、マッピング機能を使用してデータを分離および区別することを推奨します。詳細については、「データベース、テーブル、および列名のマッピング」をご参照ください。
Redis をターゲットとするタスクで "OOM command not allowed when used memory > 'maxmemory'" と報告される理由
ターゲット Redis インスタンスのストレージスペースが不足している可能性があります。ターゲット Redis インスタンスがクラスタアーキテクチャを使用している場合、1 つのシャードがメモリ制限に達している可能性があります。ターゲットインスタンスの仕様を向上させる必要があります。
AliyunDTSRolePolicy 権限ポリシーとは何ですか?どのような用途がありますか?
AliyunDTSRolePolicy ポリシーは、Alibaba Cloud アカウント配下の RDS や ECS などのクラウドリソースへの現在またはクロスアカウントアクセスを許可します。データ移行、同期、またはサブスクリプションタスクを構成して関連するクラウドリソース情報をアクセスする際に呼び出されます。詳細については、「DTS によるクラウドリソースへのアクセス許可」をご参照ください。
RAM ロール権限付与を実行する方法
コンソールに初めてログインすると、DTS が AliyunDTSDefaultRole ロールの権限付与を促します。コンソールのプロンプトに従って RAM 権限付与ページに移動し、権限付与を実行できます。詳細については、「DTS によるクラウドリソースへのアクセス許可」をご参照ください。
Alibaba Cloud アカウント(プライマリアカウント)を使用してコンソールにログインする必要があります。
DTS タスクに入力したアカウントパスワードを変更できますか?
はい、可能です。インスタンス ID をクリックしてインスタンス詳細に移動します。基本情報 タブで、パスワードの変更 をクリックして、ソースまたはターゲットアカウントのパスワードを変更できます。
DTS タスクシステムアカウントのパスワードは変更できません。
MaxCompute テーブルに _base サフィックスが付く理由
初期スキーマ同期
DTS は、ソースデータベースから同期するテーブルのスキーマ定義を MaxCompute に同期します。初期化中に、DTS はテーブル名に `_base` サフィックスを追加します。たとえば、ソーステーブルが `customer` の場合、MaxCompute のテーブルは `customer_base` になります。
初期完全データ同期
DTS は、ソースデータベースの同期対象テーブルのすべての既存データを、MaxCompute の宛先テーブル(`_base` で終わる)に同期します。たとえば、ソースデータベースの `customer` テーブルのデータは、MaxCompute の `customer_base` テーブルに同期されます。このデータは、その後の増分データ同期のベースラインとして使用されます。
説明このテーブルは、完全ベースラインテーブルとも呼ばれます。
増分データ同期
DTS は、MaxCompute に増分ログテーブルを作成します。このテーブルの名前は、宛先テーブル名に `_log` サフィックスを追加して形成されます(例:`customer_log`)。その後、DTS はソースデータベースから増分データをリアルタイムでこのテーブルに同期します。
説明増分ログテーブルの構造の詳細については、「増分ログテーブルのスキーマ」をご参照ください。
Kafka トピックを取得できません。対処方法
現在構成されている Kafka ブローカーにトピック情報がない可能性があります。次のコマンドを使用してトピックブローカーの分布を確認できます。
./bin/kafka-topics.sh --describe --zookeeper zk01:2181/kafka --topic topic_nameローカル MySQL インスタンスを RDS インスタンスのレプリカとして設定できますか?
はい、可能です。DTS のデータ移行機能を使用して、RDS インスタンスからオンプレミス自己管理 MySQL インスタンスへのリアルタイム同期を構成し、マスター-スレーブアーキテクチャを実装できます。
RDS インスタンスから新しく作成された RDS インスタンスにデータをコピーする方法
DTS データ移行を使用し、移行タイプとしてスキーマ移行、完全移行、および増分移行を選択します。構成方法の詳細については、「RDS インスタンス間のデータ移行」をご参照ください。
DTS は、1 つの RDS インスタンス内でデータベース名が異なるだけで同一のデータベースをコピーすることをサポートしていますか?
はい、サポートしています。DTS のオブジェクト名マッピング機能を使用して、1 つの RDS インスタンス内でデータベース名が異なるだけで同一のデータベースをコピーできます。
DTS インスタンスが常に遅延を示しています。対処方法
考えられる原因は次のとおりです。
同じソースデータベースインスタンス上で異なるアカウントを使用して複数の DTS タスクが作成され、インスタンス負荷が高くなっています。同じアカウントを使用してタスクを作成できます。
ターゲットデータベースインスタンスのメモリが不足しています。ビジネス運用を調整した後、ターゲットインスタンスを再起動できます。問題が解決しない場合は、ターゲットインスタンスの仕様を向上させるか、プライマリ-セカンダリ切り替えを実行できます。
説明プライマリ-セカンダリ切り替えにより、一時的なネットワーク切断が発生する可能性があります。アプリケーションに自動再接続メカニズムがあることを確認してください。
旧コンソールを使用して宛先データベースに同期または移行する際、フィールドがすべて小文字になります。対処方法
新しいコンソールを使用してタスクを構成し、宛先データベースオブジェクト名の大文字小文字の区別ポリシー機能を使用できます。詳細については、「宛先データベースオブジェクト名の大文字小文字の区別ポリシー」をご参照ください。
一時停止した DTS タスクを再開できますか?
ほとんどの場合、24 時間以内に一時停止した DTS タスクは再開できます。データ量が少ないタスクの場合、7 日以内に一時停止したタスクは再開できます。タスクを 6 時間以上一時停止しないことを推奨します。
一時停止したタスクを再開した後、進捗が 0 から始まる理由
タスクを再開した後、DTS は完了したデータを再照会し、残りのデータの処理を続けます。このプロセス中に、遅延によりタスク進捗が実際の進捗と異なる場合があります。
ロックレス DDL 変更の原則
ロックレス DDL 変更の主な原則の詳細については、「主な原則」をご参照ください。
DTS は特定のテーブルの同期または移行を一時停止することをサポートしていますか?
いいえ、サポートしていません。
タスクが失敗した場合、再購入する必要がありますか?
いいえ、必要ありません。元のタスクを再構成できます。
複数のタスクが同じ宛先にデータを書き込んだ場合の影響
データ不整合が発生する可能性があります。
更新後にインスタンスがロックされたままになる理由
ロックされた DTS インスタンスを更新した後、インスタンスのロック解除には時間がかかります。しばらくお待ちください。
DTS インスタンスのリソースグループを変更できますか?
はい、可能です。インスタンスの 基本情報 ページに移動します。基本情報 セクションで、リソースグループ名 の横にある 変更 をクリックして変更します。
DTS に Binlog 分析ツールはありますか?
DTS には binlog 分析ツールはありません。
増分タスクが常に 95% を示しています。これは正常ですか?
はい、正常です。増分タスクは継続的に実行され、完了しないため、進捗は 100% に到達しません。
7 日経過しても DTS タスクがリリースされない理由
凍結されたタスクは、7 日以上保存される場合があります。
すでに作成されたタスクのポートを変更できますか?
サポートされていません。
PolarDB-X 1.0 下で DTS タスクにアタッチされた RDS MySQL インスタンスをダウングレードできますか?
推奨されません。ダウングレードによりプライマリ-セカンダリ切り替えがトリガーされ、データ損失が発生する可能性があります。
DTS タスク実行中にソースまたはターゲットインスタンスをアップグレードまたはダウングレードできますか?
DTS タスク実行中にソースまたはターゲットインスタンスをアップグレードまたはダウングレードすると、タスクの遅延またはデータ損失が発生する可能性があります。タスク実行中はインスタンス仕様を変更しないことを推奨します。
DTS タスクがソースおよびターゲットインスタンスに与える影響
完全データ初期化は、ソースおよびターゲットデータベースの読み取りおよび書き込みリソースを消費し、データベース負荷を増加させます。完全データ初期化タスクは、ピーク時以外の時間帯に実行することを推奨します。
DTS タスクの典型的な遅延時間
DTS タスクの遅延時間は推定できません。これは、ソースインスタンス負荷、ネットワーク帯域幅、ネットワーク遅延、ターゲットインスタンスの書き込みパフォーマンスなど、複数の要因に依存するためです。
データ伝送コンソールが自動的に Data Management (DMS) コンソールにリダイレクトされた場合、旧データ伝送コンソールに戻る方法
Data Management (DMS) コンソールで、右下隅の  アイコンをクリックし、その後
アイコンをクリックし、その後  アイコンをクリックして旧 Data Transmission Service コンソールに戻ります。
アイコンをクリックして旧 Data Transmission Service コンソールに戻ります。
DTS はデータ暗号化をサポートしていますか?
DTS は、ソースからのデータ読み取りまたはターゲットへのデータ書き込み時に SSL 暗号化を使用したソースまたはターゲットデータベースへの安全なアクセスをサポートしています。ただし、DTS は転送中のデータ暗号化をサポートしていません。
DTS は ClickHouse をソースまたはターゲットとしてサポートしていますか?
いいえ、しません。
DTS は、ソースまたはデスティネーションとして AnalyticDB for MySQL 2.0 に対応していますか?
AnalyticDB for MySQL 2.0 は、送信先としてのみサポートされています。送信先として AnalyticDB for MySQL 2.0 を使用するソリューションは、新コンソールではまだリリースされておらず、旧コンソールでのみ設定できます。
新しく作成されたタスクがコンソールに表示されない理由
誤ったタスクリストを選択しているか、フィルターが適用されている可能性があります。適切なタスクリストで正しいフィルターオプション(例:正しいリージョンおよびリソースグループ)を選択できます。
作成済みタスクで無効化された設定項目を変更できますか?
サポートされていません。
遅延アラートおよびしきい値を構成する方法
DTS は監視およびアラート機能を提供しています。コンソールで重要な監視メトリクスのアラートルールを設定し、実行状況を把握できます。構成方法の詳細については、「監視の構成」をご参照ください。
長期間前に失敗したタスクの失敗理由を確認できますか?
いいえ、確認できません。タスクが長期間(例:7 日以上)失敗している場合、関連するログはクリアされ、失敗理由を確認できません。
長期間前に失敗したタスクを復元できますか?
いいえ、復元できません。タスクが長期間(例:7 日以上)失敗している場合、関連するログはクリアされ、復元できません。タスクを再構成する必要があります。
rdsdt_dtsacct アカウントとは何ですか?
rdsdt_dtsacct アカウントを自分で作成していない場合、DTS によって作成された可能性があります。DTS は、一部のデータベースインスタンスに組み込みアカウント rdsdt_dtsacct を作成し、ソースおよびターゲットデータベースインスタンスに接続します。
SQL Server でヒープテーブル、プライマリキーのないテーブル、圧縮テーブル、計算列を含むテーブル、スパース列を含むテーブルを確認する方法
次の SQL 文を実行して、ソースデータベースにこれらの特性を持つテーブルが含まれているかどうかを確認できます。
ソースデータベースのヒープテーブルを確認:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id IN (SELECT object_id FROM sys.indexes WHERE index_id = 0);プライマリキーのないテーブルを確認:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id NOT IN (SELECT parent_object_id FROM sys.objects WHERE type = 'PK');ソースデータベースでプライマリキー列がクラスター化インデックス列に含まれていないテーブルを確認:
SELECT s.name schema_name, t.name table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id WHERE t.type = 'U' AND s.name NOT IN('cdc', 'sys') AND t.name NOT IN('systranschemas') AND t.object_id IN ( SELECT pk_colums_counter.object_id AS object_id FROM (select pk_colums.object_id, sum(pk_colums.column_id) column_id_counter from (select sic.object_id object_id, sic.column_id FROM sys.index_columns sic, sys.indexes sis WHERE sic.object_id = sis.object_id AND sic.index_id = sis.index_id AND sis.is_primary_key = 'true') pk_colums group by object_id) pk_colums_counter inner JOIN ( select cluster_colums.object_id, sum(cluster_colums.column_id) column_id_counter from (SELECT sic.object_id object_id, sic.column_id FROM sys.index_columns sic, sys.indexes sis WHERE sic.object_id = sis.object_id AND sic.index_id = sis.index_id AND sis.index_id = 1) cluster_colums group by object_id ) cluster_colums_counter ON pk_colums_counter.object_id = cluster_colums_counter.object_id and pk_colums_counter.column_id_counter != cluster_colums_counter.column_id_counter);ソースデータベースの圧縮テーブルを確認:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.objects t, sys.schemas s, sys.partitions p WHERE s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id = p.object_id AND p.data_compression != 0;計算列を含むテーブルを確認:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id IN (SELECT object_id FROM sys.columns WHERE is_computed = 1);スパース列を含むテーブルを確認:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id IN (SELECT object_id FROM sys.columns WHERE is_sparse = 1);
ソースとターゲットのスキーマ不整合を処理する方法
マッピング機能を使用して、ソースとターゲットの間で列マッピング関係を確立することを試みることができます。詳細については、「データベース、テーブル、および列名のマッピング」をご参照ください。
列タイプの変更はサポートされていません。
データベース、テーブル、および列マッピングで列タイプを変更できますか?
いいえ、できません。
DTS はソースデータベースの読み取り速度を制限することをサポートしていますか?
いいえ、サポートしていません。タスクを実行する前に、ソースデータベースのパフォーマンス(IOPS やネットワーク帯域幅が要件を満たしているかどうかなど)を評価する必要があります。また、ピーク時以外の時間帯にタスクを実行することを推奨します。
MongoDB (シャードクラスター アーキテクチャ) の孤立ドキュメントをクリーンアップする方法
孤立ドキュメントの確認
Mongo Shell を使用して MongoDB シャードクラスターインスタンスに接続します。
MongoDB インスタンスへの接続方法の詳細については、「Mongo Shell を使用した MongoDB シャードクラスターインスタンスへの接続」をご参照ください。
次のコマンドを実行して、ターゲットデータベースに切り替えます。
use <db_name>次のコマンドを実行して、孤立ドキュメントを確認します。
db.<coll_name>.find().explain("executionStats")説明各シャードの
executionStatsのSHARDING_FILTERステージのchunkSkipsフィールドを確認します。このフィールドの値が 0 でない場合、そのシャードに孤立ドキュメントが存在します。次の例では、
SHARDING_FILTERステージの前に、FETCHステージが 102 ドキュメント ("nReturned": 102) を返しました。その後、SHARDING_FILTERステージが 2 つの孤立ドキュメント ("chunkSkips": 2) をフィルタリングし、100 ドキュメント ("nReturned": 100) が返されました。"stage" : "SHARDING_FILTER", "nReturned" : 100, ...... "chunkSkips" : 2, "inputStage" : { "stage" : "FETCH", "nReturned" : 102,SHARDING_FILTERステージの詳細については、「MongoDB マニュアル」をご参照ください。
孤立ドキュメントのクリーンアップ
複数のデータベースがある場合、各データベースの孤立ドキュメントをクリーンアップする必要があります。
ApsaraDB for MongoDB
メジャーバージョンが MongoDB 4.2 より前、またはマイナーバージョンが 4.0.6 より前のインスタンスでクリーンアップスクリプトを実行すると、エラーが報告されます。インスタンスの現在のバージョンを確認するには、「マイナーバージョンリリースノート」をご参照ください。メジャーバージョンまたはマイナーバージョンをアップグレードするには、「データベースのメジャーバージョンのアップグレード」および「データベースのマイナーバージョンのアップグレード」をご参照ください。
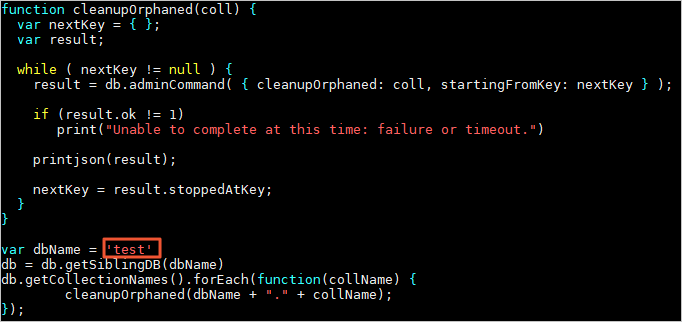
孤立ドキュメントをクリーンアップするには、cleanupOrphaned コマンドを使用できます。このコマンドの使用方法は、MongoDB 4.4 以降と MongoDB 4.2 以前で若干異なります。以下のセクションで必要な操作を説明します。
MongoDB 4.4 以降
シャードクラスターインスタンスに接続できるサーバーで、孤立ドキュメントをクリーンアップする JavaScript (JS) スクリプトを作成し、スクリプト名を
cleanupOrphaned.jsとします。説明このスクリプトは、複数のシャードノードにわたる複数のデータベース内のすべてのコレクションから孤立ドキュメントをクリーンアップ します。特定のコレクションから孤立ドキュメントをクリーンアップするには、JS スクリプトを変更できます。
// シャードインスタンス名のリスト var shardNames = ["shardName1", "shardName2"]; // データベースのリスト var databasesToProcess = ["database1", "database2", "database3"]; shardNames.forEach(function(shardName) { // 指定されたデータベースリストを走査 databasesToProcess.forEach(function(dbName) { var dbInstance = db.getSiblingDB(dbName); // データベースインスタンス内のすべてのコレクション名を取得 var collectionNames = dbInstance.getCollectionNames(); // 各コレクションを走査 collectionNames.forEach(function(collectionName) { // コレクションの完全名 var fullCollectionName = dbName + "." + collectionName; // cleanupOrphaned コマンドを構築 var command = { runCommandOnShard: shardName, command: { cleanupOrphaned: fullCollectionName } }; // コマンドを実行 var result = db.adminCommand(command); if (result.ok) { print("Cleaned up orphaned documents for collection " + fullCollectionName + " on shard " + shardName); printjson(result); } else { print("Failed to clean up orphaned documents for collection " + fullCollectionName + " on shard " + shardName); } }); }); });スクリプト内の
shardNamesおよびdatabasesToProcessパラメーターの値を変更する必要があります。以下のリストはパラメーターの説明です。shardNames:孤立ドキュメントをクリーンアップするシャードノードの ID の配列。インスタンス詳細ページのシャードリストセクションから ID を取得できます。例:d-bp15a3796d3a****。databasesToProcess:孤立ドキュメントをクリーンアップするデータベースの名前の配列。
cleanupOrphaned.jsスクリプトが配置されているディレクトリで、次のコマンドを実行して孤立ドキュメントをクリーンアップします。mongo --host <Mongoshost> --port <Primaryport> --authenticationDatabase <database> -u <username> -p <password> cleanupOrphaned.js > output.txt以下の表はパラメーターの説明です。
パラメーター
説明
<Mongoshost>シャードクラスターインスタンスの Mongos ノードのエンドポイント。形式:
s-bp14423a2a51****.mongodb.rds.aliyuncs.com。<Primaryport>シャードクラスターインスタンスの Mongos ノードのポート番号。デフォルト値は 3717 です。
<database>認証データベースの名前。これはデータベースアカウントが属するデータベースです。
<username>データベースアカウント。
<password>データベースアカウントのパスワード。
output.txt実行結果が出力ファイルに保存されます。
MongoDB 4.2 以前
シャードクラスターインスタンスに接続できるサーバーで、孤立ドキュメントをクリーンアップする JS スクリプトを作成し、スクリプト名を
cleanupOrphaned.jsとします。説明このスクリプトは、複数のシャードノードにわたる指定されたデータベース内の指定されたコレクションから孤立ドキュメントをクリーンアップ します。データベース内の複数のコレクションから孤立ドキュメントをクリーンアップするには、
fullCollectionNameパラメーターを変更してスクリプトを複数回実行するか、ループで実行するようにスクリプトを変更できます。function cleanupOrphanedOnShard(shardName, fullCollectionName) { var nextKey = { }; var result; while ( nextKey != null ) { var command = { runCommandOnShard: shardName, command: { cleanupOrphaned: fullCollectionName, startingFromKey: nextKey } }; result = db.adminCommand(command); printjson(result); if (result.ok != 1 || !(result.results.hasOwnProperty(shardName)) || result.results[shardName].ok != 1 ) { print("Unable to complete at this time: failure or timeout.") break } nextKey = result.results[shardName].stoppedAtKey; } print("cleanupOrphaned done for coll: " + fullCollectionName + " on shard: " + shardName) } var shardNames = ["shardName1", "shardName2", "shardName3"] var fullCollectionName = "database.collection" shardNames.forEach(function(shardName) { cleanupOrphanedOnShard(shardName, fullCollectionName); });スクリプト内の
shardNamesおよびfullCollectionNameパラメーターの値を変更する必要があります。以下のリストはパラメーターの説明です。shardNames:孤立ドキュメントをクリーンアップするシャードノードの ID の配列。インスタンス詳細ページのシャードリストセクションから ID を取得できます。例:d-bp15a3796d3a****。fullCollectionName:孤立ドキュメントをクリーンアップするコレクションの名前に置き換えます。database_name.collection_name形式を使用します。
cleanupOrphaned.jsスクリプトが配置されているディレクトリで、次のコマンドを実行して孤立ドキュメントをクリーンアップします。mongo --host <Mongoshost> --port <Primaryport> --authenticationDatabase <database> -u <username> -p <password> cleanupOrphaned.js > output.txt以下の表はパラメーターの説明です。
パラメーター
説明
<Mongoshost>シャードクラスターインスタンスの Mongos ノードのエンドポイント。形式:
s-bp14423a2a51****.mongodb.rds.aliyuncs.com。<Primaryport>シャードクラスターインスタンスの Mongos ノードのポート番号。デフォルト値は 3717 です。
<database>認証データベースの名前。これはデータベースアカウントが属するデータベースです。
<username>データベースアカウント。
<password>データベースアカウントのパスワード。
output.txt実行結果が出力ファイルに保存されます。
自己管理 MongoDB
自己管理 MongoDB データベースに接続できるサーバーで、cleanupOrphaned.js スクリプトファイルをダウンロードします。
wget "https://docs-aliyun.cn-hangzhou.oss.aliyun-inc.com/assets/attach/120562/cn_zh/1564451237979/cleanupOrphaned.js"cleanupOrphaned.js スクリプトファイルを変更します。
testを孤立ドキュメントをクリーンアップするデータベースの名前に置き換えます。重要複数のデータベースがある場合、ステップ 2 とステップ 3 を繰り返す必要があります。
次のコマンドを実行して、シャードノード上の指定されたデータベース内のすべてのコレクションから孤立ドキュメントをクリーンアップします。
説明各シャードノードの孤立ドキュメントをクリーンアップするために、このステップを繰り返す必要があります。
mongo --host <Shardhost> --port <Primaryport> --authenticationDatabase <database> -u <username> -p <password> cleanupOrphaned.js説明<Shardhost>:シャードノードの IP アドレス。
<Primaryport>:シャード内のプライマリノードのサービスポート。
<database>:認証データベースの名前。これはデータベースアカウントが属するデータベースです。
<username>:データベースにログインするためのアカウント。
<password>:データベースアカウントのパスワード。
例:
この例では、自己管理 MongoDB データベースに 3 つのシャードノードがあります。これら 3 つのノードそれぞれの孤立ドキュメントをクリーンアップする必要があります。
mongo --host 172.16.1.10 --port 27018 --authenticationDatabase admin -u dtstest -p 'Test123456' cleanupOrphaned.jsmongo --host 172.16.1.11 --port 27021 --authenticationDatabase admin -u dtstest -p 'Test123456' cleanupOrphaned.jsmongo --host 172.16.1.12 --port 27024 --authenticationDatabase admin -u dtstest -p 'Test123456' cleanupOrphaned.js
例外処理
孤立ドキュメントに対応する名前空間にアイドルカーソルが存在する場合、クリーンアッププロセスが完了しない可能性があります。孤立ドキュメントの対応する mongod ログには、次の情報が含まれます。
Deletion of DATABASE.COLLECTION range [{ KEY: VALUE1 }, { KEY: VALUE2 }) will be scheduled after all possibly dependent queries finishMongo Shell を使用して mongod に接続し、次のコマンドを実行して、現在のシャードにアイドルカーソルが存在するかどうかを確認できます。存在する場合は、mongod を再起動 するか、killCursors コマンドを使用してすべてのアイドルカーソルをクリーンアップする必要があります。その後、孤立ドキュメントのクリーンアップを再試行できます。詳細については、「JIRA チケット」をご参照ください。
db.getSiblingDB("admin").aggregate( [{ $currentOp : { allUsers: true, idleCursors: true } },{ $match : { type: "idleCursor" } }] )MongoDB シャードクラスター アーキテクチャでデータ分布が不均等な場合の対処方法
Balancer 機能を有効にし、プレシャーディングを実行して、大部分のデータが単一のシャードに書き込まれる(データスキュー)問題を解決できます。
Balancer の有効化
Balancer が無効になっているか、Balancer ウィンドウ期間に達していない場合、Balancer 機能を有効にするか、Balancer ウィンドウを一時的にキャンセルして、すぐにデータバランスを開始できます。
MongoDB シャードクラスターインスタンスに接続します。
mongos ノードコマンドウィンドウで、config データベースに切り替えます。
use config必要に応じて次のコマンドを実行します。
Balancer 機能を有効化
sh.setBalancerState(true)Balancer ウィンドウ期間を一時的にキャンセル
db.settings.updateOne( { _id : "balancer" }, { $unset : { activeWindow : true } } )
プレシャーディング
MongoDB は範囲シャーディングとハッシュシャーディングをサポートしています。プレシャーディングにより、チャンク値を複数のシャードノードにできるだけ均等に分散させることができます。これにより、DTS データ同期または移行中に負荷が均等になります。
ハッシュシャーディング
numInitialChunks パラメーターを使用して、便利かつ迅速にプレシャーディングを実行できます。デフォルト値は シャード数 × 2、最大値は シャード数 × 8192 です。詳細については、「sh.shardCollection()」をご参照ください。
sh.shardCollection("phonebook.contacts", { last_name: "hashed" }, false, {numInitialChunks: 16384})範囲シャーディング
ソース MongoDB データベースもシャードクラスターである場合、
config.chunksからソース MongoDB データベースの対応するシャードテーブルのチャンク範囲を取得し、後続のプレシャーディングコマンドの<split_value>の参照値として使用できます。ソース MongoDB データベースがレプリカセットである場合、
findコマンドのみを使用してシャードキーの具体的な範囲を決定し、合理的な分割ポイントを設計できます。# シャードキーの最小値を取得 db.<coll>.find().sort({<shardKey>:1}).limit(1) # シャードキーの最大値を取得 db.<coll>.find().sort({<shardKey>:-1).limit(1)
コマンド形式
splitAt コマンドを例として使用します。詳細については、「sh.splitAt()」、「sh.splitFind()」、および「シャードクラスターでのチャンクの分割」をご参照ください。
sh.splitAt("<db>.<coll>", {"<shardKey>":<split_value>})例文
sh.splitAt("test.test", {"id":0})
sh.splitAt("test.test", {"id":50000})
sh.splitAt("test.test", {"id":75000})プレシャーディング操作を完了した後、mongos ノードで sh.status() コマンドを実行して、プレシャーディングの効果を確認できます。
コンソールタスクリストで 1 ページに表示されるインスタンス数を設定する方法
この手順は同期インスタンスを例として使用します。
宛先リージョンの同期タスクリストページに移動します。次の 2 つの方法のいずれかを使用できます。
DTS コンソールから
Data Transmission Service (DTS) コンソール にログインします。
左側のナビゲーションウィンドウで、データ同期 をクリックします。
ページ左上隅で、同期インスタンスが配置されているリージョンを選択します。
DMS コンソールから
説明実際の操作は DMS コンソールのモードおよびレイアウトによって異なる場合があります。詳細については、「シンプルモード」および「DMS インターフェイスのレイアウトとスタイルのカスタマイズ」をご参照ください。
Data Management (DMS) にログインします。
トップメニューバーで、 を選択します。
データ同期タスク の右側で、同期インスタンスが配置されているリージョンを選択します。
ページ右側で、スクロールバーをページ下部までドラッグします。
ページ右下隅で、1 ページあたりの件数 を選択します。
説明1 ページあたりの件数 の利用可能な値は、10、20、または 50 です。
DTS インスタンスで ZooKeeper 接続タイムアウトエラーが発生した場合の対処方法
インスタンスを再起動して回復するかどうかを試すことができます。インスタンスの再起動手順については、「DTS インスタンスの起動」をご参照ください。
CEN で DTS ネットワークセグメントを削除した後、自動的に再追加される理由
データベースを DTS に接続するために Cloud Enterprise Network (CEN) Basic Edition トランジットルーターを使用している可能性があります。このデータベースを使用して DTS インスタンスを作成すると、CEN で DTS ネットワークセグメントを削除しても、DTS は対応するルーターにサーバーの IP アドレス範囲を自動的に追加します。
DTS はタスクエクスポートをサポートしていますか?
いいえ、サポートしていません。
Java を使用して OpenAPI を呼び出す方法
Java を使用して OpenAPI を呼び出すプロセスは、Python を使用する場合と同様です。Python の例については、「Python SDK 呼び出し例」をご参照ください。Java のサンプルコードを見つけるには、「 Data Transmission Service DTS SDK」ページに移動し、すべての言語 の下でプログラミング言語を選択してください。
API を使用して同期または移行タスクの ETL 機能を構成する方法
API 操作の `Reserve` パラメーターで、etlOperatorCtl や etlOperatorSetting などの共通パラメーターを使用して機能を構成できます。詳細については、「ConfigureDtsJob」および「Reserve パラメーターの説明」をご参照ください。
DTS は Azure SQL Database をサポートしていますか?
はい、サポートしています。Azure SQL Database をソースデータベースとして使用する場合、SQL Server 増分同期モード を 増分同期のための CDC インスタンスのポーリングとクエリ に設定する必要があります。
DTS 同期または移行が完了した後、ソースデータベースのデータは保持されますか?
はい、保持されます。DTS はソースデータベースからデータを削除しません。ソースデータベースのデータを保持する必要がない場合は、自分で削除する必要があります。
同期または移行インスタンスの実行開始後にレートを調整できますか?
サポートされています。詳細については、「移行レートの調整」をご参照ください。
DTS は同期または移行の時間範囲サンプリングをサポートしていますか?
いいえ、サポートしていません。
データ同期または移行中に、ターゲットデータベースにデータテーブルを手動で作成する必要がありますか?
スキーマタスクをサポートする DTS インスタンス(スキーマ同期またはスキーマ移行)の場合、同期タイプ を スキーマ同期 に設定するか、移行タイプ を スキーマ移行 に設定すれば、ターゲットデータベースにデータテーブルを手動で作成する必要はありません。
データ同期または移行中に、ソースおよびターゲットデータベースのネットワークを接続する必要がありますか?
いいえ、必要ありません。
パブリックネットワークを使用してクロスアカウント DTS タスクを構成する場合、RAM 権限付与を構成する必要がありますか?
いいえ、必要ありません。DTS タスクを構成する際に、データベースインスタンスの アクセス方法 を パブリック IP アドレス に設定します。
データ同期タスクは、データベースインスタンスへの パブリック IP アドレス を使用した接続をサポートしていません。
DTS を使用してデータ同期または移行を行う際、ターゲットの既存データは上書きされますか?
データ同期を例にとると、DTS のデフォルト動作と関連パラメーターは次のとおりです。
DTS のデフォルト動作
同期タスクの実行中にプライマリキーまたはユニークキーの競合が発生した場合:
テーブルスキーマが同じで、ターゲットデータベースのレコードがソースデータベースのレコードと同じプライマリキーまたはユニークキー値を持つ場合:
完全同期中、DTS はターゲットクラスターのレコードを保持します。ソースデータベースの対応するレコードは同期されません。
増分同期中、ソースデータベースのレコードがターゲットデータベースのレコードを上書きします。
テーブルスキーマが異なる場合、初期データ同期が失敗する可能性があります。これにより、一部の列データのみが同期されるか、完全に同期が失敗する可能性があります。慎重に進めてください。
関連パラメーター
タスク構成中に、競合するテーブルの処理モード パラメーターを通じてデータ処理を管理できます。
エラーの事前チェックと報告:ターゲットデータベースに同じ名前のテーブルが存在するかどうかをチェックします。同じ名前のテーブルが存在しない場合、事前チェックはパスします。同じ名前のテーブルが存在する場合、事前チェックは失敗し、データ同期タスクは開始されません。
説明ターゲットデータベースで同じ名前のテーブルを削除または名前変更できない場合は、別のテーブル名にマッピングできます。詳細については、「テーブルおよび列名のマッピング」をご参照ください。
エラーを無視して続行:ターゲットデータベースでの重複テーブル名のチェックをスキップします。
警告エラーを無視して続行 を選択すると、データ不整合が発生し、ビジネスにリスクが及ぶ可能性があります。例:
テーブルスキーマが同じで、ターゲットデータベースのレコードがソースデータベースのレコードと同じプライマリキーまたはユニークキー値を持つ場合:
完全同期中、DTS はターゲットクラスターのレコードを保持します。ソースデータベースの対応するレコードは同期されません。
増分同期中、ソースデータベースのレコードがターゲットデータベースのレコードを上書きします。
テーブルスキーマが異なる場合、初期データ同期が失敗する可能性があります。これにより、一部の列データのみが同期されるか、完全に同期が失敗する可能性があります。慎重に進めてください。
推奨事項
データ整合性を確保するには、ビジネスが許容する場合、ターゲットテーブルを削除して DTS タスクを再構成することを推奨します。