ワークフローのオーケストレーション中にタスクを高速化するには、ファンインとファンアウトを使用してタスクを複数のサブタスクに分割し、サブタスクを並行して実行し、結果を集計します。 分散Argoワークフロー用のKubernetesクラスター (ワークフロークラスター) は、有向非巡回グラフ (DAG) 動的ファンインおよびファンアウトをサポートしています。これにより、自動スケーリングを使用して数万個のvCPUをスケジュールし、効率を向上させ、タスクの完了後にリソースを再利用してコストを節約できます。 このトピックでは、ワークフロークラスターでArgoワークフローを使用して、動的なファンインとファンアウトを実装する方法について説明します。
背景情報
ファンインとファンアウト

ファンインとファンアウトは、並行タスクを効率的に処理するために一般的に使用されます。 タスクを分割 (ファンイン) し、結果を集約 (ファンアウト) することで、複数のvCPUとコンピューティングインスタンスを完全に利用して、大量のデータを処理できます。
上の図では、DAGを使用して、ワークフローオーケストレーション中にファンインとファンアウトを実装できます。 静的 (静的DAG) または動的 (動的DAG) にタスクをサブタスクに分割できます。
静的DAG: サブタスクのカテゴリは固定されています。 たとえば、データ収集シナリオでは、データベース1とデータベース2からデータを収集し、結果を集計する必要があります。
動的DAG: タスクは動的にサブタスクに分割されます。 分割は、親タスクの出力に依存します。
上の図では、タスクAは処理するデータセットをスキャンします。 サブタスク (Bn) は、サブディレクトリなどのサブデータセットを処理するために起動される。 各サブタスクは、サブデータセットに対応する。 Bnサブタスクが完了した後、タスクCは結果を集約する。 サブタスクの数は、タスクAの出力に依存します。タスクAで分割ルールを定義できます。
分散ArgoワークフローのKubernetesクラスター
大きなタスクを大幅に高速化するには、大きなタスクを数千のサブタスクに分割する必要があります。 これらのサブタスクを同時に実行できるようにするには、数万のvCPUをスケジュールする必要があります。 ただし、同時サブタスクはリソースを求めて競合します。 データセンターのオンプレミスコンピューティングリソースは、リソース需要を満たすことができません。
たとえば、自動運転シミュレーションタスクのアルゴリズムを最適化した後、回帰テストを実行してすべての運転シナリオをシミュレートする必要があります。 各運転シナリオはサブタスクです。 イテレーションを高速化するには、すべての運転シナリオでテストを同時に実行します。
上記の問題を解決するには、Kubernetesクラスターfor distributed Argo workflowを使用してワークフローを調整します。 Argoワークフローをワークフロークラスターでホストし、包括的な技術サポートを提供し、動的DAGファンインとファンアウトを実装し、自動スケーリングを使用してクラウド上のコンピューティングリソースをスケジュールして、数万のvCPUに基づいて多数のサブタスクを同時に実行できます。 サブタスクの完了後にリソースを再利用して、コストを節約することもできます。 このソリューションは、データ処理、機械学習、シミュレーション計算、およびCI/CDシナリオに適用されます。
Argo Workflowsは、Cloud Native Computing Foundation (CNCF) の段階的なプロジェクトです。 クラウドネイティブセクターのワークフローオーケストレーションをターゲットにし、Kubernetes CustomResourceDefinitions (CRD) を使用してスケジュールされたタスクとDAGワークフローをオーケストレーションし、Kubernetesポッドで実行します。 詳細については、「Argoワークフロー」をご参照ください。
Argoワークフローを使用したファンインとファンアウトの実装
背景情報
Argoワークフローを使用してファンインとファンアウトを実装する方法を次の例に示します。
動的DAGファンインおよびファンアウトワークフローを作成して、Object Storage Service (OSS) バケット内の大きなログファイルを複数のサブファイルに分割します。 複数のサブタスクを起動して、各サブファイルのキーワード数をカウントし、結果をマージします。
手順
OSSボリュームをマウントして、ワークフローがOSSボリューム内のオブジェクトをローカルファイルとして読み取ることができるようにします。
詳しくは、『Use volumes』をご参照ください。
次のYAMLコンテンツに基づいてワークフローを作成します。
詳細については、「ワークフローの作成」をご参照ください。
ダイナミックDAGを使用して、ファンインとファンアウトを実装します。
大きなファイルを分割する分割タスクを作成すると、タスクの標準出力にJSON文字列が生成されます。 文字列には、各サブタスクのpartIdが含まれます。 例:
["0", "1", "2", "3", "4"]すべてのMapタスクは、
{{item}}を入力パラメーターとして起動します。 各Mapタスクは、withParamを使用してSplitタスクの出力を参照し、JSON文字列を解析して{{item}}を取得します。- name: map template: map arguments: parameters: - name: partId value: '{{item}}' depends: "split" withParam: '{{tasks.split.outputs.result}}'
詳細については、「Argoワークフロー」をご参照ください。
ワークフローの実行後、ACK Oneコンソールにログインして、DAGプロセスと結果を表示できます。
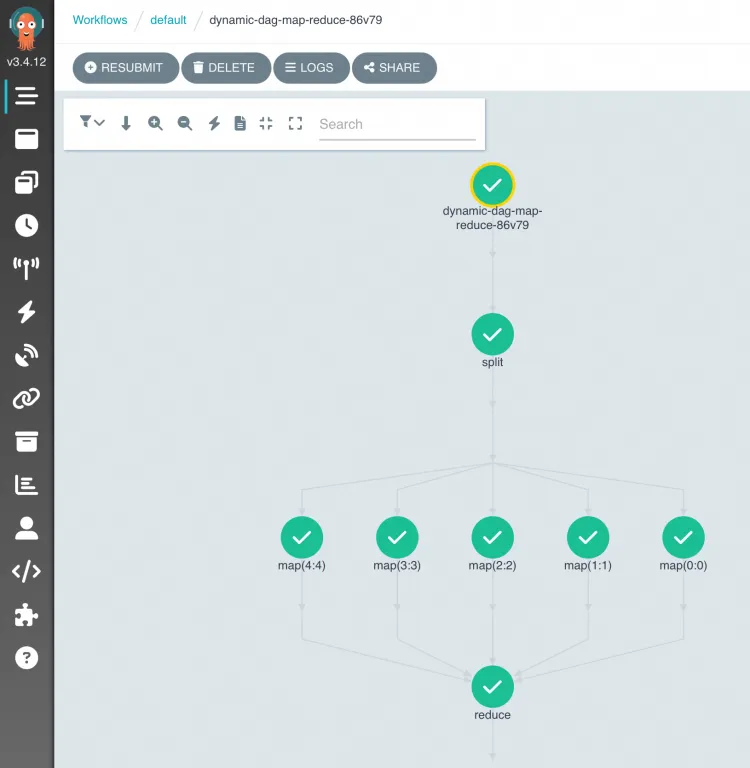
OSSオブジェクトリストでは、log-count-data.txtは入力ログファイル、split-outputおよびcout-outputは中間結果を格納するディレクトリ、result.jsonは出力ファイルです。
ソースコード
関連ドキュメント
分散Argoワークフロー用のKubernetesクラスターの詳細については、「ACK Oneの概要」をご参照ください。
Argoワークフローの詳細については、「Argoワークフロー」をご参照ください。
ACK Oneについてご質問がある場合は、DingTalkグループ35688562に参加してください。