DataWorks の DataStudio サービスでは、定期タスクの開発およびスケジューリングプロパティを定義できます。DataStudio はオペレーションセンターと連携して、MaxCompute、Hologres、E-MapReduce (EMR) などのさまざまなタイプのコンピュートエンジンのタスクに、可視化された開発インターフェイスを提供します。可視化された開発インターフェイスで設定を構成して、インテリジェントなコード開発、ワークフローでの複数エンジンタスクのオーケストレーション、および標準化されたタスクのデプロイメントを実行できます。これにより、オフラインデータウェアハウス、リアルタイムデータウェアハウス、およびアドホック分析システムを構築して、効率的で安定したデータ生成を保証できます。このトピックでは、DataStudio で使用される用語、DataStudio が提供する機能、および DataStudio でのデータ開発前の準備について説明します。
DataStudio ページに移動
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[データ開発へ] をクリックします。
DataStudio は、PC の Chrome バージョン 69 以降でのみサポートされています。
モジュールの紹介
機能概要
次の図は、DataStudio が提供する主な機能を示しています。詳細については、このトピックの「付録: データ開発関連の用語」セクションをご参照ください。
機能 | 説明 |
オブジェクトの編成と管理 | DataStudio は、DataWorks のオブジェクトを編成および管理するメカニズムを提供します。
詳細については、「ワークフローの作成」およびこのトピックの「管理モード」セクションをご参照ください。 説明 各 ワークスペース の DataStudio で作成できるワークフローとオブジェクトの最大数に関する制限:
現在のワークスペースのワークフローとオブジェクトの数が上限に達した場合、ワークフローやオブジェクトをそれ以上作成することはできません。 |
タスク開発 |
DataWorks でサポートされているノードタイプについては、「サポートされているノードタイプ」をご参照ください。 |
タスクスケジューリング |
タスクスケジューリングの詳細については、「時間プロパティの設定」および「スケジューリング依存関係の設定ガイド」をご参照ください。 |
タスクのデバッグ | タスクまたはワークフローをデバッグできます。詳細については、「デバッグ手順」をご参照ください。 |
プロセス制御 | DataStudio は、標準化されたタスクのデプロイメントメカニズムと、プロセス制御を実行するためのさまざまなメソッドを提供します。プロセス制御のために、以下を含むがこれらに限定されない操作を実行できます: |
その他の機能 |
|
DataStudio ページの紹介
DataStudio ページの機能 で説明されている手順に従って、DataStudio ページの各モジュールの機能を使用できます。
開発プロセス
DataWorks DataStudio では、さまざまなコンピュートエンジンタイプのリアルタイム同期タスク、バッチ同期タスク、バッチ処理タスク、および手動トリガータスクを作成できます。データ同期の詳細については、「データ統合」をご参照ください。さまざまなコンピュートエンジンタイプのタスクの構成要件は異なります。タスクタイプに基づいてタスクを開発する前に、DataWorks でのさまざまなコンピュートエンジンタイプのタスクの開発に関する注意事項と関連する指示に注意してください。
さまざまなコンピュートエンジンタイプのタスクの開発に関する指示: DataWorks にさまざまなデータソースを追加して、DataWorks でタスクを開発できます。さまざまなコンピュートエンジンタイプのタスクの構成要件は異なります。詳細については、次のトピックをご参照ください:
一般的な開発プロセス: 次の 2 つのワークスペースモードが利用可能です: 標準モードと基本モード。ノード開発プロセスはワークスペースモードによって異なります。
標準モードのワークスペースでのタスク開発プロセス

基本モードのワークスペースでのタスク開発プロセス
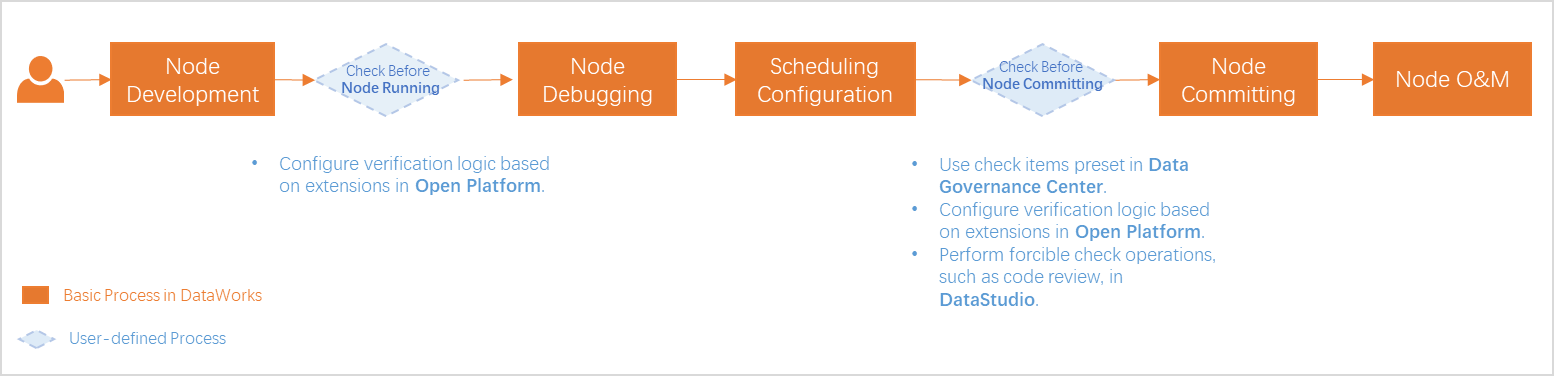
基本プロセス: たとえば、標準モードのワークスペースでタスクを開発する場合、開発プロセスには、開発、デバッグ、スケジューリング設定の構成、タスクのコミット、タスクのデプロイメント、および O&M の各段階が含まれます。詳細については、「一般的な開発プロセス」をご参照ください。
プロセス制御: タスク開発中に、DataStudio が提供する コードレビュー や スモークテスト などの操作を実行し、データガバナンスセンター にプリセットされたチェック項目や Open Platform の拡張機能に基づいてカスタマイズされた検証ロジックを使用して、タスク開発に関する指定された標準と要件が満たされていることを確認できます。
説明プロセス制御操作はワークスペースモードによって異なります。実際のプロセス制御操作が優先されます。
管理モード
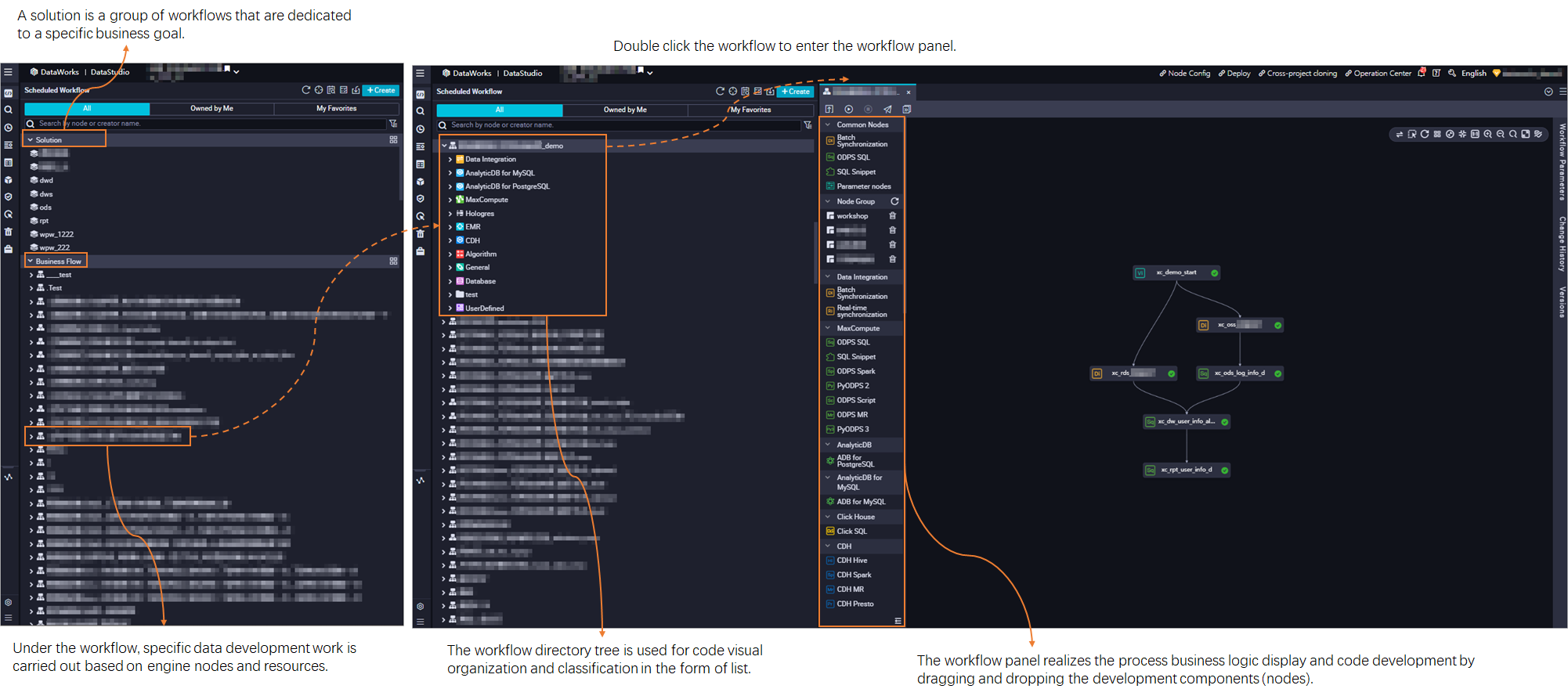
ワークフローは、コード開発とリソース管理の基本単位です。ワークフローは、ビジネス要件に基づいてコードを開発できる抽象的なビジネスエンティティです。異なるワークスペースのワークフローとノードは個別に開発されます。ワークフローの詳細については、「ワークフローの作成」をご参照ください。
ワークフローは、ディレクトリツリーまたはパネルに表示できます。表示モードを使用すると、ビジネスの観点からコードを整理し、リソースの分類とビジネスロジックをより効率的に表示できます。
ディレクトリツリーを使用すると、タスクタイプ別にコードを整理できます。
パネルには、ワークフローのビジネスロジックが表示されます。
DataStudio の使用を開始する
環境準備
データモデリング、DataStudio を使用したり、オペレーションセンターでタスクを定期的にスケジュールしたりするには、作成したデータソースまたはクラスターを DataStudio の計算リソースとして関連付けます。リソースが関連付けられた後でのみ、対応するデータソースまたはクラスターからデータにアクセスし、関連する操作を実行できます。そうしないと、DataStudio ノードを作成できなくなります。
開発およびスケジュールしたいタスクのタイプに基づいて、特定のタイプのデータソースまたはクラスターを追加します。
データソースまたはクラスターのタイプ
説明
MaxCompute データソースを初めて DataWorks に追加すると、DataWorks は自動的にデータソースを DataStudio に関連付けます。このトピックで説明されている手順に従ってデータソースを DataStudio に手動で関連付ける必要はありません。後で追加された MaxCompute データソースについては、データソースを DataStudio に手動で関連付ける必要があります。
これらのタイプのいずれかのデータソースを追加した後、このトピックで説明されている手順に従って、データソースを DataStudio に手動で関連付ける必要があります。
クラスターを DataWorks に登録すると、DataWorks はクラスターを DataStudio に関連付けます。このトピックで説明されている手順に従ってクラスターを DataStudio に手動で関連付ける必要はありません。
Cloudera's Distribution Including Apache Hadoop (CDH) または Cloudera Data Platform (CDP)
DataStudio ページに移動します。
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[データ開発へ] をクリックします。
左側のナビゲーションウィンドウで、[計算リソース] をクリックします。
[計算リソース] モジュールが左側のナビゲーションウィンドウに表示されない場合は、個人設定 タブに移動し、[DataStudio モジュール] セクションで [計算リソース] を選択して、[計算リソース] モジュールが DataStudio ページの左側のナビゲーションウィンドウに表示されるようにする必要があります。詳細については、「[DataStudio モジュール] セクションで設定を構成する」をご参照ください。
データソースまたはクラスターを関連付けます。
[計算リソース] ページで、[計算リソース名] または [計算リソースタイプ] で目的のデータソースまたはクラスターを検索し、[関連付け] をクリックします。データソースまたはクラスターを DataStudio に関連付けた後、接続情報に基づいてデータソースまたはクラスターからデータを読み取り、関連するデータ開発操作を実行できます。
説明データソースまたはクラスターの情報が変更されても、現在のページのデータが時間内に更新されない場合は、現在のページをリフレッシュしてキャッシュされたデータを更新してください。

次のようなシナリオでは、データソースまたはクラスターを DataStudio に関連付けることができない場合があります:
特定のタイプのデータソースまたはクラスターの構成が DataStudio との関連付けをサポートしていません。たとえば、AccessKey ペアを使用して追加されたデータソースを DataStudio に関連付けることはできません。関連付けの制限の詳細については、データソースまたはクラスターを DataStudio に関連付けるときに DataWorks コンソールに表示される説明をご参照ください。
開発環境または本番環境の構成がありません。
MaxCompute データソースを複数の DataWorks ワークスペースに同時に関連付けることはできません。
説明データソースまたはクラスターを DataStudio に関連付けられない理由は、データソースまたはクラスターのタイプによって異なります。データソースまたはクラスターを DataStudio に関連付けようとするときに表示される理由に基づいて問題をトラブルシューティングできます。
DataStudio に関連付けることができるのは、MaxCompute、EMR、Hologres、AnalyticDB for MySQL、ClickHouse、CDH、CDP、および AnalyticDB for PostgreSQL のタイプのデータソースまたはクラスターのみです。
DataStudio に関連付けることができるデータソースまたはクラスターのタイプと数は、DataWorks のエディションによって異なります。詳細については、「DataWorks エディションの機能」をご参照ください。
はじめに
DataStudio の使用を開始する を参照して、データ開発の基本操作とデータ開発プロセスを学ぶことができます。
DataStudio でサポートされているノードタイプ
DataWorks の DataStudio サービスでは、さまざまなタイプのノードを作成できます。DataWorks を有効にして、ノード用に生成されたインスタンスを定期的にスケジュールできます。また、ビジネス要件に基づいてデータを開発するために、特定のタイプのノードを選択することもできます。DataWorks でサポートされているノードタイプの詳細については、「サポートされているノードタイプ」をご参照ください。
付録: データ開発関連の用語
タスク開発関連の用語
用語
説明
ソリューション
ワークフローのコレクション。ソリューションは、特定のビジネス目標に特化したワークフローのグループです。ワークフローは複数のソリューションに追加できます。ソリューションを開発し、ワークフローをソリューションに追加すると、他のユーザーは共同開発のためにソリューション内のワークフローを参照および変更できます。
ワークフロー
特定のビジネス要件のためのタスク、テーブル、リソース、および関数のコレクションである抽象的なビジネスエンティティ。このタイプのワークフローのタスクは、スケジュールどおりに実行されるようにトリガーされます。
手動トリガーワークフロー
特定のビジネス要件のためのタスク、テーブル、リソース、および関数のコレクション。
このタイプのワークフローのタスクは、手動でトリガーされて実行されます。
DAG
有向非循環グラフの略語。DAG は、ノードとその依存関係を表示するために使用されます。DataStudio では、ワークフロー内のすべてのタスクが同じ DAG に表示されます。これにより、タスク開発と依存関係の設定が容易になります。タスク
DataWorks の基本的な実行単位。DataWorks は、タスク間の依存関係に基づいてタスクを順番に実行します。
ノード
DAG 内のタスク。DataWorks は、ノード間の依存関係に基づいてノードを順番に実行します。
タスクスケジューリング関連の用語
用語
説明
依存関係
タスクが実行される順序を定義するために使用されます。ノード B がノード A の実行完了後にのみ実行できる場合、ノード A はノード B の先祖ノードであり、ノード B はノード A に依存します。DAG では、依存関係はノード間の矢印で表されます。
出力名
現在のノードを他のノードと区別するために使用される識別子。出力名はグローバルに一意です。ノードには複数の出力名を含めることができます。ノード間のスケジューリング依存関係は、出力名に基づいて設定されます。
出力テーブル名
現在のタスクによって生成されたテーブルの名前を出力テーブル名として使用することをお勧めします。出力テーブル名を適切に設定すると、子孫ノードの依存関係を設定するときに、データが期待される先祖テーブルからのものであるかどうかを確認するのに役立ちます。自動解析に基づいて生成された出力テーブル名を手動で変更しないことをお勧めします。出力テーブル名は識別子としてのみ機能します。出力テーブル名を変更しても、SQL 文を実行して実際に生成されるテーブルの名前には影響しません。実際に生成されるテーブルの名前は、SQL ロジックに従います。
説明[出力名] はグローバルに一意である必要があります。ただし、[出力テーブル名] にはそのような制限はありません。
スケジューリング用のリソースグループ
タスクスケジューリングに使用されるリソースグループ。リソースグループの詳細については、「概要」をご参照ください。
スケジューリングパラメーター
ノードが実行されるようにスケジュールされたときに、ノードに対して設定されます。スケジューリングパラメーターの値は、ノードのスケジューリング時に動的に置き換えられます。コードの繰り返し実行中に、日付や時刻などのランタイム環境に関する情報を取得したい場合は、DataWorks のスケジューリングパラメーターの定義に基づいて、コード内の変数に動的に値を割り当てることができます。
データタイムスタンプ
スケジューリング時間 (ノードをスケジュールしたい時間) の前日。オフラインコンピューティングのシナリオでは、データタイムスタンプはビジネストランザクションが行われた日付を表します。データタイムスタンプの値は日まで正確です。たとえば、当日に前日の売上高に関する統計データを収集する場合、前日はビジネストランザクションが行われた日付であり、データタイムスタンプを表します。
スケジューリング時間
ビジネスデータを処理するためにタスクをスケジュールしたい時間。スケジューリング時間は秒まで正確です。スケジューリング時間は、タスクが実際に実行されるようにスケジュールされた時間とは異なる場合があります。タスクが実行される実際の時間は、複数の要因に影響されます。