Java アプリケーションに ARMS プローブをインストールすると、ARMS が自動的にアプリケーションを監視します。[インスタンス監視] ページで、インフラ監視、ガベージコレクション (GC)、および JVM メモリのメトリックを表示できます。
前提条件
アプリケーションに ARMS エージェントがインストールされていること。
アプリケーションモニタリングは、新しい課金モードを有効にしたユーザー向けに、新しいアプリケーション詳細ページを提供します。
新しい課金モードを有効にしていない場合は、[アプリケーションリスト] ページで [新バージョンに切り替え] をクリックして、新しいアプリケーション詳細ページを表示します。
インスタンス監視の表示
-
ARMS コンソールにログインします。左側のナビゲーションウィンドウで、 を選択します。
上部のナビゲーションバーで、[インスタンス監視] をクリックします。
ページの概要
「[インスタンス監視]」ページのダッシュボードは、アプリケーションの統合方法に応じて調整され、ECS 環境およびコンテナ環境向けに異なるビューを表示します。
アプリケーションがコンテナ環境で実行され、Managed Service for Prometheus と統合されている場合、ページには主に Managed Service for Prometheus からのコンテナメトリックが表示されます。コンテナ環境を Managed Service for Prometheus と統合する方法については、「コンテナ可観測性」をご参照ください。
コンテナ環境が Managed Service for Prometheus と統合されていない場合は、アプリケーションモニタリングのプローブバージョンが 4.1.0 以降であることを確認する必要があります。これは、基本的なコンテナメトリックを表示するために必要です。プローブバージョンの詳細については、「プローブ (Java エージェント) バージョンガイド」をご参照ください。
ECS 環境
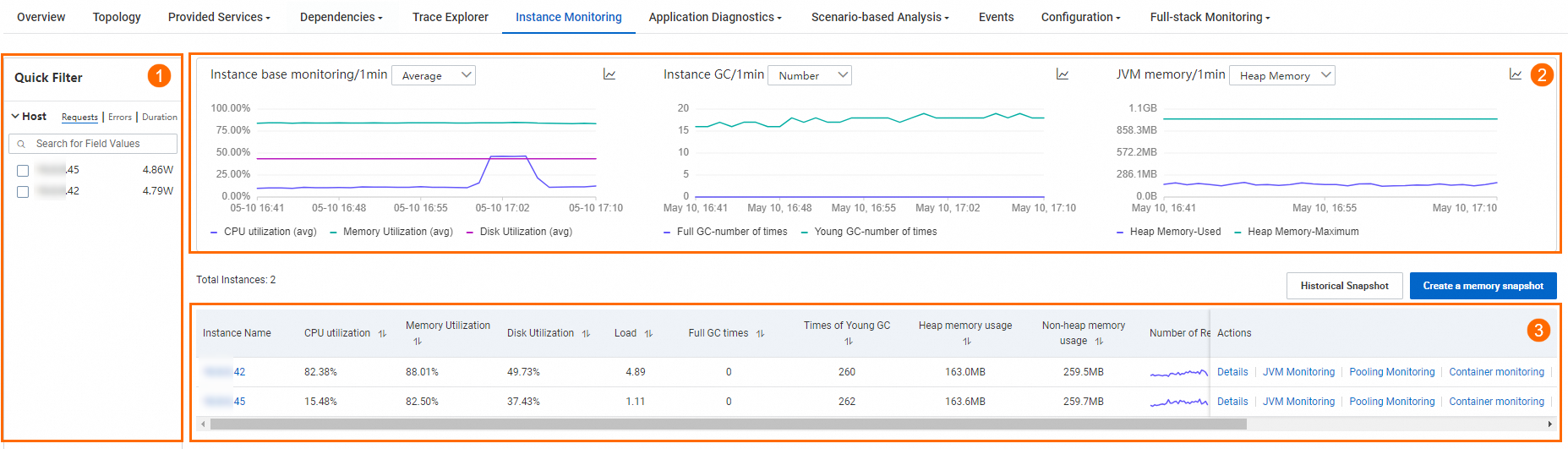
クイックフィルターエリア (①) では、ホストアドレスでチャートとインスタンスリストをフィルターできます。
トレンドチャートエリア (②) では、インフラ監視、GC、JVM メモリのメトリックの時系列曲線を表示できます。
インフラ監視:指定した時間範囲における CPU、メモリ、ディスク使用量のトレンドを表示します。各チャートタイトルの横にあるドロップダウンリストを使用して、平均値と最大値を切り替えることができます。
インスタンス GC:指定した時間範囲におけるフル GC と Young GC のトレンドを表示します。各チャートタイトルの横にあるドロップダウンリストを使用して、GC 回数と平均 GC 時間を切り替えることができます。
JVM メモリ:指定した時間範囲における使用済みヒープメモリと最大ヒープメモリのトレンドを表示します。各チャートタイトルの横にあるドロップダウンリストを使用して、使用済み非ヒープメモリと最大非ヒープメモリのトレンドに切り替えることができます。
説明ARMS アプリケーションモニタリングは JMX を介して JVM メトリックを収集します。ARMS によって報告される非ヒープメモリ領域は、実際の Java プロセスよりも少なくなります。その結果、ARMS に表示されるヒープメモリと非ヒープメモリの合計は、
topコマンドで表示される RES サイズと異なる場合があります。詳細については、「JVM 監視のメモリ詳細」をご参照ください。
 アイコンをクリックするとダイアログボックスが開き、時間範囲内のメトリックの統計情報を表示したり、同じ時間範囲で異なる日付の統計情報を比較したりできます。また、
アイコンをクリックするとダイアログボックスが開き、時間範囲内のメトリックの統計情報を表示したり、同じ時間範囲で異なる日付の統計情報を比較したりできます。また、 アイコンをクリックして、縦棒グラフとトレンドチャートを切り替えることもできます。
アイコンをクリックして、縦棒グラフとトレンドチャートを切り替えることもできます。インスタンスリストエリア (③) では、インスタンス IP、CPU 使用率、メモリ使用率、ディスク使用率、ロード、フル GC 回数、Young GC 回数、ヒープメモリ使用量、非ヒープメモリ使用量、および RED メトリック (リクエスト、エラー、平均応答時間) を表示できます。
インスタンスリストでは、次の操作を実行できます:
コンテナ環境 (Prometheus)
クイックフィルターエリア (①) では、クラスターとホストアドレスでチャートとインスタンスリストをフィルターできます。
トレンドチャートエリア (②) では、インフラ監視、GC、JVM メモリのメトリックの時系列曲線を表示できます。
インフラ監視:指定した時間範囲における CPU とメモリ使用量のトレンドを表示します。
インスタンス GC:指定した時間範囲におけるフル GC と Young GC のトレンドを表示します。各チャートタイトルの横にあるドロップダウンリストを使用して、GC 回数と平均 GC 時間を切り替えることができます。
JVM メモリ:指定した時間範囲における使用済みヒープメモリと最大ヒープメモリのトレンドを表示します。各チャートタイトルの横にあるドロップダウンリストを使用して、使用済み非ヒープメモリと最大非ヒープメモリのトレンドに切り替えることができます。
説明ARMS アプリケーションモニタリングは JMX を介して JVM メトリックを収集します。ARMS によって報告される非ヒープメモリ領域は、実際の Java プロセスよりも少なくなります。その結果、ARMS に表示されるヒープメモリと非ヒープメモリの合計は、
topコマンドで表示される RES サイズと異なる場合があります。詳細については、「JVM 監視のメモリ詳細」をご参照ください。
アイコンをクリックするとダイアログボックスが開き、時間範囲内のメトリックの統計情報を表示したり、同じ時間範囲で異なる日付の統計情報を比較したりできます。また、 アイコンをクリックして、縦棒グラフとトレンドチャートを切り替えることもできます。インスタンスリストエリア (③) では、インスタンス IP、CPU 使用量、CPU リクエスト、CPU 制限、CPU 使用率 (CPU 制限が設定されていない場合は - と表示)、メモリ使用量、メモリリクエスト、メモリ制限、メモリ使用率 (メモリ制限が設定されていない場合は - と表示)、ディスク使用率、ディスク制限、ディスク使用率 (ディスク制限が設定されていない場合は - と表示)、ロード、フル GC 回数、Young GC 回数、ヒープメモリ使用量、非ヒープメモリ使用量、および RED メトリック (リクエスト、エラー、平均応答時間) を表示できます。
インスタンスリストでは、次の操作を実行できます:
コンテナ環境 (ARMS 自己収集)
クイックフィルターエリア (①) では、ホストアドレスでチャートとインスタンスリストをフィルターできます。
トレンドチャートエリア (②) では、インフラ監視、GC、JVM メモリのメトリックの時系列曲線を表示できます。
インフラ監視:指定した時間範囲における CPU とメモリ使用量のトレンドを表示します。
インスタンス GC:指定した時間範囲におけるフル GC と Young GC のトレンドを表示します。各チャートタイトルの横にあるドロップダウンリストを使用して、GC 回数と平均 GC 時間を切り替えることができます。
JVM メモリ:指定した時間範囲における使用済みヒープメモリと最大ヒープメモリのトレンドを表示します。各チャートタイトルの横にあるドロップダウンリストを使用して、使用済み非ヒープメモリと最大非ヒープメモリのトレンドに切り替えることができます。
説明ARMS アプリケーションモニタリングは JMX を介して JVM メトリックを収集します。ARMS によって報告される非ヒープメモリ領域は、実際の Java プロセスよりも少なくなります。その結果、ARMS に表示されるヒープメモリと非ヒープメモリの合計は、
topコマンドで表示される RES サイズと異なる場合があります。詳細については、「JVM 監視のメモリ詳細」をご参照ください。
アイコンをクリックするとダイアログボックスが開き、時間範囲内のメトリックの統計情報を表示したり、同じ時間範囲で異なる日付の統計情報を比較したりできます。また、 アイコンをクリックして、縦棒グラフとトレンドチャートを切り替えることもできます。インスタンスリストエリア (③) では、インスタンス IP、CPU 使用量、メモリ使用量、ロード、フル GC 回数、Young GC 回数、ヒープメモリ使用量、非ヒープメモリ使用量、および RED メトリック (リクエスト、エラー、平均応答時間) を表示できます。
インスタンスリストでは、次の操作を実行できます:
インスタンス詳細
概要
[概要] タブには、選択したインターフェイスのリクエスト数、エラー数、平均応答時間、低速呼び出し情報が表示されます。
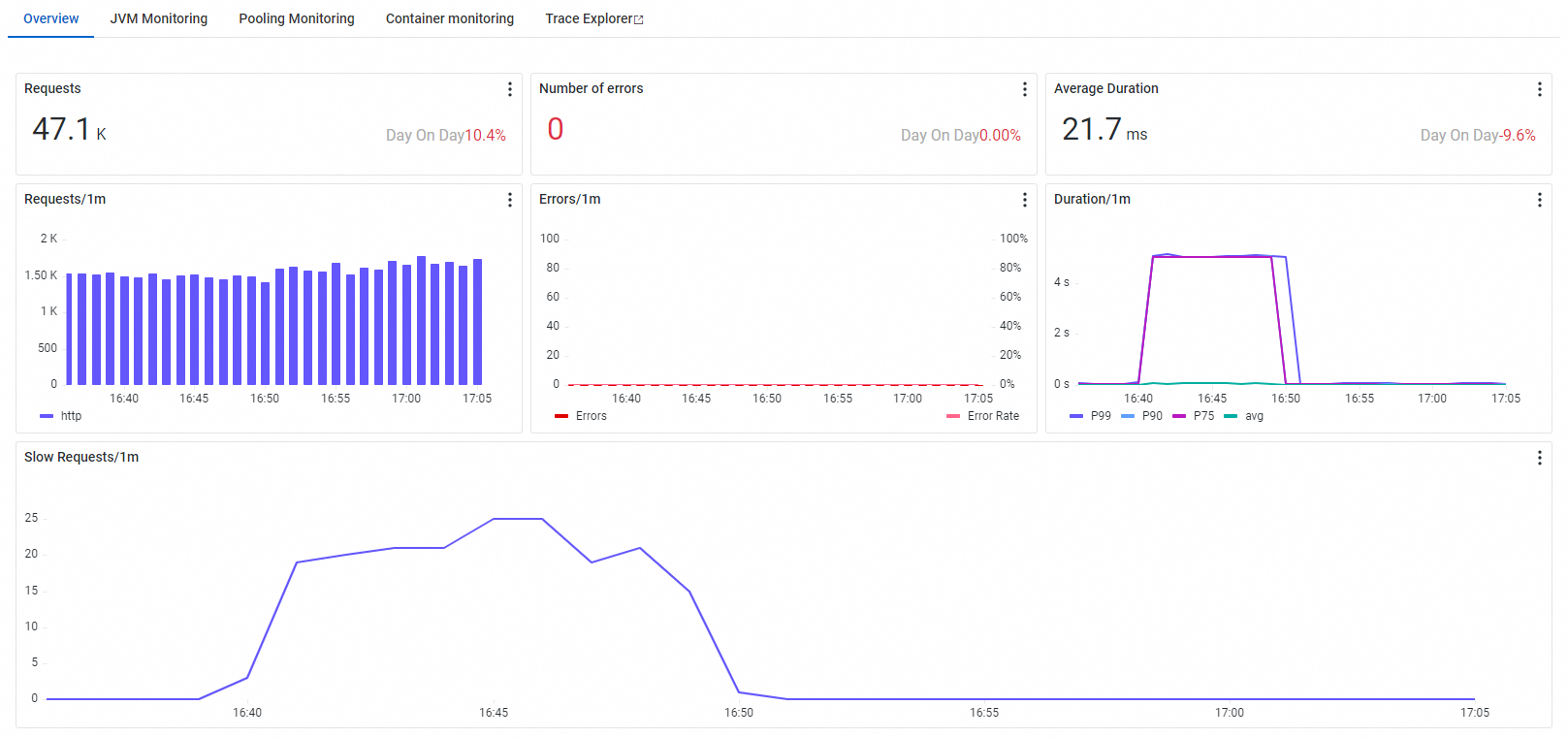
JVM 監視
[JVM 監視] タブには、選択したインスタンスの GC、メモリ、スレッド、ファイルメトリックが表示されます。

スレッドプール監視
プローブバージョン 4.1.x 以降
[スレッドプール監視] タブには、アプリケーションで使用されるスレッドプールのメトリックが表示されます。これには、コアスレッド構成、アクティブスレッドステータス、タスク実行ステータスが含まれます。
タブの上部で、タイプと名前でスレッドプールをフィルターできます。

4.1.x より前のプローブバージョン
[スレッドプール監視] タブには、アプリケーションで使用されるスレッドプールのコアスレッド数、現在のスレッド数、最大スレッド数、アクティブスレッド数、およびタスクキュー容量が表示されます。

接続プール監視
プローブバージョン 4.1.x 以降
[接続プール監視] タブには、アプリケーションで使用される接続プールのメトリックが表示されます。これには、初期設定とランタイムステータスが含まれます。
タブの上部で、タイプで接続プールをフィルターできます。

4.1.x より前のプローブバージョン
[接続プール監視] タブには、アプリケーションで使用される接続プールの最大接続数とアクティブ接続数が表示されます。

ホスト監視
[ホスト監視] タブには、CPU、メモリ、ディスク、ロード、ネットワークトラフィック、およびネットワークパケットのメトリックが表示されます。

コンテナ監視
コンテナ環境 (Prometheus)
Managed Service for Prometheus と統合するには、「Container Service 向け Prometheus インスタンス」をご参照ください。
[コンテナ監視] タブには、コンテナの観点から CPU、メモリ、ディスク、ロード、ネットワークトラフィック、およびネットワークパケットのメトリックが表示されます。
コンテナ環境 (ARMS 自己収集)
Managed Service for Prometheus と統合していない場合は、ARMS プローブのバージョンが 4.1.0 以降であることを確認してください。プローブバージョンの詳細については、「プローブ (Java エージェント) バージョンガイド」をご参照ください。
[コンテナ監視] タブには、コンテナの観点から CPU、メモリ、ネットワークトラフィックの時系列曲線が表示されます。

トレース分析
トレース分析では、保存されたトレースデータを使用してリアルタイム分析を実行します。フィルターと集約ディメンションを組み合わせて、さまざまなシナリオのカスタム診断ニーズに対応できます。詳細については、「トレース分析」をご参照ください。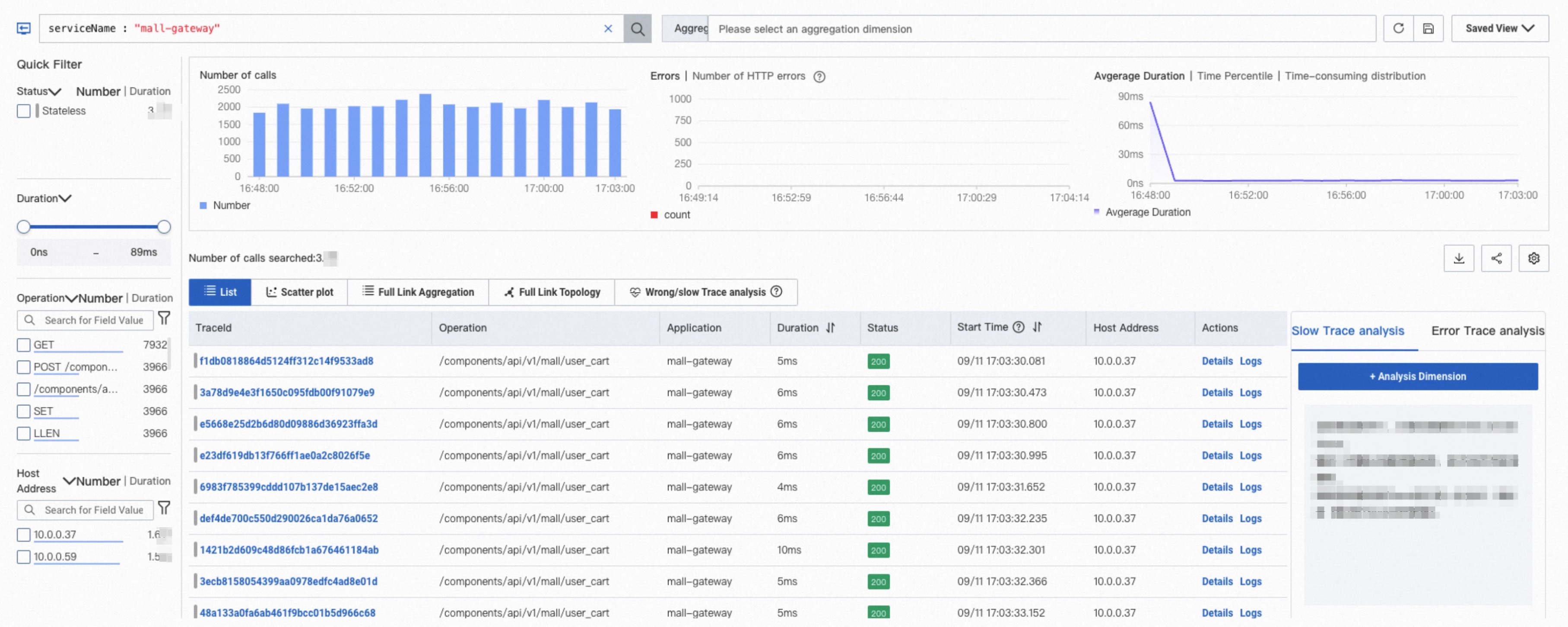
参照情報
アプリケーションモニタリングのメトリックの詳細については、「アプリケーションモニタリングのメトリックリファレンス」をご参照ください。
よくある質問
アプリケーションレベルのデータと単一マシンデータの関係
RED メトリック (リクエスト、エラー、レイテンシー):
リクエスト数、低速呼び出し数、HTTP ステータスコード数:アプリケーションレベルのメトリックは、インスタンスごとのメトリックの合計です。
応答時間:アプリケーションレベルのメトリックは、インスタンスごとのメトリックの平均です。
JVM メトリック:
GC 回数と GC 時間:アプリケーションレベルのメトリックは、インスタンスごとのメトリックの合計です。
ヒープメモリとスレッド数:アプリケーションレベルのメトリックは、すべてのインスタンスごとのメトリックの中の最大値です。
スレッドプールと接続プールのメトリック
すべてのメトリック:アプリケーションレベルのメトリックは、インスタンスごとのメトリックの平均です。
システムメトリック
すべてのメトリック:アプリケーションレベルのメトリックは、すべてのインスタンスごとのメトリックの中の最大値です。
SQL および NoSQL 呼び出し:RED メトリックと同様に、アプリケーションレベルのカウントはインスタンスごとのカウントの合計であり、その他のメトリックはインスタンスごとのメトリックの平均です。
例外メトリック:アプリケーションレベルのメトリックは、インスタンスごとのメトリックの合計です。
インスタンス間でトラフィックが不均一
プローブバージョン 3.x では、メモリ最適化を有効にすると、一部のメトリックが欠落する場合があります。この問題はプローブバージョン 4.x で解決されています。
単一の Undertow リクエストが 2 回カウントされる
3.2.x より前のプローブバージョンでは、DeferredResult のイベントトラッキングにより、1 回の呼び出しが 2 回実行されます。この問題はプローブバージョン 3.2.x 以降で解決されています。
コンテナ監視の CPU またはメモリのクォータが Pod 設定と一致しない
Pod が複数のコンテナを定義しているかどうかを確認してください。このメトリックは、Pod 内のすべてのコンテナのクォータの合計です。
一部のシステムメトリックが欠落、不正確、または CPU 使用率が 100% と表示される
4.x より前のプローブバージョンは、Windows 上でシステムメトリックを収集しません。この問題はプローブバージョン 4.x 以降で解決されています。
アプリケーション起動直後にフル GC が発生するのはなぜですか?
これは通常、メタスペースサイズが構成されていないために発生します。デフォルトのメタスペースサイズは約 20 MB です。起動中に、アプリケーションがメタスペースを拡張し、それがフル GC をトリガーする可能性があります。-XX:MetaspaceSize および -XX:MaxMetaspaceSize パラメーターを使用して、初期および最大のメタスペースサイズを設定できます。
VM スタックはどのように計算されますか?
このメトリックは、ライブスレッド数に 1 MB を乗じて計算されます。デフォルトのスレッドスタックサイズは 1 MB です。-Xss パラメーターを使用して異なるスタックサイズを指定した場合、このメトリックは実際の値と異なる場合があります。
state=live には、live、blocked、new、runnable、timed-wait、wait の状態が含まれます。
JVM メトリックはどのように収集されますか?
ARMS は、標準の JDK インターフェイスを使用して JVM メトリックを取得します:
メモリ関連のメトリック:
ManagementFactory.getMemoryPoolMXBeans
java.lang.management.MemoryPoolMXBean#getUsage
GC 関連のメトリック:
4.4.0 より前のプローブバージョン
ManagementFactory.getGarbageCollectorMXBeans
java.lang.management.GarbageCollectorMXBean#getCollectionCount
java.lang.management.GarbageCollectorMXBean#getCollectionTime
プローブバージョン 4.4.0 以降
これは、GarbageCollectionNotificationInfo イベントをサブスクライブすることで GarbageCollectorMXBean から取得できます。
JVM の最大ヒープメモリ値が -1 になるのはなぜですか?
-1 という値は、最大ヒープメモリサイズが設定されていないことを示します。
JVM のヒープメモリ使用量が最大ヒープメモリサイズと等しくならないのはなぜですか?
JVM のメモリ割り当てルールによると、-Xms パラメーターは初期ヒープサイズを設定します。ヒープは、空き領域が不十分な場合に、-Xmx で設定された最大サイズまで拡張されます。不一致は、拡張がまだ発生していないことを示します。使用量の値は、現在の実際の使用量を反映しています。
JVM GC の頻度が徐々に増加する
これは、JDK 8 のデフォルト GC アルゴリズムである ParallelGC を使用している場合に発生する可能性があります。ParallelGC は、デフォルトで -XX:+UseAdaptiveSizePolicy を有効にします。この設定は、GC の一時停止目標を達成するために、Young 領域サイズや SurvivorRatio を含むヒープサイズを動的に調整します。Young GC が頻繁に発生すると、Survivor 領域が縮小する可能性があります。その後、オブジェクトは Old 領域に迅速に昇格され、より速い成長とより頻繁なフル GC を引き起こします。詳細については、Java ドキュメントをご参照ください。
スレッドプールまたは接続プール監視にデータが表示されない
[カスタム設定] ページの [詳細設定] で、スレッドプールと接続プールの監視が有効になっていることを確認します。
ご利用のフレームワークがサポートされていることを確認してください。詳細については、「スレッドプールと接続プールの監視」をご参照ください。
HikariCP の最大接続数が期待値と一致しない
3.2.x より前のプローブバージョンでは、最大接続数を誤って取得します。この問題はプローブバージョン 3.2.x 以降で解決されています。
プーリング監視メトリックが 10 進数値で表示される
プローブは 15 秒ごとにデータを収集します。コンソールには、時間範囲内の平均値が表示されます。たとえば、1 分間に収集された 4 つのデータポイントが 0、0、1、0 の場合、平均は 0.25 になります。
スレッドプールまたは接続プールが満杯なのに、監視に変化が表示されない
ログやその他のレコードでスレッドプールまたは接続プールが満杯であることが確認されても、ARMS に対応するメトリックの増加が表示されない場合、サンプリング時間がピークと一致していない可能性があります。ARMS はスレッドプールと接続プールのメトリックを 15 秒ごとに収集します。この間隔内の短時間のスパイクはキャプチャされない場合があります。
スレッドプールの最大スレッド数が予期しない値、または 21 億と表示される
ARMS は、スレッドプールオブジェクトから最大スレッド数を直接取得します。これが失敗することはほとんどありません。予期しない値は、構成した最大値が適用されなかったことを意味する可能性があります。
21 億という値は、通常、スケジュールされたスレッドプールを示します。スケジュールされたスレッドプールは、以下に示すように、デフォルトで Integer.MAX_VALUE になります。

Tomcat スレッドプールのメトリックが期待値と一致しない
ARMS は、スレッドプールオブジェクトからスレッドプールのメトリックを直接取得します。これが失敗することはほとんどありません。最大スレッド数、アクティブスレッド数、コアスレッド数など、複数のメトリックがすべて異なる場合は、アプリケーションが複数のポートで Tomcat サービスを公開しているかどうかを確認してください。たとえば、Spring Actuator はメトリックを公開するために追加のポートを開きます。このような場合、ARMS はディメンションの収束により、複数のスレッドプールからのメトリックをマージする可能性があります。この問題を解決するには、プローブバージョンを 4.1.10 以降にアップグレードしてください。次に、 ページの [プーリング監視設定] セクションで、[スレッドプールのスレッド名パターンの抽出戦略] を 末尾の数字を * に置き換える に設定します。
特定の時間より前にスレッドプールまたは接続プールのデータがない
これは、アプリケーションが定期タスクをトリガーした場合に発生する可能性があります。スレッドプールまたは接続プールのデータは、タスクが初期化された後にのみ表示されます。API エンドポイントのリクエスト数など、トラフィックベースのメトリックも同様の動作をすることがよくあります。
HttpClient 接続プールのデータがない
ARMS プローブバージョン 4.x 以降、ARMS は OkHttp3 および Apache HttpClient の接続プール監視をサポートしなくなりました。これは、これらのフレームワークが外部ドメインごとに個別の接続プールを作成するためです。ドメインが多い場合、全体的なオーバーヘッドと安定性のリスクが増加します。これらの理由により、ARMS はそれらをサポートしなくなりました。
ACK アプリケーションを統合した後、コンテナ監視データが表示されない
これは、ACK クラスターの作成に使用した Alibaba Cloud アカウントが、ARMS との統合に使用したアカウントと異なる場合に発生する可能性があります。ARMS は、同じ Alibaba Cloud アカウント配下のリソースに対してのみコンテナ監視データを表示します。
ファイルハンドルのオープン率がゼロではないが、ファイルハンドル数がゼロ
ご利用のアプリケーションが JDK 9 以降で実行され、ARMS プローブバージョン 3.x を使用しているかどうかを確認してください。その場合、この環境ではメトリック収集ロジックに互換性の問題があります。この問題はプローブバージョン 4.2.2 以降で解決されています。最新バージョンにプローブをアップグレードできます。
JVM プロセスの物理メモリ使用量が JVM 監視のヒープメモリ使用量と大幅に異なる
これは通常、JVM プロセスが大量のオフヒープメモリを使用するために発生します。ARMS はヒープメモリと一部のオフヒープメモリのみを監視します。ARMS が監視できる JVM メモリの部分の詳細については、「JVM 監視のメモリ詳細」をご参照ください。オフヒープメモリの使用量が多い場合は、そのドキュメントのオフヒープメモリリーク分析セクションをご参照ください。
Druid が最大アイドル接続設定よりも多くのアイドル接続を表示するのはなぜですか?
MaxIdle は、ユーザーが DBCP から移行するのを助けるためにのみ存在します。効果はありません。
一部のインスタンスを最新のプローブバージョンにアップグレードしたが、データが表示されない
4.1.x より前のプローブバージョンからアップグレードした場合、すべてのインスタンスを最新バージョンにアップグレードする必要があります。その後、ページは自動的に適応し、データを表示します。