PolarDB is a next-generation cloud-native database developed by Alibaba Cloud. It uses a storage-compute decoupled architecture and combines software and hardware to provide a database service that features scalability in seconds, high performance, mass storage, and security. PolarDB for PostgreSQL Enterprise Edition is 100% compatible with multiple native PostgreSQL versions, including PostgreSQL 11, 14, 15, 16, and 17. Based on a cloud-native design, it combines the stability, reliability, high performance, and scalability of commercial databases with the simplicity, openness, and rapid iteration of open source databases.
What is PolarDB for PostgreSQL Enterprise Edition?
PolarDB for PostgreSQL Enterprise Edition uses a storage-compute decoupled architecture where all compute nodes share a single copy of data. The service provides configuration scaling in minutes, fault recovery in seconds, global data consistency, and free data backup and disaster recovery services.
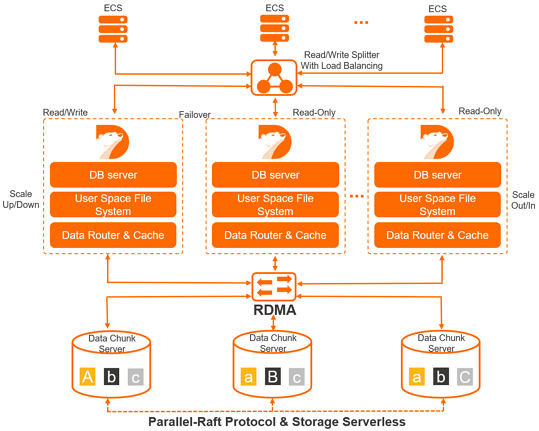
The service architecture of PolarDB for PostgreSQL Enterprise Edition has the following features:
One primary node and multiple read-only nodes
PolarDB uses a multi-node cluster architecture that includes one primary node and up to 15 read-only nodes. The primary node processes read and write requests, while the read-only nodes process only read requests. The primary and read-only nodes use active-active failover to provide high database availability.
Read/write splitting is a transparent, highly available, and adaptive load balancing capability that PolarDB provides by default at no extra cost. A cluster endpoint automatically forwards SQL requests to the nodes of a PolarDB cluster. This provides aggregated, high-throughput, and concurrent SQL processing.
Compute-storage decoupled
PolarDB uses a compute-storage decoupled design to meet the high demand for elastic cluster scaling that is driven by business growth in public cloud environments.
The compute nodes (Database Engine Servers) of a cluster store only metadata. Data files and redo logs are stored on remote storage nodes (Database Storage Servers). The compute nodes only need to synchronize redo log-related metadata. This design greatly reduces the replication delay between the primary node and read-only nodes. If the primary node fails, a read-only node can be quickly promoted to the new primary node.
High-speed interconnection
The compute nodes and storage nodes of a cluster are interconnected over a high-speed network. Data is transmitted over a Remote Direct Memory Access (RDMA) network. This ensures that I/O performance is no longer a bottleneck.
Shared distributed storage
Multiple compute nodes share a single copy of data instead of each compute node storing its own copy. This design greatly reduces storage costs. Based on a new distributed block storage and distributed file system, the storage capacity can be smoothly scaled out online. The storage capacity is not limited by a single database server and can handle hundreds of terabytes of data.
Multiple data replicas and Parallel-RAFT protocol
Data on storage nodes is stored in multiple replicas to ensure data reliability. The Parallel-RAFT protocol is used to ensure data consistency.
Why choose PolarDB for PostgreSQL Enterprise Edition?
Easy to use
PolarDB for PostgreSQL Enterprise Edition is fully compatible with PostgreSQL. Your code and applications require little to no modification.
Lower costs
Compute and storage separation: Multiple compute nodes share storage. When you add a read-only node, you pay only for the compute node. This greatly reduces scale-out costs.
Serverless storage: You do not need to manually configure storage space. Storage automatically scales based on your data volume. You pay only for the storage capacity that you use.
Exceptional performance
Performance is greatly improved by a deeply optimized database kernel, physical replication, a high-speed RDMA network, and distributed shared storage.
A cluster includes one primary node and up to 15 read-only nodes. This meets the performance requirements of high-concurrency scenarios and is especially suitable for read-intensive workloads.
In a cluster that has one primary node, multiple read-only nodes, and shared storage, data needs to be modified only once for the changes to be applied to all nodes.
Online Transactional Processing (OLTP) performance is greatly improved. The service supports more than 500,000 read requests per second and more than 150,000 write requests per second.
Mass storage for hundreds of terabytes of data
The distributed block storage design and file system allow storage capacity to be easily scaled out without being limited by the specifications of a single node. A single cluster supports up to 500 TB of storage space by default.
PolarStore (PSL4/PSL5) supports petabyte-level storage. If you have this requirement, please contact us to reserve the resources.
High availability, reliability, and data security
The shared distributed storage design prevents data inconsistencies on replicas that can be caused by asynchronous replication from the primary node. This ensures zero data loss in the event of a single point of failure in the database cluster.
The multi-zone architecture provides disaster recovery and backup for the database by replicating data across multiple zones.
The cluster endpoint uses a Log Sequence Number (LSN) to ensure global consistency when data is read. This avoids inconsistencies caused by replication delay between the primary and read-only nodes.
Redo-based physical replication is used instead of binary logging-based logical replication to improve the efficiency and stability of primary-replica replication. Even Data Definition Language (DDL) operations, such as adding an index or a field to a large table, do not cause replication delays.
Comprehensive security measures, such as whitelists, VPC networks, and multi-replica data storage, provide security for all aspects of database access, storage, and management.
Rapid elasticity for business growth
You can scale a configuration up or down in 5 minutes.
Container virtualization and shared distributed block storage technologies allow you to rapidly scale the CPU and memory of a database server.
You can add or remove nodes in 5 minutes.
You can dynamically add or remove nodes to improve performance or save costs. The cluster endpoint masks underlying changes, which makes applications unaware of node additions or removals.
Lock-free backup
The snapshot technology of the underlying distributed storage lets you back up a database with terabytes of data in minutes. The entire backup process does not require locks, resulting in higher efficiency and less impact on performance.
How to use PolarDB for PostgreSQL Enterprise Edition
You can use the following methods to manage your PolarDB for PostgreSQL Enterprise Edition cluster. You can create the cluster, databases, and accounts.
Console: provides a graphical web interface for easy operation.
Command-line interface (CLI): lets you perform all operations that are available in the console.
SDK: You can perform all operations that are available in the console.
API: All console operations are also available through the API.
After you create a PolarDB for PostgreSQL Enterprise Edition cluster, you can connect to the cluster using one of the following methods:
DMS: You can connect to a PolarDB cluster using DMS to perform database development on the web interface.
Client: You can use a general-purpose database client tool, such as pgAdmin, to connect to your PolarDB cluster.