PolarDB is based on the cloud native architecture. PolarDB provides the benefits of commercial databases and open source cloud databases. Commercial databases offer the benefits of stability, reliability, high performance, and scalability. Open source cloud databases offer the benefits of simplicity, openness, and rapid iteration. This topic describes the architecture and features of PolarDB.
One primary node and multiple read-only nodes
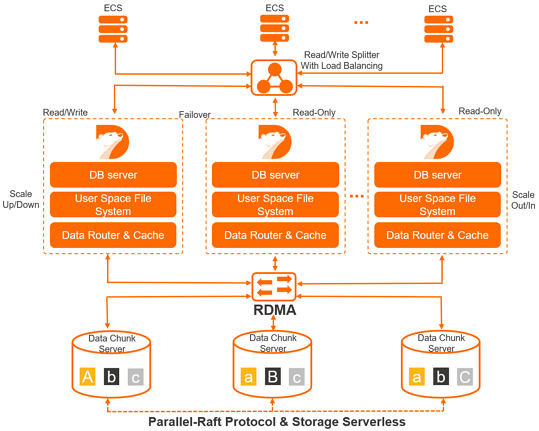
PolarDB uses a distributed cluster-based architecture. A Cluster cluster consists of a primary node and a maximum of 15 read-only nodes. At least one read-only node is used to ensure high availability. The primary node processes read and write requests, and the read-only nodes process only read requests. PolarDB uses the active-active failover method between the primary node and read-only nodes. This method provides the high availability service of databases.
Compute and storage decoupling
PolarDB decouples compute from storage. This allows you to scale clusters that are deployed on Alibaba Cloud based on your business requirements. The database compute nodes (database engine servers) store only metadata. The remote storage nodes (database storage servers) store data, such as data files and redo logs. You need only to synchronize the metadata that is related to redo logs among your compute nodes. This reduces the replication delay between the primary node and read-only nodes. If the primary node fails, a read-only node can take over within a short period of time.
Read/write splitting
By default, read/write splitting is a transparent, high availability, and adaptive load balancing capability that is provided for PolarDB Cluster. The read/write splitting feature automatically forwards Structured Query Language (SQL) requests to each node of PolarDB Cluster based on cluster endpoints. This allows you to process concurrent SQL statements in aggregation and high-throughput scenarios. For more information, see Read/write splitting.
High-speed network connections
High-speed network connections are used between compute nodes and storage nodes of databases. The Remote Direct Memory Access (RDMA) protocol is used to transmit data between compute nodes and storage nodes. These two features eliminate the bottlenecks of I/O performance.
Shared distributed storage
Multiple compute nodes share one set of data. Each compute node does not need to store the same set of data. This significantly reduces your storage costs. The storage capacity can be smoothly scaled online by using the newly developed distributed storage and distributed file system. This feature is not limited by the storage capacity of a single database server and can cope with hundreds of terabytes of data.
Multiple data replicas and the Parallel-Raft protocol
The data on storage nodes of databases has multiple replicas. This ensures data reliability. In addition, the Parallel-Raft protocol is used to ensure data consistency among these replicas.