PolarDB for PostgreSQL provides the multi-node elastic parallel query (ePQ) feature to solve issues that PolarDB for PostgreSQL encountered in handling complex analytical queries.
Prerequisites
Your PolarDB for PostgreSQL cluster runs the following engine:
PostgreSQL 11 (revision version 1.1.28 or later)
You can execute the following statement to query the revision version of your PolarDB for PostgreSQL cluster:
show polar_version;Background information
You may have both transactional and analytical queries when using PolarDB for PostgreSQL. You may expect the databases to process highly concurrent transactional requests during work day hours and perform analytical tasks to generate reports at night when transactional traffic decreases and workloads are low. This still does not maximize the utilization of idle resources. PolarDB for PostgreSQL encounters two major challenges when processing complex analytical queries:
On native PostgreSQL, a SQL statement can only be executed on a single node. No matter in the serial or parallel execution mode, computing resources of other nodes, such as CPU and memory resources, cannot be used for the execution. To speed up a single query, you can perform only a scale-up but not a scale-out.
PolarDB for PostgreSQL is built on top of a storage pool that theoretically delivers unlimited I/O throughput. On native PostgreSQL, however, a SQL statement can only be executed on a single node. Due to the limits on the CPU and memory of a single node, the I/O throughput of the storage cannot be fully utilized.
The following figure shows the challenges of native PostgreSQL.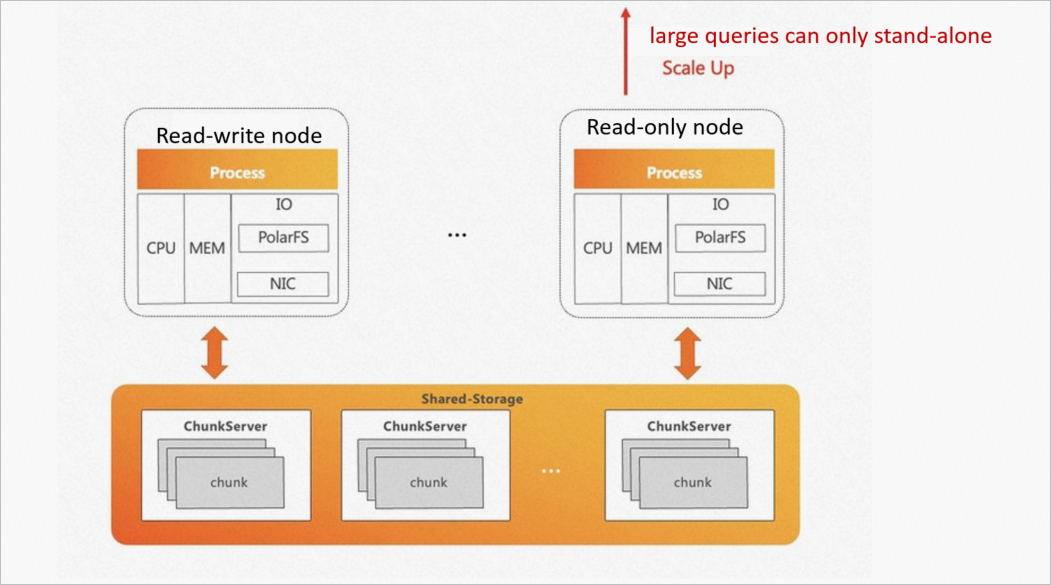
To overcome these challenges, PolarDB for PostgreSQL provides the ePQ feature. Three major HTAP solutions are offered in the industry:
Transactional and analytical queries use completely isolated storage and computing resources.
Advantages: The two request types do not affect each other.
Disadvantages:
Data needs to be imported from the transactional system to the analytical system with latency.
Two systems run in parallel, which increases costs and the difficulty of O&M.
The storage and computing resources are fully shared by the transactional and analytical systems.
Advantages: Costs are minimized and resource utilization is maximized.
Disadvantages:
Analytical and transactional queries may affect each other.
When you scale out the compute nodes, data needs to be redistributed, which affects the scale-out speed.
The transactional and analytical systems share storage resources but use separate computing resources.
NotePolarDB for PostgreSQL uses an architecture that decouples storage and computing resources. Therefore, it comes with support for this solution.
How HTAP works
Architecture characteristics
PolarDB for PostgreSQL adopts the architecture that decouples storage and computing, provides the ePQ engine, and supports cross-node parallel execution, elastic computing, and high scalability features. The ePQ engine ensures multi-node parallel execution, elastic computing, and elastic scaling. PolarDB for PostgreSQL provides the HTAP capability. It brings the following advantages:
Shared storage: data freshness is in milliseconds.
The transactional and analytical systems share the storage data to reduce storage costs and improve query efficiency.
Physical isolation of transactional and analytical systems: eliminates mutual influence in CPU and memory.
Single-node parallel query (PQ) engine: processes highly concurrent transactional queries on the primary node or a read-only node.
ePQ engine: processes high-complexity analytical queries on read-only nodes.
Serverless scaling: You can initiate ePQ queries from any read-only node.
Scale-out: You can adjust the node range for ePQ.
Scale-up: You can specify the degree of parallelism for PQ.
Elimination of data skew and computational skew, taking the affinity of the PolarDB for PostgreSQL buffer poll into full consideration.
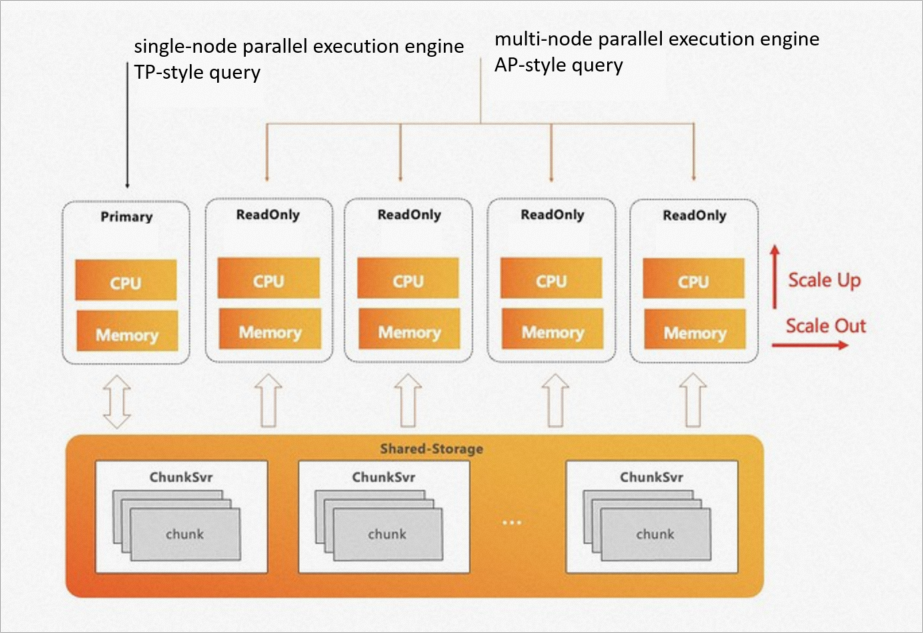
ePQ engine
The core of PolarDB for PostgreSQL ePQ is the ePQ engine. Tables A and B are joined first and then aggregated. This is also how native PostgreSQL would perform the operation on a single node. The following figure shows the execution process.

In the massively parallel processing (MPP) engine, data is scattered on different nodes. Data on different nodes may have different distribution attributes such as hash distribution, random distribution, and replication distribution. The MPP engine inserts operators into execution plans based on the data distribution characteristics of different tables to ensure that data distribution attributes are transparent to upper-layer operators.
PolarDB for PostgreSQL uses the shared storage architecture. Data stored in a PolarDB for PostgreSQL instance is accessible to all its compute nodes. On the MPP engine, each compute node worker scans all data to obtain duplicate data. The scan process is not accelerated by using the parallel scan method. It is not a real MPP engine.
Therefore, adhering to the principles of the volcano model, the ePQ engine concurrently processes all scan operators and introduces PxScan operators to mask the shared storage. PxScan operators map shared-storage data to shared-nothing data. A table is divided into multiple virtual partitions, and each worker scans its own virtual partitions to implement ePQ scanning.
The data scanned by PxScan operators is redistributed by shuffle operators. The redistributed data is executed on each worker based on the volcano model as if it were executed on a single node.
Serverless scaling
The MPP engine can only initiate MPP queries on specified nodes. Therefore, only one worker can scan one table on each node. To support serverless scaling, strong consistency of distributed transactions is introduced.
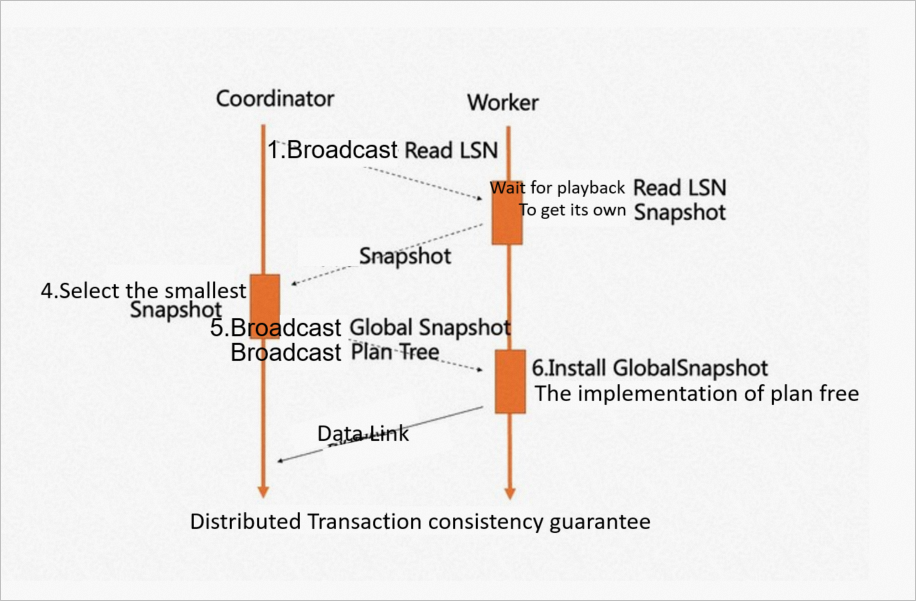
A node is selected as the coordinator node, and its ReadLSN is used as the agreed LSN. The earliest snapshot version of all nodes involved in parallel execution is the agreed global snapshot version. The LSN replay waiting and global snapshot synchronization mechanisms are used to ensure that data and snapshots are consistent and available when any node initiates an ePQ query.
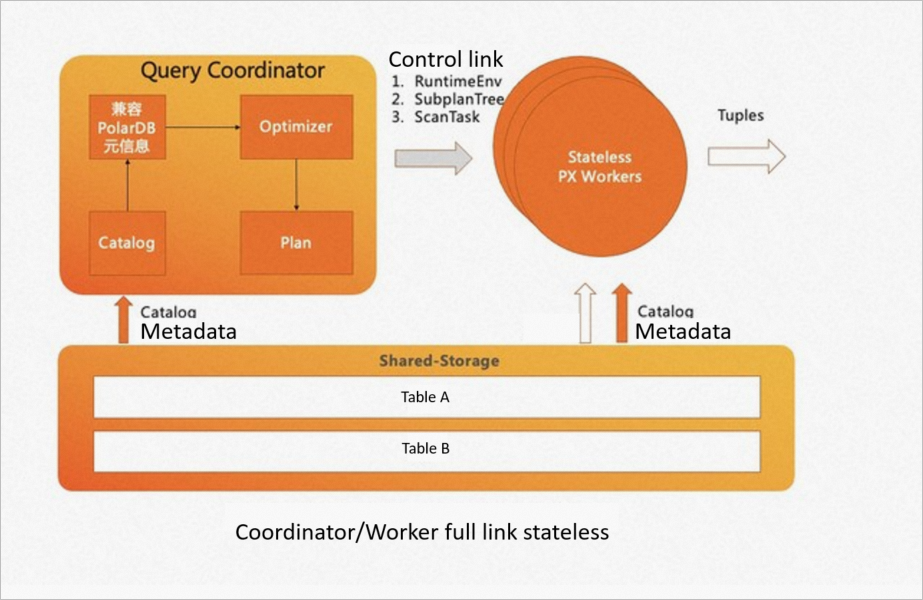
To implement serverless scaling, PolarDB for PostgreSQL adds all the external dependencies required by all modules on the chain of the coordinator node to the shared storage by using its shared storage features. Parameters required by all worker nodes are also synchronized from the coordinator node over the control link. This makes the coordinator node and worker nodes stateless.
Serverless scaling provided by PolarDB for PostgreSQL offers the following benefits:
Any node can become a coordinator node to solve the single point of failure of the coordinator node in MPP engine.
PolarDB for PostgreSQL allows you to increase the number of compute nodes and the degree of parallelism on a single node. Scaling takes effect immediately without redistributing data.
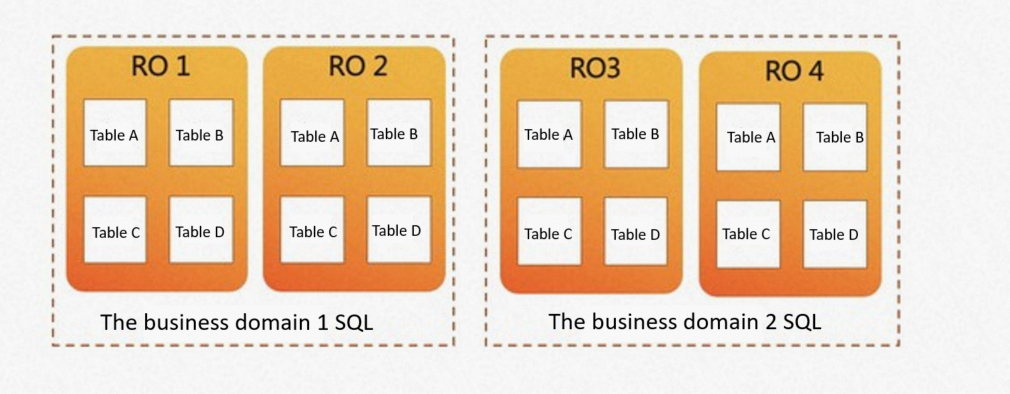
More elastic scheduling policies are available. Business domains can run on different node collections. Business domain 1 can use nodes RO1 and RO2 to perform analytical queries. Business domain 2 can select nodes RO3 and RO4 for analytical queries. Compute nodes used in the two business domains support elastic scheduling.
Skew removal
Skewness is an inherent problem of MPP and includes data skew and computational skew.
Data skew is usually caused by uneven distribution of data. In PostgreSQL, some inevitable data distribution problems are introduced due to the storage of large TOAST tables.
Computational skew is usually caused by concurrent transactions on different nodes, buffer pools, network problems, and I/O jittering.
Skew in MPP means that the execution time is determined by the slowest subtask.
PolarDB for PostgreSQL implements the adaptive scanning mechanism. The following figure shows how a coordinator node schedules the workloads among worker nodes. When data scanning begins, the coordinator node creates a task manager in the memory to schedule worker nodes based on the scanning. The coordinator node has the following threads:
Data thread: mainly processes data links and collect tuples.
Control thread: processes control links and determines the scanning progress of each scanning operator.
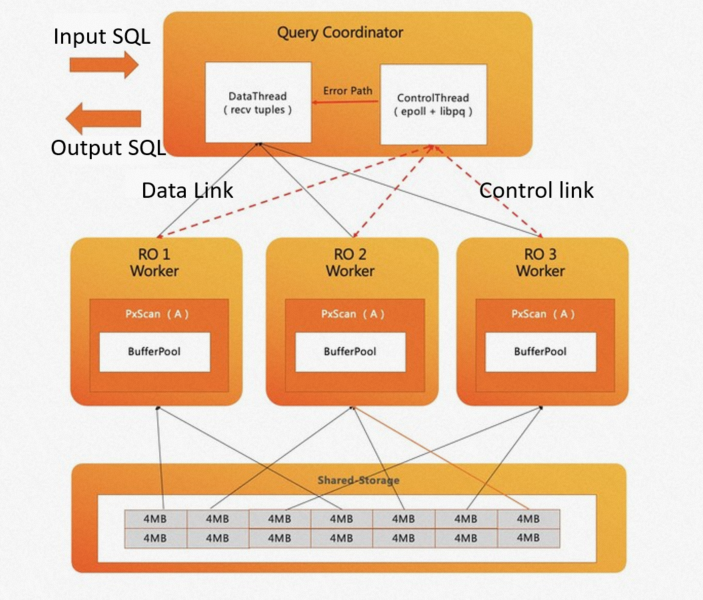
A worker node that works faster can scan multiple data blocks. In the preceding figure, the worker nodes RO1 and RO3 each scan four data blocks. The worker node RO2 scans six data blocks due to computational skew.
The adaptive scanning mechanism of PolarDB for PostgreSQL ePQ also factors in the buffer pool affinity of PostgreSQL. It ensures that each worker node always scans the same data blocks. This maximizes the buffer pool hit rate and reduces I/O bandwidth.
TPC-H performance comparison
Comparison between PQ and ePQ.
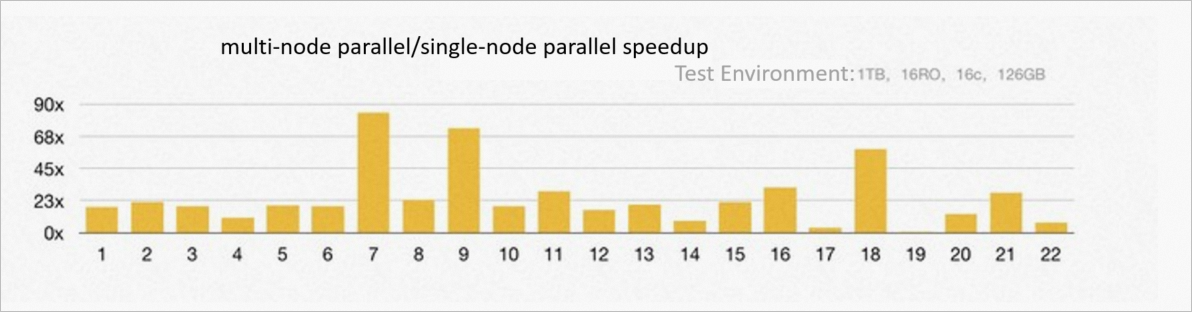
In the following example, 16 PolarDB for PostgreSQL read-only nodes with 256 GB memory are used to build a 1 TB TPC-H environment for testing. Compared with PQ, ePQ makes full use of the computing resources of all read-only nodes and the I/O bandwidth of the underlying shared storage, which solves the preceding HTAP challenges. On average, the 22 SQL statements used in TPC-H testing are executed 23 times faster because of the ePQ feature. Among them, three SQL statements are accelerated by more than 60 times, 19 SQL statements are accelerated by more than 10 times.
The performance is also boosted by scaling computing resources. As the number of CPU cores is increased from 16 to 128, the total execution time of the TPC-H queries and the execution speed of each SQL statement are linearly improved. This is clear evidence for the serverless scalability of PolarDB for PostgreSQL ePQ.
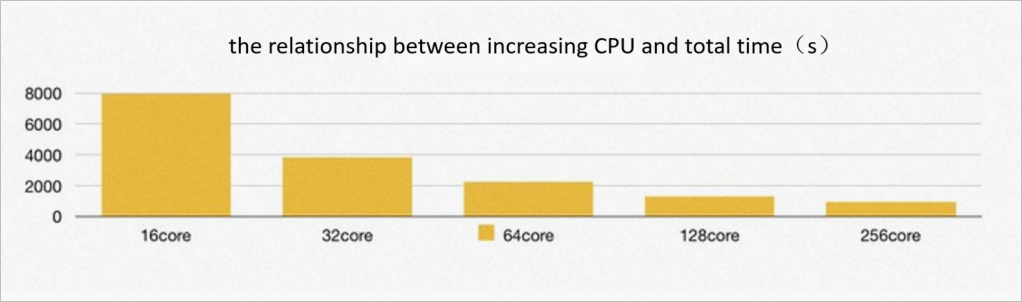
The test shows that no significant performance improvement occurs when more than 256 CPU cores are used. This is because 100% of the I/O bandwidth of the PolarDB for PostgreSQL shared storage is used, which becomes a bottleneck.
Comparison between PolarDB databases and MPP databases
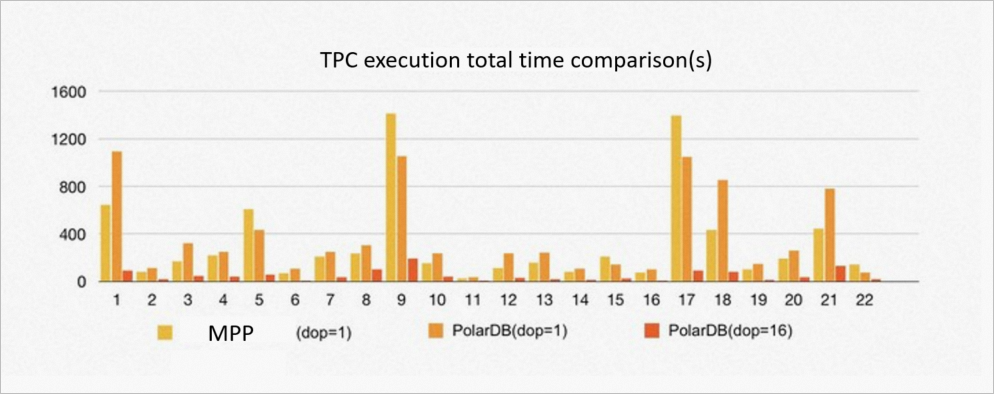
16 PolarDB for PostgreSQL read-only nodes with 256 GB memory are used to build an environment to compare the ePQ engine in PolarDB for PostgreSQL with the MPP engine.
For 1 TB of TPC-H data, the performance of PolarDB for PostgreSQL is 90% that of the MPP database in the case of the same degree of parallelism. The root cause is that the data in the MPP database uses hash distribution by default. When the join keys of two tables use their own distribution keys, a partition-wise join can be performed without shuffle redistribution. PolarDB for PostgreSQL uses the shared storage pool, and the data scanned in parallel by the PxScan operator uses an equivalent of random distribution. Shuffle redistribution is required as in the MPP database before subsequent processing. When TPC-H table joins are involved, PolarDB for PostgreSQL incurs higher overheads than the MPP database due to shuffle redistribution.
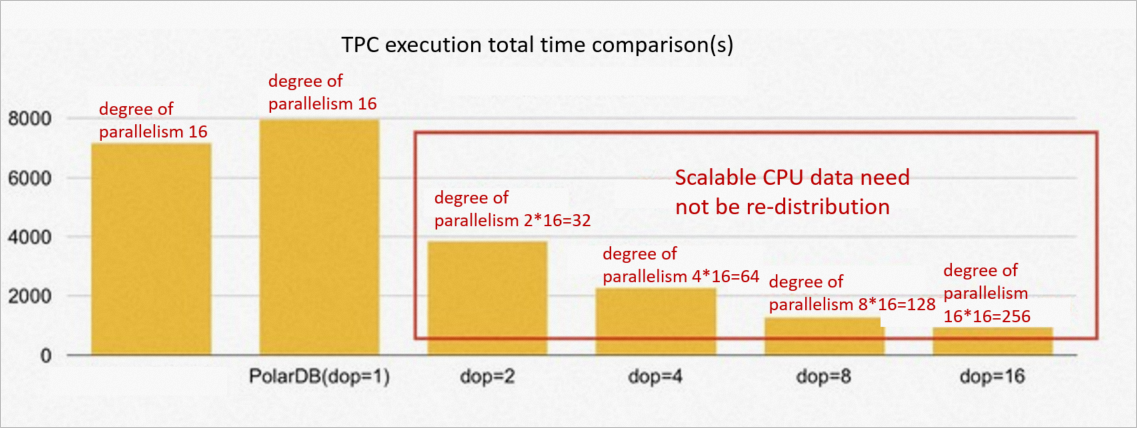
Data redistribution is not required because the ePQ engine in PolarDB for PostgreSQL supports scaling. For ePQ on 16 nodes, PolarDB for PostgreSQL can continue to expand the degree of parallelism of a single server to make full use of the resources of each server. When the degree of parallelism of PolarDB for PostgreSQL is 8, the performance is five to six times that of the MPP database. When the degree of parallelism of PolarDB for PostgreSQL increases, the overall performance of. PolarDB for PostgreSQL is enhanced. The modification of the degree of parallelism value takes effect immediately.
Features
Parallel queries
Currently, PolarDB for PostgreSQL ePQ supports the following features in parallel queries:
All basic operators are supported, such as scan, join, aggregate, and subquery.
Shared storage operators are optimized, such as shuffle operator sharing, SharedSeqScan sharing, and SharedIndexScan sharing. In SharedSeqScan sharing and SharedIndexScan sharing, when a large table joins a small table, the small table uses a mechanism similar to table replication to reduce broadcast overhead and improve performance.
Partitioned tables are supported: not only hash, range, and list partitioning, but also static pruning and dynamic pruning of multi-level partitions. In addition, PolarDB for PostgreSQL supports partition-wise joins on partitioned tables.
Degree of parallelism control: at the global, table, session, and query levels.
Serverless scaling: You can initiate ePQ queries on any node or specify the node range for them. PolarDB for PostgreSQL automatically maintains cluster topology information and supports the shared storage, primary/secondary, and three-node modes.
Parallel DML execution
For parallel DML execution, PolarDB for PostgreSQL provides the one write and multiple reads feature and the multiple writes and multiple reads feature based on the read/write splitting architecture and serverless scaling of PolarDB for PostgreSQL.
One write and multiple reads feature: multiple read workers on read-only nodes and only one write worker on the read-write node.
Multiple writes and multiple reads feature: multiple read workers on read-only nodes and multiple write workers on read-write nodes. In the multiple writes and multiple reads scenario, the degree of parallelism for reads is independent of that for writes.
The two features can be used in different scenarios. You can select them based on your business characteristics.
Acceleration of index creation
The ePQ engine in PolarDB for PostgreSQL allows you to perform queries and DML operations and accelerate the process for creating indexes. A large number of indexes are involved in OLTP business. When B-Tree indexes are created, about 80% of the time is spent on sorting and creating index pages, 20% on writing index pages. On the ePQ engine in
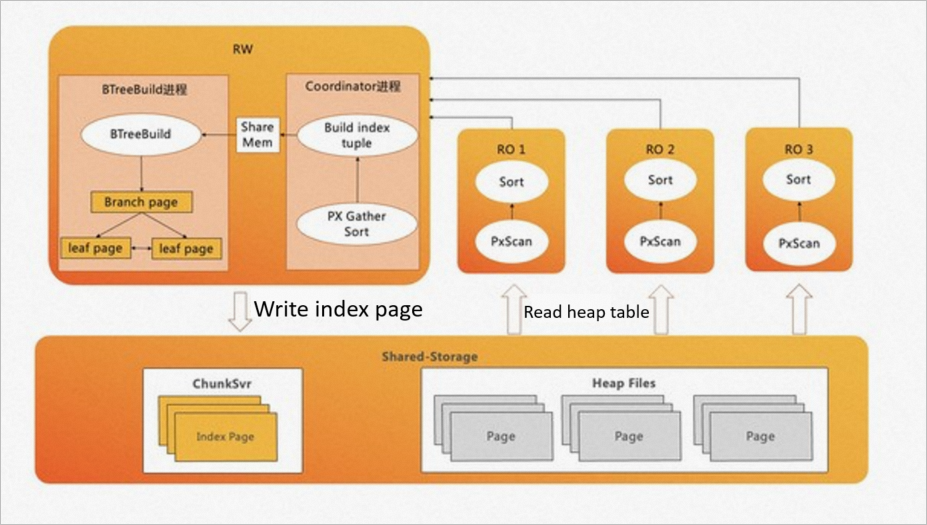 PolarDB for PostgreSQL, read-only nodes are used to accelerate data sorting. A pipelined technique is used to create index pages. Batch writing is used to boost the write speed of index pages. Note
PolarDB for PostgreSQL, read-only nodes are used to accelerate data sorting. A pipelined technique is used to create index pages. Batch writing is used to boost the write speed of index pages. NoteIn PolarDB for PostgreSQL, B-tree indexes can be created in standard mode or concurrent mode.
Usage
PolarDB for PostgreSQL ePQ is suitable for analysis-light business, such as reconciliation and reporting.
Use ePQ for analytic queries.
By default, the ePQ feature is disabled on PolarDB for PostgreSQL. To use this feature, configure the following parameters.
Parameter
Description
polar_enable_px
Specifies whether to enable the ePQ feature. Default value: off. Valid values:
on
off
polar_px_max_workers_number
Specifies the maximum number of worker processes for parallel execution on a single node. Default value: 30. Valid values: 0 to 2147483647. This parameter limits the maximum degree of parallelism on a single node.
NoteThe number of workers processes for all sessions on the node cannot exceed this value.
polar_px_dop_per_node
Specifies the degree of parallelism for the current session. Default value: 1. Valid values: 1 to 128. We recommend that you set the value equal to the number of CPU cores. If you set the parameter to N, N worker processes on each node can be used for one session.
polar_px_nodes
Specifies the read-only nodes involved in ePQ. This parameter is empty by default, which indicates that all read-only nodes are used for parallel execution. Separate multiple nodes with commas (,).
px_worker
Specifies whether ePQ is valid for a specific table. By default, ePQ is not valid for any tables. ePQ consumes certain computing resources. To save computing resources, you can specify the tables for which ePQ is valid. Sample statement:
ALTER TABLE t1 SET(px_workers=-1) indicates that ePQ is valid for the t1 table.
ALTER TABLE t1 SET(px_workers=-1) indicates that ePQ is disabled for the t1 table.
ALTER TABLE t1 SET(px_workers=0) indicates that ePQ is not valid for the t1 table.
The following examples show whether ePQ is valid. Only a single table is used in the examples.
Create the test table and insert data.
CREATE TABLE test(id int); INSERT INTO test SELECT generate_series(1,1000000);Query the execution plan.
EXPLAIN SELECT * FROM test;Sample result:
QUERY PLAN -------------------------------------------------------- Seq Scan on test (cost=0.00..35.50 rows=2550 width=4) (1 row)NoteBy default, the ePQ feature is disabled. The execution plan is Seq Scan, which is used on the native PostgreSQL.
Enable the ePQ feature.
ALTER TABLE test SET (px_workers=1); SET polar_enable_px = on; EXPLAIN SELECT * FROM test;Sample result:
QUERY PLAN ------------------------------------------------------------------------------- PX Coordinator 2:1 (slice1; segments: 2) (cost=0.00..431.00 rows=1 width=4) -> Seq Scan on test (scan partial) (cost=0.00..431.00 rows=1 width=4) Optimizer: PolarDB PX Optimizer (3 rows)Specify the compute nodes involved in ePQ.
Query the names of all the read-only nodes.
CREATE EXTENSION polar_monitor; SELECT name,host,port FROM polar_cluster_info WHERE px_node='t';Sample result:
name | host | port -------+-----------+------ node1 | 127.0.0.1 | 5433 node2 | 127.0.0.1 | 5434 (2 rows)NoteIn this example, the cluster has two read-only nodes: node1 and node2.
Specify that node1 is involved in ePQ.
SET polar_px_nodes = 'node1';Query the nodes involved in ePQ.
SHOW polar_px_nodes;Sample result:
polar_px_nodes ---------------- node1 (1 row)Notenode1 is involved in ePQ.
Query all data in the test table.
EXPLAIN SELECT * FROM test;Sample result:
QUERY PLAN ------------------------------------------------------------------------------- PX Coordinator 1:1 (slice1; segments: 1) (cost=0.00..431.00 rows=1 width=4) -> Partial Seq Scan on test (cost=0.00..431.00 rows=1 width=4) Optimizer: PolarDB PX Optimizer (3 rows) QUERY PLAN
Use ePQ for partitioned table queries.
Enable the ePQ feature.
SET polar_enable_px = ON;Enable the ePQ feature for partitioned tables.
SET polar_px_enable_partition = true;NoteThe ePQ feature is disabled for partitioned tables by default.
Enable the ePQ feature for multi-level partitioned tables.
SET polar_px_optimizer_multilevel_partitioning = true;
You can use the ePQ feature to perform the following operations on partitioned tables:
Query data from range partitions in parallel.
Query data from list partitions in parallel.
Query data from single-column hash partitions in parallel.
Prune partitions.
Query data from partitioned tables that have indexes in parallel.
Query data from partitioned tables that are joined
Query data from multi-level partitioned tables.
Use ePQ to accelerate the process for creating indexes
Enable the acceleration feature.
SET polar_px_enable_btbuild = on;Creates an index.
CREATE INDEX t ON test(id) WITH(px_build = ON);Query the table schema.
\d testSample result:
Table "public.test" Column | Type | Collation | Nullable | Default --------+---------+-----------+----------+--------- id | integer | | | id2 | integer | | | Indexes: "t" btree (id) WITH (px_build=finish)
NoteYou can create indexes only in B-Tree mode, but not in INCLUDE mode. Index columns of the expression type are not supported.
If you want to use the ePQ feature to accelerate the process of creating indexes, configure the following parameters.
Parameter
Description
polar_px_dop_per_node
Specifies the degree of parallelism when you use the ePQ feature to accelerate the process of creating indexes. Default value: 1. Valid values: 1 to 128.
polar_px_enable_replay_wait
If you use the ePQ feature to accelerate the process of creating indexes, you do not need to manually enable the acceleration feature for the current session. The acceleration feature is automatically enabled. This ensures that the most recently updated data entries can be added to indexes, and can preserve the integrity of the index table. After the indexes are created, the system resets the parameter to the default value in the database.
polar_px_enable_btbuild
Specifies whether to enable the acceleration feature. Default value OFF. Valid values: ON and OFF.
polar_bt_write_page_buffer_size
Specifies the policy on the write I/O operations when indexes are created. By default, the parameter is set to 0. This value indicates that the indexed entries are flushed to a disk by block when you create indexes. The unit of measurement is block. The maximum value is 8192. We recommend that you set the value to 4096.
If you set this parameter to 0, all index entries on an index page are flushed to a disk block by block when the index page is fully loaded.
If you set this parameter to a value that is not 0, the indexed entries to be flushed are stored in a kernel buffer of the size specified by the polar_bt_write_page_buffer_size parameter. When the buffer is fully loaded, all indexed entries in the buffer are flushed to a disk at a time. This prevents performance overheads that result from frequent I/O scheduling. This parameter helps you reduce the time that is required to create indexes by 20%.