MaxCompute allows you to configure the shuffle and sort properties for tables to enable hash clustering. The hash-clustered tables help you optimize execution plans, improve operations efficiency, and save resources based on the storage characteristics of data. This topic describes how to use hash-clustered tables in MaxCompute.
Background information
id column. SELECT t1.a, t2.b FROM t1 JOIN t2 ON t1.id = t2.id;- Broadcast hash join
If one of the to-be-joined tables is a small table, MaxCompute uses the broadcast hash join method to broadcast the small table to all join task instances and then performs a hash join between the small table and big table.
- Shuffle hash join
If both of the to-be-joined tables are large, table data cannot be broadcast. In this case, a hash shuffle is separately performed on the two tables based on join keys. Hash results are the same if the key values are the same. This way, the records that have the same key values are distributed to the same join task instance. Then, each instance creates a hash table for data records from the smaller table and joins the data in the hash table with data from the larger table in sequence based on join keys.
- Sort merge joinIf both of the to-be-joined tables are very large, the shuffle hash join method is not suitable for this scenario. This is because memory resources are not sufficient to create a hash table. In this case, a hash shuffle is separately performed on the two tables based on join keys. Then, data is sorted based on join keys. At last, the sorted data records from the two tables are joined.
The following figure describes the process of a sort merge join.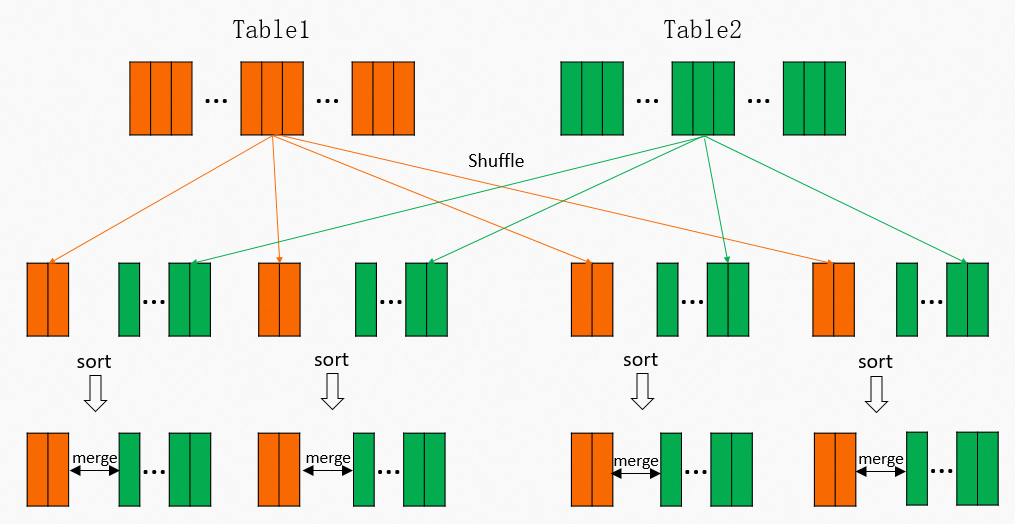 In terms of the amount of data in MaxCompute, the sort merge join method is used in most cases. However, the sort merge join method consumes a large number of resources. In the preceding figure, computing operations are performed when data is shuffled. Intermediate results are then stored on disks. When reducers read data during subsequent operations, data reading and sorting are also required. In scenarios in which
In terms of the amount of data in MaxCompute, the sort merge join method is used in most cases. However, the sort merge join method consumes a large number of resources. In the preceding figure, computing operations are performed when data is shuffled. Intermediate results are then stored on disks. When reducers read data during subsequent operations, data reading and sorting are also required. In scenarios in which Mmappers andRreducers are deployed,M × RI/O operations are involved. The following figure shows the physical execution plan of a Fuxi job. In the execution plan, two map stages and one join stage are required. Operations in red boxes are shuffle and sort operations.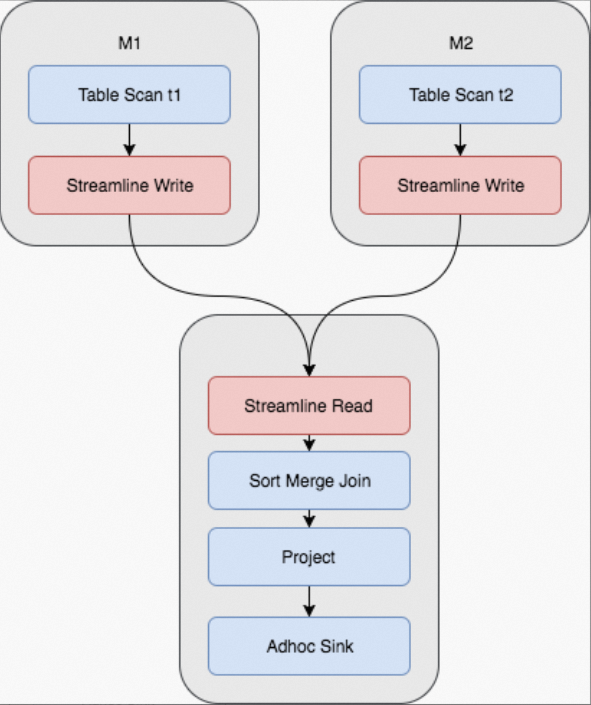 Some join operations may be repeatedly performed in data queries. For example, you can change the original query statement to the following statement:
Some join operations may be repeatedly performed in data queries. For example, you can change the original query statement to the following statement:
In this statement, the selected columns are different from those in the original query statement, but the JOIN clauses are the same, and the entire shuffle and sort processes are the same.SELECT t1.c, t2.d FROM t1 JOIN t2 ON t1.id = t2.id;You can also change the original query statement to the following statement:
In this statement, the t1 and t3 tables are joined. However, for the t1 table, the entire shuffle and sort processes are still the same.SELECT t1.c, t3.d FROM t1 JOIN t3 ON t1.id = t3.id;To prevent repeated shuffle and sort operations, you can store table data in MaxCompute based on hash shuffle and data sorting when you create a table. This way, some additional operations are performed in the table creation process, but shuffle and join operations are not repeatedly performed during data queries. The following figure shows the physical execution plan of a Fuxi job that joins tables with the preceding storage characteristics. In this plan, repeated shuffle and sort operations are no longer performed and three stages are changed to one stage.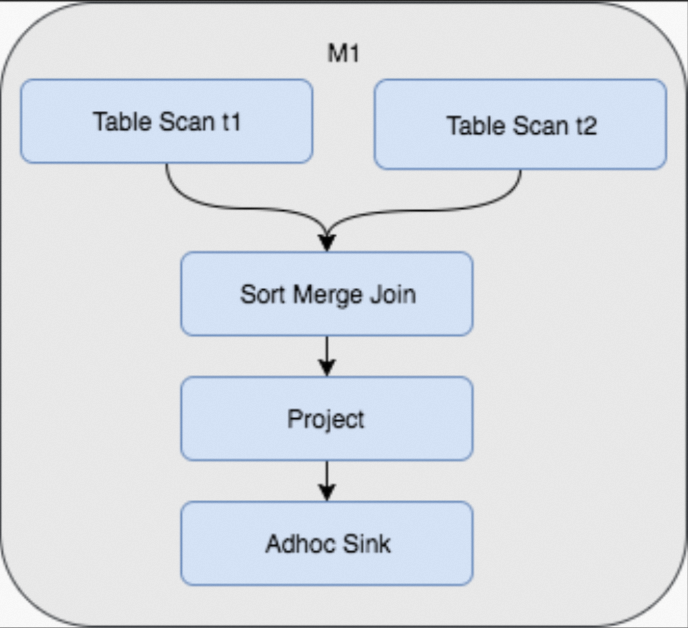
Procedure
Create a hash-clustered table
- Syntax
CREATE TABLE [IF NOT EXISTS] <table_name> [(<col_name> <data_type> [comment <col_comment>], ...)] [comment <table_comment>] [PARTITIONED BY (<col_name> <data_type> [comment <col_comment>], ...)] [CLUSTERED BY (<col_name> [, <col_name>, ...]) [SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])] INTO <number_of_buckets> BUCKETS] [AS <select_statement>] - Examples
- Non-partitioned table
CREATE TABLE T1 (a string, b string, c bigint) CLUSTERED BY (c) SORTED by (c) INTO 1024 BUCKETS; - Partitioned table
CREATE TABLE T1 (a string, b string, c bigint) PARTITIONED BY (dt string) CLUSTERED BY (c) SORTED by (c) INTO 1024 BUCKETS;
- Non-partitioned table
- Parameters
- CLUSTERED BY
Specifies the hash keys based on which MaxCompute performs hash operations on specified columns. After hash operations are performed, MaxCompute distributes data to buckets based on hash values. To prevent data skew issues and hot spots and improve the concurrent execution efficiency, we recommend that you specify columns that have large value ranges and a small number of duplicate key values in CLUSTERED BY. To optimize join operations, we recommend that you select commonly used join keys or aggregate keys. The join keys and aggregate keys are similar to the primary keys in conventional databases.
- SORTED BY
Specifies how to sort fields in a bucket. To improve query performance, we recommend that you keep the configuration of SORTED BY consistent with that of the CLUSTERED BY parameter. If you specify the SORTED BY parameter, MaxCompute automatically generates indexes and accelerates queries based on the indexes.
- INTO number_of_buckets BUCKETS
Specifies the number of buckets. This parameter is required and is determined based on the amount of data. More buckets indicate higher concurrency and higher execution efficiency of jobs. However, if an excessive number of buckets exist, excessive small files may be generated. Excessively high concurrency also increases CPU time. We recommend that you keep the data size of each bucket between 500 MB to 1 GB. If a table is extremely large, you can appropriately increase the data size of each bucket. In join optimization scenarios, the shuffle and sort steps must be removed from the join operation on two tables. Therefore, the number of buckets in a table must be a multiple of the number of buckets in the other table. For example, one table has
256buckets and the other table has512buckets. We recommend that you set the number of buckets to 2 raised to the power of N, such as 512, 1,024, 2,048, or 4,096. This way, MaxCompute can automatically split and merge buckets, and the shuffle and sort steps can be removed.
- CLUSTERED BY
Change the hash clustering properties of a table
- Syntax
-- Change a table to a hash-clustered table. ALTER TABLE <table_name> [CLUSTERED BY (<col_name> [, <col_name>, ...]) [SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])] INTO <number_of_buckets> BUCKETS]; -- Change a hash-clustered table to a non-hash-clustered table. ALTER TABLE <table_name> NOT CLUSTERED; - Usage notes
- The ALTER TABLE statement can only modify the clustering properties of a partitioned table. The clustering properties cannot be modified after they are added to a non-partitioned table.
- The ALTER TABLE statement takes effect only for the new partitions of a table, which include the new partitions generated by using the INSERT OVERWRITE statement. New partitions are stored based on the hash clustering properties. The storage formats of existing partitions remain unchanged.
- The ALTER TABLE statement takes effect only for the new partitions of a table. Therefore, you cannot specify a partition in this statement.
Explicitly verify table properties
Extended Info of the returned result. DESC EXTENDED <table_name>;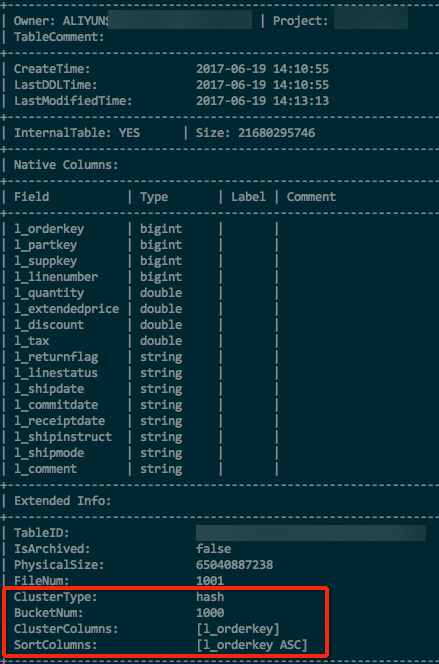 For a partitioned table, you must also execute the following statement to view the properties of a partition in the table.
For a partitioned table, you must also execute the following statement to view the properties of a partition in the table. DESC EXTENDED <table_name> partition(<pt_spec>);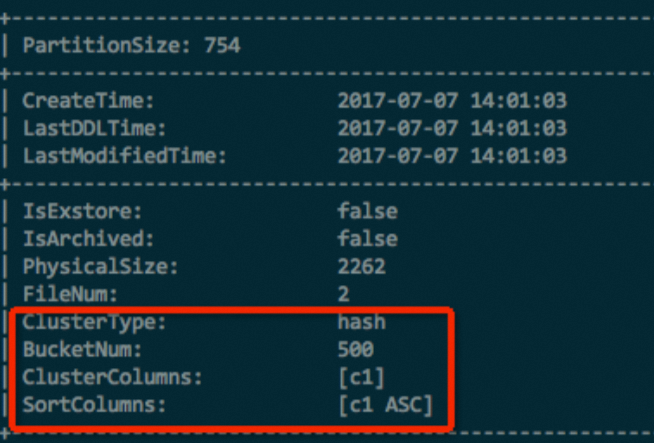
Advantages of hash clustering
Bucket pruning and index optimization
CREATE TABLE t1 (id bigint,
a string,
b string)
CLUSTERED BY (id)
SORTED BY (id) into 1000 BUCKETS;
...
SELECT t1.a, t1.b FROM t1 WHERE t1.id=12345;id column. This way, the query operation is significantly simplified.- The query job can find the bucket that corresponds to the value
12345. This way, the job needs to scan data in only a single bucket instead of all the 1,000 buckets. This process is called bucket pruning. - Data in a bucket is sorted and stored based on the
idcolumn. MaxCompute automatically creates indexes and uses the INDEX LOOKUP function to locate relevant records.
For example, for a big data task, a total of 1,111 mappers are used to read 42.7 billion records, and 26 records are matched in the final result. The entire process takes 1 minute and 48 seconds. For the same data and the same query, if you use a hash-clustered table, you can directly locate a single bucket and use indexes to read data from specific pages. This way, four mappers are used to read 10,000 records. The entire process takes only 6 seconds.
Aggregate optimization
SELECT department, SUM(salary) FROM employee GROUP BY (department);department column from the table, the data in the department column is shuffled and sorted. Then, a stream aggregate operation is performed to group data by department. However, if CLUSTERED BY (department) and SORTED BY (department) are specified in the statement when you create the table, the shuffle and sort operations are no longer required for the query operation. Storage optimization
In addition to computation optimization, storage space is greatly saved if tables are shuffled and stored in a sorted manner. MaxCompute uses column store at the underlying layer. Records that have the same or similar key values are stored together by the sort function, which facilitates encoding and compression. This way, compression efficiency is significantly improved. In some extreme testing cases, a table whose data is sorted can save 50% of the storage space in comparison with a table whose data is not sorted. If a table has a long lifecycle, we recommend that you configure the table as a hash-clustered table.
lineitem table with 100 GB of data in a TPC-H dataset is used. The table contains data of various data types such as INT, DOUBLE, and STRING. If the same data and the same compression method are used, the hash-clustered table can save about 10% of the storage space. The following figures show the comparison result. - Hash clustering is not used.
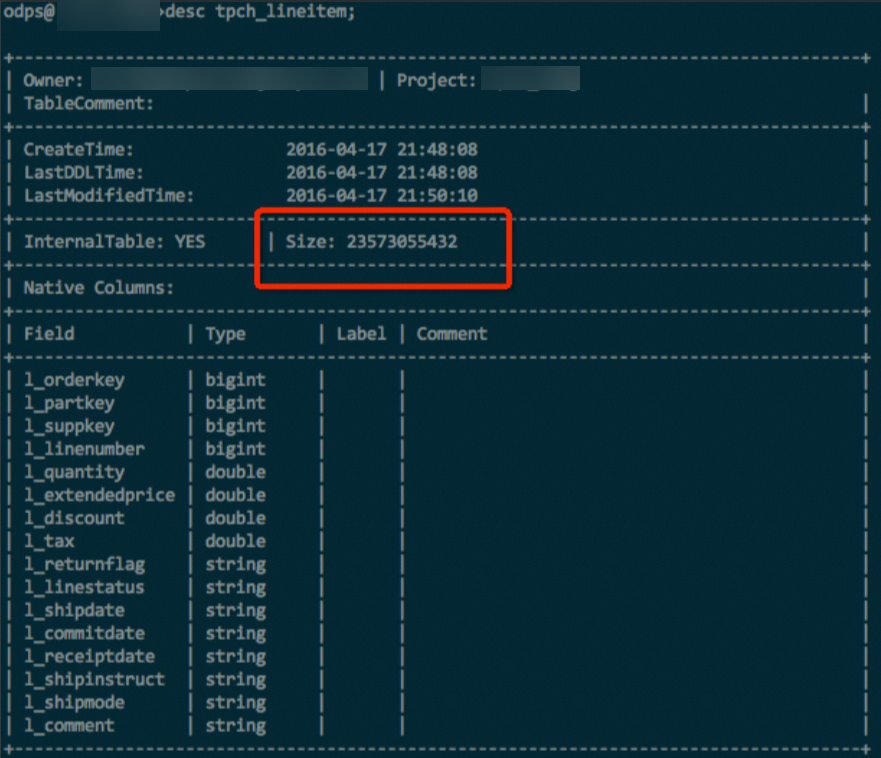
- Hash clustering is used.
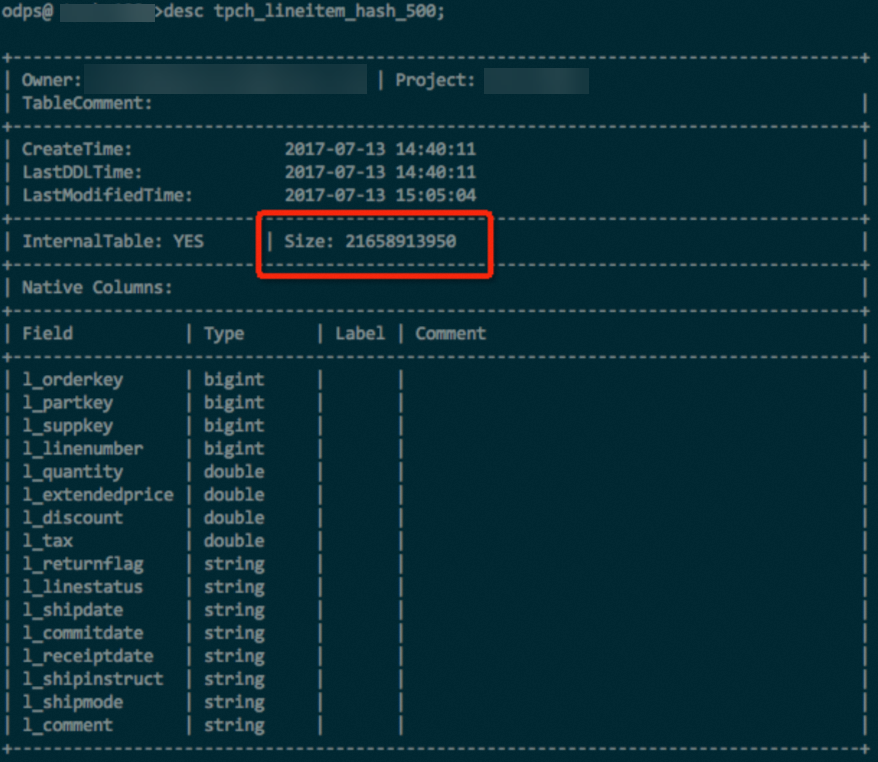
Test data and analysis
This section describes a test on a standard TPC-H dataset to measure the overall performance improvement introduced by hash clustering. In the test, data of 1 TB is stored in 500 buckets. Except for the nation and region tables in which a small amount of data is stored, the first column in other tables is used as the cluster key and sort key. The overall test result shows that the total CPU time is decreased by about 17.3% and the total job execution duration is decreased by about 12.8% after the tables are hash clustered.
The clustering properties cannot be used for some query operations on the TPC-H dataset, especially for the two most time-consuming query operations. Therefore, the total efficiency improvement is not completely obvious. For query operations for which the clustering properties are used, the efficiency improvement is completely obvious. For example, the query efficiency is improved by about 68% for TPC-H Q4, about 62% for TPC-H Q12, and about 47% for TPC-H Q10.
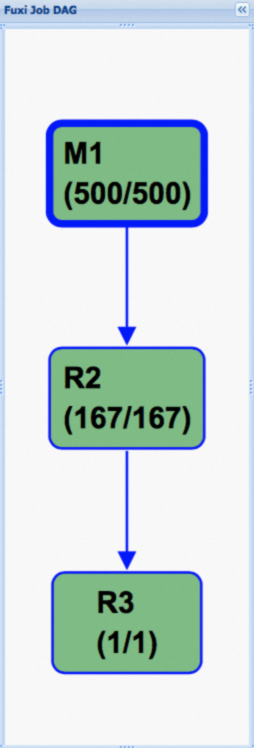
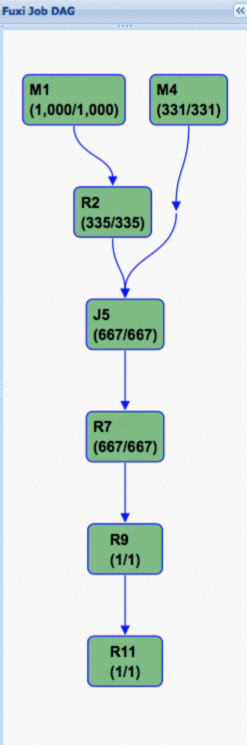 The following figure shows the execution plan of a Fuxi job after hash clustering is enabled for a table. In the execution plan, the directed acyclic graph (DAG) is significantly simplified, which is the key to performance improvement.
The following figure shows the execution plan of a Fuxi job after hash clustering is enabled for a table. In the execution plan, the directed acyclic graph (DAG) is significantly simplified, which is the key to performance improvement.