This topic describes the causes of data expansion and measures that can be taken to handle data expansion issues.
Problem description
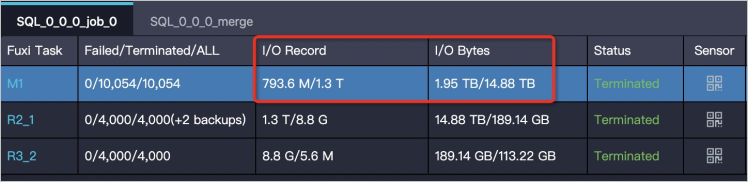
The amount of output data for a Fuxi task is much greater than the amount of its input data. The amount of input and output data can be obtained based on the I/O Record and I/O Bytes attributes of Fuxi tasks on the Logview page.
In the following figure, the amount of input data for a Fuxi task is about 1 GB and the amount of output data obtained after processing is about 1 TB. If 1 TB of data is processed on one instance, the data processing efficiency is significantly reduced.
Causes and measures
The following table describes the possible causes of this issue and related measures that can be taken.
| Cause | Description | Measure |
| Bug in code | The code is defective. Examples:
| Fix bugs in the code. |
| Improper aggregation operations | Most aggregation operations are recursive and intermediate results are merged. In most cases, the amount of intermediate result data is not large, and the computational complexity of most aggregation operations is low. Therefore, these aggregation operations are not time-consuming even if the amount of data is large. However, for some aggregation operations, such as collect_list and median, all the intermediate result data must be retained. If these aggregation operations are used with other aggregation operations, data expansion may occur. Examples:
| Do not perform aggregation operations that cause data expansion. |
Improper JOIN operations | For example, the left table of a JOIN operation contains a large amount of population data, and the right table is a dimension table, which records hundreds of rows of data for each gender. If you perform the JOIN operation on the data based on genders, the size of data in the left table may expand to hundreds of times larger than the original size. | To prevent data expansion, you can aggregate the data in the rows of the right table before you perform the JOIN operation. |