Hologres V2.0 and later supports Runtime Filter. In multi-table join scenarios, this feature automatically optimizes filtering during joins to improve query performance. This topic describes how to use Runtime Filter in Hologres.
Background information
Scenarios
Hologres V2.0 and later supports Runtime Filter. It is typically used in hash join scenarios that involve two or more tables, especially when joining a large table with a small table. No manual configuration is required. The optimizer and execution engine automatically optimize filtering during query execution. This reduces I/O overhead and improves join query performance.
How it works
To understand how Runtime Filter works, you must first understand the join process. The following is a sample SQL statement for joining two tables:
select * from test1 join test2 on test1.x = test2.x;The corresponding execution plan is shown below.

As shown in the execution plan, when the two tables are joined, a hash table is built from the test2 table. Then, the data from the test1 table is matched against the hash table. Finally, the result is returned. This join process involves two key terms:
Build side: When two tables or subqueries are joined using a hash join, the data from one table or subquery is used to build a hash table. This side is called the build side. It corresponds to the Hash node in the execution plan.
Probe side: The other side of the hash join reads data and matches it against the hash table from the build side. This side is called the probe side.
Typically, if the execution plan is correct, the smaller table is on the build side and the larger table is on the probe side.
Runtime Filter uses the data distribution of the build side to generate a lightweight filter. This filter is sent to the probe side to prune its data. This process reduces the volume of data from the probe side that is involved in the hash join and transmitted over the network, which improves hash join performance.
Therefore, Runtime Filter is most effective for joins between a large table and a small table, where the difference in data volume is significant. In these scenarios, it provides a greater performance improvement than a standard join.
Limits and trigger conditions
Limits
Only Hologres V2.0 and later supports Runtime Filter.
Runtime Filter is triggered only if the join condition contains a single field. However, starting with Hologres V2.1, Runtime Filter supports joins on multiple fields and is triggered if multiple join fields meet the conditions.
Only Hologres V4.0 and later supports TopN Runtime Filter. This feature is used to improve performance in scenarios that involve calculating TopN on a single table.
Trigger conditions
Hologres provides high-performance joins. The engine automatically triggers Runtime Filter if the SQL statement meets all of the following conditions:
The data volume on the probe side is 100,000 rows or more.
Ratio of scanned data volume:
build side / probe side <= 0.1. The smaller the ratio, the more likely Runtime Filter is to be triggered.Ratio of joined data volume:
build side / probe side <= 0.1. The smaller the ratio, the more likely Runtime Filter is to be triggered.
Types of Runtime Filter
Runtime Filter can be categorized based on the following two dimensions.
Based on whether the probe side of the hash join requires a shuffle, filters are categorized as Local or Global.
Local: Supported in Hologres V2.0 and later. When the probe side of a hash join does not require a shuffle, a Local Runtime Filter can be used in any of the following three scenarios for the build side data:
The join keys of the build side and probe side have the same data distribution.
The build side data is broadcast to the probe side.
The build side data is shuffled to the probe side based on the data distribution of the probe side.
Global: Supported in Hologres V2.2 and later. When the probe side data requires a shuffle, the Runtime Filters must be merged before they can be used. In this case, a Global Runtime Filter is required.
A Local Runtime Filter can reduce the amount of scanned data and the data processed by the hash join. A Global Runtime Filter filters data before the probe side data is shuffled, which also reduces network traffic. You do not need to specify the filter type. The engine selects the appropriate type automatically.
Based on the filter type, they are categorized as Bloom Filter, In Filter, and MinMAX Filter.
Bloom Filter: Supported in Hologres V2.0 and later. A Bloom filter can have false positives, which means some data that should be filtered out is not. However, it has a wide range of applications and can still provide high filtering efficiency and improve query performance, even with a large data volume on the build side.
In Filter: Supported in Hologres V2.0 and later. An In filter is used when the Number of Distinct Values (NDV) on the build side is small. It builds a HashSet from the build side data and sends it to the probe side for filtering. The advantage of an In filter is that it can filter data precisely and can be used with a bitmap index.
MinMAX Filter: Supported in Hologres V2.0 and later. A MinMAX filter retrieves the maximum and minimum values from the build side data and sends them to the probe side for filtering. Its advantage is that it can directly filter out entire files or batches of data based on metadata information, which reduces I/O costs.
You do not need to specify the filter type. Hologres automatically selects and uses the appropriate filter type based on the join conditions at runtime.
Verify Runtime Filter
The following examples help you better understand Runtime Filter.
Example 1: Use a Local Runtime Filter for a join condition with one column
Sample code:
begin; create table test1(x int, y int); call set_table_property('test1', 'distribution_key', 'x'); create table test2(x int, y int); call set_table_property('test2', 'distribution_key', 'x'); end; insert into test1 select t, t from generate_series(1, 100000) t; insert into test2 select t, t from generate_series(1, 1000) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x;Execution plan:
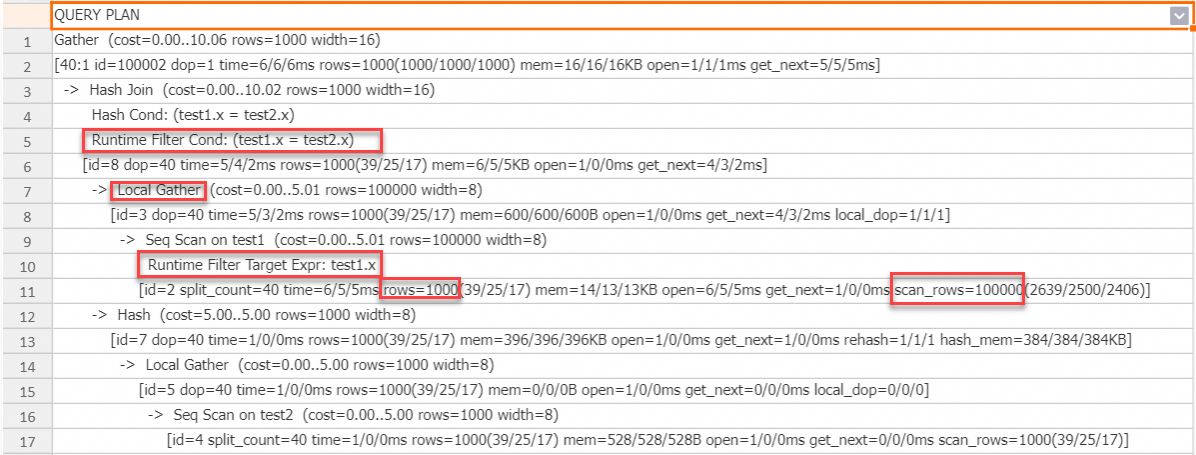
The
test2table has 1,000 rows, and thetest1table has 100,000 rows. The ratio of data volume between the build side and the probe side is 0.01, and the ratio of joined data volume is also 0.01. Both are less than 0.1. Because these conditions meet the default trigger conditions, the engine automatically uses Runtime Filter.The
test1table on the probe side has aRuntime Filter Target Exprnode. This indicates that a Runtime Filter was pushed down to the probe side.On the probe side, `scan_rows` represents the data read from storage, which is 100,000 rows. `rows` represents the number of rows from the scan operator after filtering with Runtime Filter, which is 1,000 rows. The difference between these two values shows the filtering effect of Runtime Filter.
Example 2: Use a Local Runtime Filter for a join condition with multiple columns (supported in Hologres V2.1)
Sample code:
drop table if exists test1, test2; begin; create table test1(x int, y int); create table test2(x int, y int); end; insert into test1 select t, t from generate_series(1, 1000000) t; insert into test2 select t, t from generate_series(1, 1000) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x and test1.y = test2.y;Execution plan:
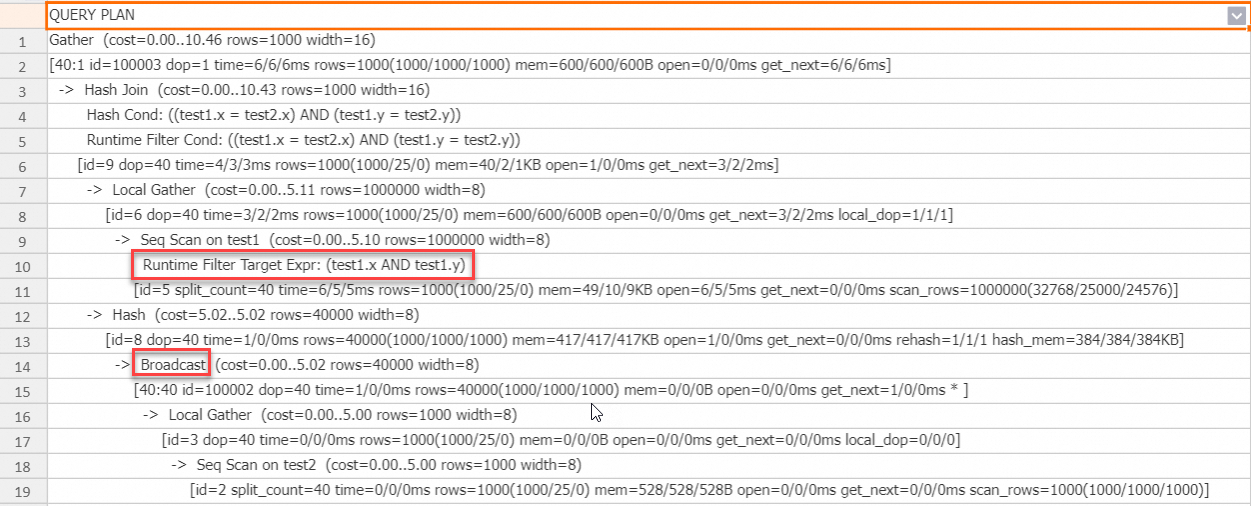
The join condition has multiple columns, and the Runtime Filter is also generated for multiple columns.
The build side is broadcast, so a Local Runtime Filter can be used.
Example 3: Use a Global Runtime Filter for a shuffle join (supported in Hologres V2.2)
Sample code:
SET hg_experimental_enable_result_cache = OFF; drop table if exists test1, test2; begin; create table test1(x int, y int); create table test2(x int, y int); end; insert into test1 select t, t from generate_series(1, 100000) t; insert into test2 select t, t from generate_series(1, 1000) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x;Execution plan:
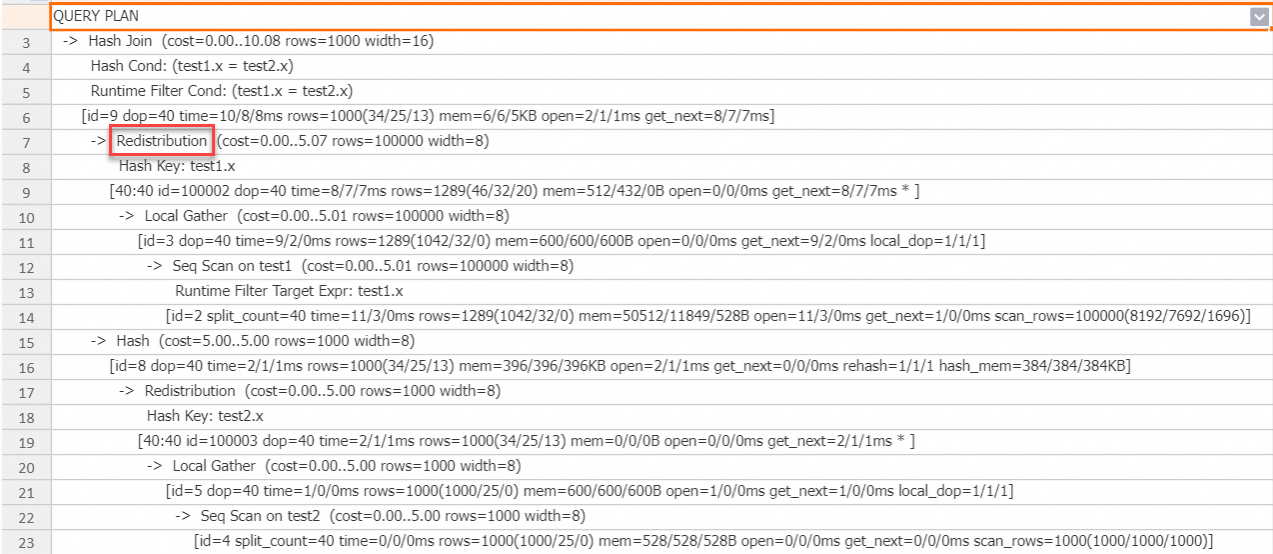
The execution plan shows that the probe side data is shuffled to the Hash Join operator. The engine automatically uses a Global Runtime Filter to accelerate the query.
Example 4: Combine an In filter with a bitmap index (supported in Hologres V2.2)
Sample code:
set hg_experimental_enable_result_cache=off; drop table if exists test1, test2; begin; create table test1(x text, y text); call set_table_property('test1', 'distribution_key', 'x'); call set_table_property('test1', 'bitmap_columns', 'x'); call set_table_property('test1', 'dictionary_encoding_columns', ''); create table test2(x text, y text); call set_table_property('test2', 'distribution_key', 'x'); end; insert into test1 select t::text, t::text from generate_series(1, 10000000) t; insert into test2 select t::text, t::text from generate_series(1, 50) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x;Execution plan:
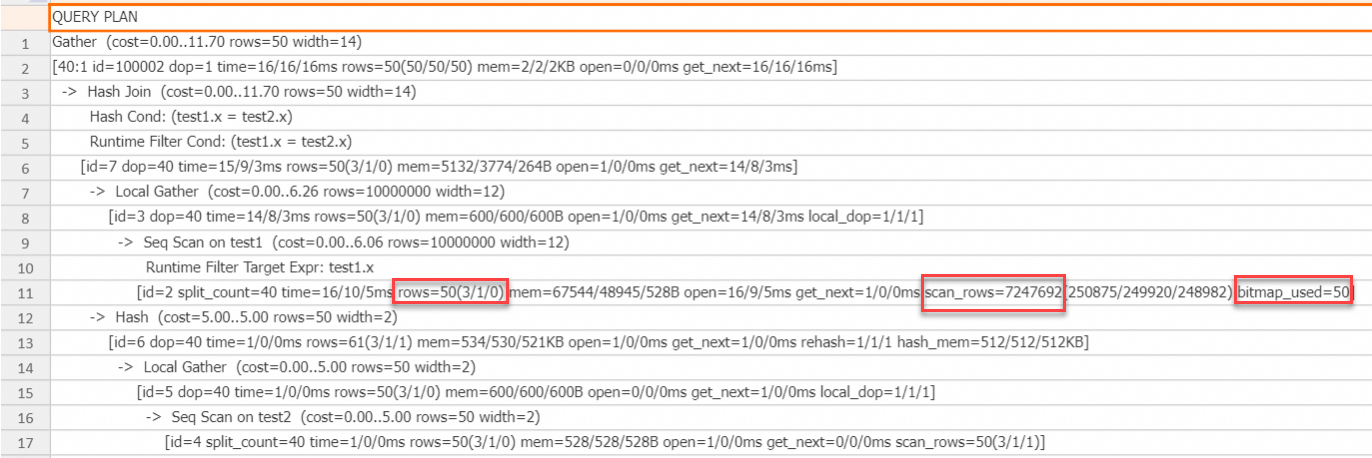
The execution plan shows that a bitmap is used on the scan operator of the probe side. The In filter provides precise filtering, reducing the output to only 50 rows. The `scan_rows` value is over 7 million, which is less than the original 10 million rows. This reduction occurs because the In filter can be pushed down to the storage engine, which can reduce I/O costs. Combining an In-type Runtime Filter with a bitmap is especially effective when the join key is a STRING type.
Example 5: Reduce I/O with a MinMax filter (supported in Hologres V2.2)
Sample code:
set hg_experimental_enable_result_cache=off; drop table if exists test1, test2; begin; create table test1(x int, y int); call set_table_property('test1', 'distribution_key', 'x'); create table test2(x int, y int); call set_table_property('test2', 'distribution_key', 'x'); end; insert into test1 select t::int, t::int from generate_series(1, 10000000) t; insert into test2 select t::int, t::int from generate_series(1, 100000) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x;Execution plan:

The execution plan shows that the scan operator on the probe side reads only a little over 320,000 rows from the storage engine. This is much less than the original 10 million rows. This reduction occurs because the Runtime Filter is pushed down to the storage engine. It uses the metadata of a data block to filter the entire block, which can significantly reduce I/O costs. This method is particularly effective when the join key is a numeric type and the value range of the build side is smaller than that of the probe side.
Example 6: TopN Runtime Filter (supported in Hologres V4.0)
In Hologres, data is processed in a streaming fashion, block by block. Therefore, when an SQL statement includes a topN operator, Hologres does not process all results at once. Instead, it generates a dynamic filter to pre-filter the data.
Take the following SQL statement as an example:
select o_orderkey from orders order by o_orderdate limit 5;The execution plan for this SQL statement is as follows:
QUERY PLAN
Limit (cost=0.00..116554.70 rows=0 width=8)
-> Sort (cost=0.00..116554.70 rows=100 width=12)
Sort Key: o_orderdate
[id=6 dop=1 time=317/317/317ms rows=5(5/5/5) mem=1/1/1KB open=317/317/317ms get_next=0/0/0ms]
-> Gather (cost=0.00..116554.25 rows=100 width=12)
[20:1 id=100002 dop=1 time=317/317/317ms rows=100(100/100/100) mem=6/6/6KB open=0/0/0ms get_next=317/317/317ms * ]
-> Limit (cost=0.00..116554.25 rows=0 width=12)
-> Sort (cost=0.00..116554.25 rows=150000000 width=12)
Sort Key: o_orderdate
Runtime Filter Sort Column: o_orderdate
[id=3 dop=20 time=318/282/258ms rows=100(5/5/5) mem=96/96/96KB open=318/282/258ms get_next=1/0/0ms]
-> Local Gather (cost=0.00..9.59 rows=150000000 width=12)
[id=2 dop=20 time=316/280/256ms rows=1372205(68691/68610/68498) mem=0/0/0B open=0/0/0ms get_next=316/280/256ms local_dop=1/1/1 * ]
-> Seq Scan on orders (cost=0.00..8.24 rows=150000000 width=12)
Runtime Filter Target Expr: o_orderdate
[id=1 split_count=20 time=286/249/222ms rows=1372205(68691/68610/68498) mem=179/179/179KB open=0/0/0ms get_next=286/249/222ms physical_reads=27074(1426/1353/1294) scan_rows=144867963(7324934/7243398/7172304)]
Query id:[1001003033996040311]
QE version: 2.0
Query Queue: init_warehouse.default_queue
======================cost======================
Total cost:[343] ms
Optimizer cost:[13] ms
Build execution plan cost:[0] ms
Init execution plan cost:[6] ms
Start query cost:[6] ms
- Queue cost: [0] ms
- Wait schema cost:[0] ms
- Lock query cost:[0] ms
- Create dataset reader cost:[0] ms
- Create split reader cost:[0] ms
Get result cost:[318] ms
- Get the first block cost:[318] ms
====================resource====================
Memory: total 7 MB. Worker stats: max 3 MB, avg 3 MB, min 3 MB, max memory worker id: 189*****.
CPU time: total 5167 ms. Worker stats: max 2610 ms, avg 2583 ms, min 2557 ms, max CPU time worker id: 189*****.
DAG CPU time stats: max 5165 ms, avg 2582 ms, min 0 ms, cnt 2, max CPU time dag id: 1.
Fragment CPU time stats: max 5137 ms, avg 1721 ms, min 0 ms, cnt 3, max CPU time fragment id: 2.
Ec wait time: total 90 ms. Worker stats: max 46 ms, max(max) 2 ms, avg 45 ms, min 44 ms, max ec wait time worker id: 189*****, max(max) ec wait time worker id: 189*****.
Physical read bytes: total 799 MB. Worker stats: max 400 MB, avg 399 MB, min 399 MB, max physical read bytes worker id: 189*****.
Read bytes: total 898 MB. Worker stats: max 450 MB, avg 449 MB, min 448 MB, max read bytes worker id: 189*****.
DAG instance count: total 3. Worker stats: max 2, avg 1, min 1, max DAG instance count worker id: 189*****.
Fragment instance count: total 41. Worker stats: max 21, avg 20, min 20, max fragment instance count worker id: 189*****.Without a TopN Filter, the Scan node reads each data block from the `orders` table and passes them to the TopN node. The TopN node uses a heap sort to maintain the top 5 rows seen so far.
For example:
Each data block contains about 8,192 rows. After processing the first block, the TopN node identifies the fifth-ranked o_orderdate in that block. Assume this date is 1995-01-01.
When the Scan node reads the second block, it uses 1995-01-01 as a filter condition. It only sends rows where o_orderdate ≤ 1995-01-01 to the TopN node. The threshold is updated dynamically. If the fifth-ranked o_orderdate in the second block is smaller than the current threshold, the TopN node updates the threshold with this new, smaller value.
You can use the EXPLAIN command to view the TopN Runtime Filter generated by the optimizer.
-> Limit (cost=0.00..116554.25 rows=0 width=12)
-> Sort (cost=0.00..116554.25 rows=150000000 width=12)
Sort Key: o_orderdate
Runtime Filter Sort Column: o_orderdate
[id=3 dop=20 time=318/282/258ms rows=100(5/5/5) mem=96/96/96KB open=318/282/258ms get_next=1/0/0ms]As shown in the example, the TopN node displays Runtime Filter Sort Column. This indicates that the TopN node will generate a TopN Runtime Filter.