Trino (formerly called PrestoSQL) is an open source distributed SQL query engine that is suitable for interactive analytic queries. In E-MapReduce (EMR) V3.44.0 and V5.10.0, PrestoSQL is renamed as Trino. In earlier EMR versions, PrestoSQL is still displayed in the console, but Trino is actually used.
Basic features
Trino is implemented in Java. It is easy to use and offers high performance and strong scalability. Trino provides the following features:
Supports American National Standards Institute (ANSI) SQL.
Supports various data sources:
Hive
Cassandra
Kafka
MongoDB
MySQL
PostgreSQL
SQL Server
Redis
Redshift
Local files
Supports advanced data structures:
Array and map data
JSON data
GIS data
Color data
Delivers strong scalability:
Various data connectors
Custom data types
Custom SQL functions
Uses a pipeline model to process data and return data in real time.
Provides a monitoring interface.
Provides a web UI, on which you can view the execution processes of queries.
Supports Java Management Extensions (JMX) protocols.
Architecture
The following figure shows the architecture of Trino. 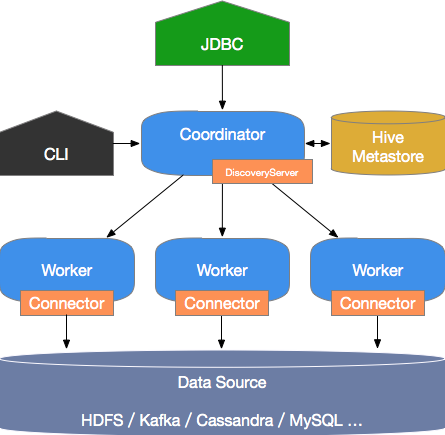
Trino has a typical master/slave architecture that comprises a coordinator node and multiple worker nodes. The coordinator node provides the following features:
Receives and parses query requests, generates an execution plan, and then delivers the execution plan to worker nodes for execution.
Monitors the running status of worker nodes. Each worker node maintains a heartbeat connection with the coordinator node.
Maintains metastore data.
Worker nodes run the tasks that are assigned by the coordinator node, use connectors to read data from external storage systems, process the data, and send the processing results to the coordinator node.
Scenarios
Trino is a distributed SQL query engine for data warehousing and data analytics services. Trino is suitable for the following scenarios:
Extract, transform, load (ETL)
Ad hoc queries
Analysis of large amounts of structured or semi-structured data
Aggregation of large amounts of multidimensional data, and report analysis
Trino is a data warehousing product. It offers limited support for transactions and is not suitable for online business scenarios.
Benefits
EMR Trino has the following advantages over open source Trino:
You can quickly deploy a Trino cluster that has hundreds of nodes.
EMR Trino supports auto scaling. You can easily scale out a Trino cluster.
EMR Trino can process data stored in Object Storage Service (OSS) buckets.
EMR Trino provides a one-stop service. No O&M is required.
Terms
Data model
A data model is a data organization form. Trino uses three levels of components to manage data, which are catalogs, schemas, and tables.
Catalog
A catalog contains multiple schemas and references an external data source, which can be accessed by using connectors. You execute an SQL statement in Trino to access one or more catalogs.
Schema
A schema is a database instance that contains multiple tables.
Table
A table is the same as a common database table.
Connector
Trino uses connectors to connect to various external data sources. Trino provides a standard service provider interface (SPI), which allows you to develop your own connectors to access custom data sources.
A catalog is typically associated with a specific type of connector that is configured in the Properties file of the catalog. Trino contains multiple built-in connectors.
References
Modify the version number in http://trino.io/docs/3XX/ based on the version number of the Trino component. Navigate to the link in a web browser to view the open source Trino documentation.
For example, navigate to https://trino.io/docs/331/ to view Trino 331 Documentation.