Set up alerting for an ACK One registered cluster to promptly detect anomalous activities and metric anomalies in Container Service for Kubernetes (ACK).
Prerequisites
An ACK One registered cluster is created and an external Kubernetes cluster deployed in an on-premises data center is connected to the ACK One registered cluster.
Configure the Cloud Monitor component in the registered cluster
Step 1: Grant RAM permissions to the Cloud Monitor component
Using onectl
Install onectl on your on-premises machine. For more information, see Use onectl to manage registered clusters.
Grant Resource Access Management (RAM) permissions to the Cloud Monitor component.
onectl ram-user grant --addon alicloud-monitor-controllerExpected output:
Ram policy ack-one-registered-cluster-policy-alicloud-monitor-controller granted to ram user ack-one-user-ce313528c3 successfully.
Using the console
Before you install a component in a registered cluster, you must obtain an AccessKey pair to access Alibaba Cloud services. To create an AccessKey pair, you must first create a RAM user and grant the RAM user the required permissions to access cloud resources.
Create a custom policy. The following code provides an example:
{ "Action": [ "log:*", "arms:*", "cms:*", "cs:UpdateContactGroup" ], "Resource": [ "*" ], "Effect": "Allow" }Create an AccessKey pair for the RAM user.
WarningWe recommend that you configure AccessKey pair-based policies for network access control, limiting AccessKey invocation sources to trusted network environments to enhance AccessKey security.
Use the AccessKey pair to create a Secret named alibaba-addon-secret in the registered cluster.
When you install the Cloud Monitor component, the system automatically uses this AccessKey pair to access the required cloud resources.
kubectl -n kube-system create secret generic alibaba-addon-secret --from-literal='access-key-id=<your access key id>' --from-literal='access-key-secret=<your access key secret>'NoteReplace
<your access key id>and<your access key secret>with the AccessKey pair that you obtained.
Step 2: Install and upgrade the Cloud Monitor component
Using onectl
Install the Cloud Monitor component.
onectl addon install alicloud-monitor-controllerExpected output:
Addon alicloud-monitor-controller, version **** installed.Using the console
The console automatically checks whether the alerting configuration meets the requirements and then guides you to activate, install, or upgrade the component.
Log on to the ACK console. In the left navigation pane, click Clusters.
On the Clusters page, find the cluster you want and click its name. In the left-side pane, choose .
On the Alert Configuration page, install and upgrade the components according to the instructions provided on the page.
After the installation and upgrade are complete, configure alerts on the Alert Configuration page.
Tab
Description
Alert Rule Management
Turn on Enabled to enable the corresponding alert rule set. Click Edit Notification Object to set the associated notification object.
Alert History
You can view the latest 100 historical records sent within the last day. Click a link in the Alert Rule column to go to the corresponding monitoring system and view the detailed rule configuration. Click Troubleshoot to quickly locate the resource page where the exception occurred (event or metric exception).
Contact Management
You can create, edit, or delete alert contacts.
Contact methods can be set through text messages, mailboxes, and robot types. You need to authenticate them first in the CloudMonitor console under to receive alert messages. Contact synchronization is also supported. If the authentication information expires, you can delete the corresponding contact in CloudMonitor and refresh the contacts page. For notification object robot type settings, see DingTalk Robot, WeCom Robot, and Lark Robot.
Contact Group Management
You can create, edit, or delete alert contact groups. If no alert contact group exists, the ACK console automatically creates a default alert contact group based on the information that you provided during registration.
Set up alerting
Step 1: Enable default alert rules
Log on to the ACK console. In the left navigation pane, click Clusters.
On the Clusters page, find the cluster you want and click its name. In the left-side pane, choose .
On the Alert Rules tab, enable the alert rule set.
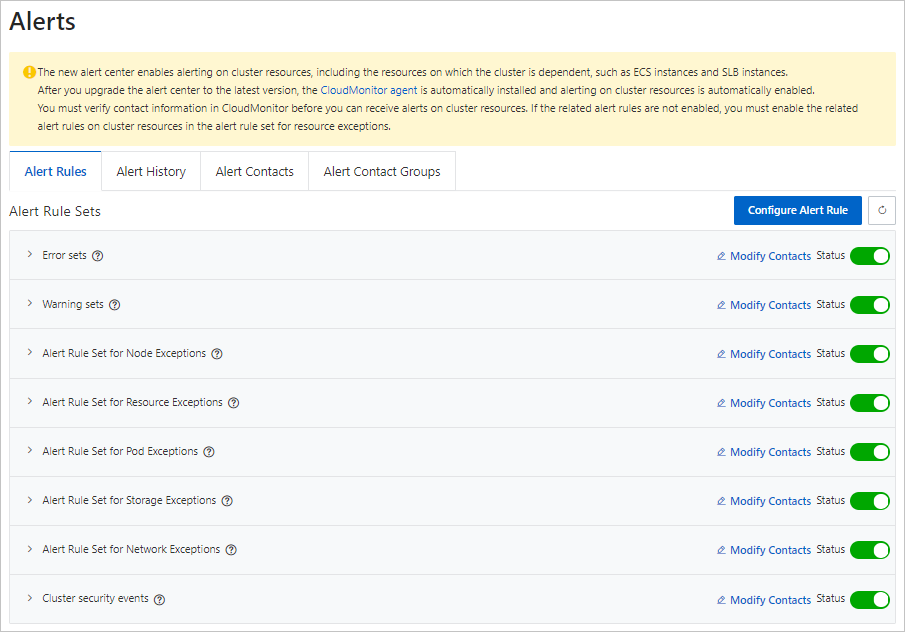
Step 2: Manually configure alert rules
Log on to the ACK console. In the left navigation pane, click Clusters.
On the Clusters page, find the cluster you want and click its name. In the left-side pane, choose .
On the Alert Rules tab, click Modify Contacts to associate notification objects. Then, turn on the Status switch to enable the alert rule set.
Feature
Description
Alert Rules
The alerting feature of ACK automatically generates alert templates for container scenarios. The templates include alerts for anomalous events and metric anomalies.
Alert rules are classified into alert rule sets. You can associate multiple contact groups with an alert rule set and enable or disable the alert rule set.
An alert rule set contains multiple alert rules. Each alert rule corresponds to a check item for a single anomaly. You can configure multiple alert rule sets in the corresponding cluster using a YAML resource. If you modify the YAML file, the alert rules are synchronized.
For more information about the YAML configuration of alert rules, see Configure alert rules using CRDs.
For more information about default alert rule templates, see Container Service Alert Management.
Alert History
You can view the last 100 alert records. Click the link in the Alert Rule column to go to the corresponding monitoring system to view the detailed rule configuration. Click the link in the Details column to go to the resource page where the alert is triggered. The resource can be an anomalous event or a resource with metric anomalies.
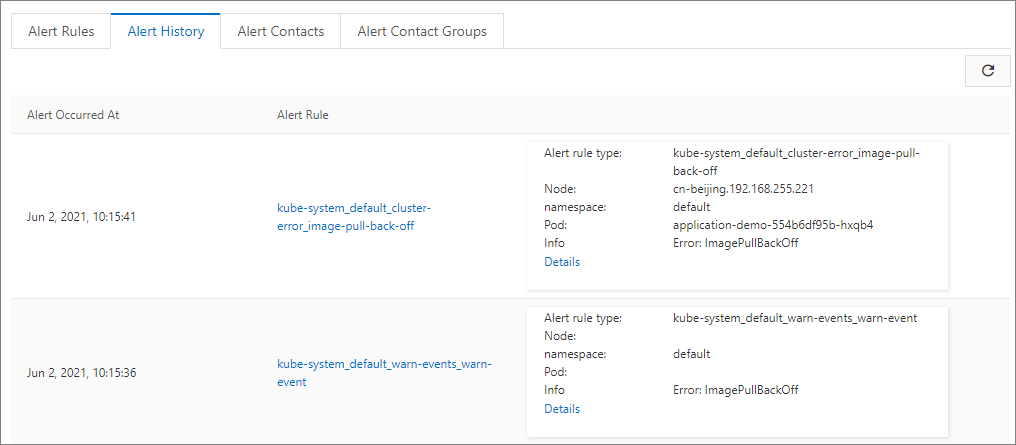
Alert Contacts
Create, edit, or delete contacts.
Alert Contact Groups
Create, edit, or delete contact groups. If no contact group exists, the console creates a default contact group based on the information of your Alibaba Cloud account.
How to configure alert rules using CRDs
When the alerting feature is enabled, an AckAlertRule resource that contains the default alert rule templates is created in the kube-system namespace. You can use this resource to configure alert rule sets for ACK in the cluster.
Procedure
Log on to the ACK console. In the left navigation pane, click Clusters.
On the Clusters page, find the cluster you want and click its name. In the left-side pane, choose .
On the Alert Rule Management tab, click Edit Alert Configuration in the upper-right corner. Then, click Actions > YAML in the row of the target rule to view the AckAlertRule resource configuration of the current cluster.
Refer to the description of the default alert rule template and modify the sample YAML file.
Example:
apiVersion: alert.alibabacloud.com/v1beta1 kind: AckAlertRule metadata: name: default spec: groups: # The following is a sample configuration of a cluster event alert rule. - name: pod-exceptions # The name of the alert rule group, which corresponds to the Group_Name field in the alert template. rules: - name: pod-oom # The name of the alert rule. type: event # The type of the alert rule (Rule_Type). Valid values: event and metric-cms. expression: sls.app.ack.pod.oom # The expression of the alert rule. When the rule type is event, the value of the expression is the value of Rule_Expression_Id in the default alert rule template described in this topic. enable: enable # The status of the alert rule. Valid values: enable and disable. - name: pod-failed type: event expression: sls.app.ack.pod.failed enable: enable # The following is a sample configuration of a cluster basic resource alert rule. - name: res-exceptions # The name of the alert rule group, which corresponds to the Group_Name field in the alert template. rules: - name: node_cpu_util_high # The name of the alert rule. type: metric-cms # The type of the alert rule (Rule_Type). Valid values: event and metric-cms. expression: cms.host.cpu.utilization # The expression of the alert rule. When the rule type is metric-cms, the value of the expression is the value of Rule_Expression_Id in the default alert rule template described in this topic. contactGroups: # The alert contact group configuration that is mapped to the alert rule. The configuration is generated by the ACK console. The same contact is used for the same account. The contact can be reused in multiple clusters. enable: enable # The status of the alert rule. Valid values: enable and disable. thresholds: # The threshold of the alert rule. For more information, see the section about how to change the threshold of an alert rule. - key: CMS_ESCALATIONS_CRITICAL_Threshold unit: percent value: '1'
Example: Modify the threshold of a cluster basic resource alert rule by using a CRD
Based on the default alert rule template set, the Rule_Type of the cluster resource exception alert rule set is metric-cms, and the alert rule is synchronized from the basic resource alert rule of CloudMonitor. In this example, the thresholds parameter is added to the CRD that corresponds to the Node - CPU usage alert rule set to configure the threshold, the number of retries, and the silence period of the basic monitoring alert rule.
apiVersion: alert.alibabacloud.com/v1beta1
kind: AckAlertRule
metadata:
name: default
spec:
groups:
# The following is a sample configuration of a cluster basic resource alert rule.
- name: res-exceptions # The name of the alert rule group, which corresponds to the Group_Name field in the alert template.
rules:
- name: node_cpu_util_high # The name of the alert rule.
type: metric-cms # The type of the alert rule (Rule_Type). Valid values: event and metric-cms.
expression: cms.host.cpu.utilization # The expression of the alert rule. When the rule type is metric-cms, the value of the expression is the value of Rule_Expression_Id in the default alert rule template described in this topic.
contactGroups: # The alert contact group configuration that is mapped to the alert rule. The configuration is generated by the ACK console. The same contact is used for the same account. The contact can be reused in multiple clusters.
enable: enable # The status of the alert rule. Valid values: enable and disable.
thresholds: # The threshold of the alert rule. For more information, see how to configure alert rules by using CRDs.
- key: CMS_ESCALATIONS_CRITICAL_Threshold
unit: percent
value: '1'
- key: CMS_ESCALATIONS_CRITICAL_Times
value: '3'
- key: CMS_RULE_SILENCE_SEC
value: '900' Parameter | Required | Description | Default value |
| Yes | The alert threshold. If this parameter is not configured, the rule fails to be synchronized and is disabled.
| The default value is the same as the default value specified in the default alert rule template. |
| No | The number of times that the alert threshold is exceeded before an alert is triggered. If this parameter is not configured, the default value is used. | 3 |
| No | The silence period after an alert is triggered. This parameter is used to prevent frequent alerting. Unit: seconds. If this parameter is not configured, the default value is used. | 900 |
Default alert rule templates
Default alert rules are created in a registered cluster in the following situations:
The default alert rule feature is enabled.
You navigate to the alert rule page for the first time when the default alert rule feature is disabled.
The following table describes the default alert rules that are created.
Alert item | Rule description | Alert source | Rule_Type | ACK_CR_Rule_Name | SLS_Event_ID |
Anomalies detected in cluster inspection | An alert is triggered when the automatic inspection mechanism detects potential anomalies. You need to analyze the specific issue and daily maintenance strategy. Submit a ticket to contact the ACK team. | Simple Log Service | event | cis-sched-failed | sls.app.ack.cis.schedule_task_failed |