This topic describes how to seamlessly migrate metadata from Amazon Web Services (AWS) Glue Data Catalog to Alibaba Cloud Data Lake Formation (DLF). The metadata includes but is not limited to information about databases, tables, and partitions. You can make full use of the centralized metadata management, permission and security management, and lake management capabilities provided by DLF to quickly build and maintain a secure and unified cloud-native data lake environment in Alibaba Cloud.
Background information
The migration supports incremental updates. You can repeatedly perform the migration operation without data duplication. Each time a job is run, the system automatically compares the metadata in the source (AWS Glue) and the destination (DLF). The system adds metadata to or updates metadata in the destination only when the metadata in the source is missing at the destination or when the metadata in the destination is different from that in the source. The system automatically clears the metadata in the destination if the metadata does not exist in the source. This ensures metadata consistency. The migration plan has been successfully applied in multiple enterprises. The following figure shows the migration process.

Migration process:
Extract metadata from AWS Glue: Use Spark to connect to the AWS Glue API and read metadata from AWS Glue. The metadata includes information about databases, tables, partitions, and functions.
Convert and process metadata: Convert and process the extracted metadata based on the migration logic to meet the requirements on the data format or data structure in Alibaba Cloud DLF. The migration logic can be incremental update or full synchronization.
Load metadata to DLF: Use the DLF API to upload the processed metadata to Alibaba Cloud DLF.
Precautions
The first time you run a Spark job to migrate metadata from a dataset that contains approximately 5,000,000 partitions, about 2 to 3 hours may be required to migrate the metadata based on previous customer experience. In subsequent job running on a regular basis, a migration operation can be complete within 20 minutes.
Procedure
Step 1: Download a JAR package
Method 1: Click glue-1.0-SNAPSHOT-jar-with-dependencies.jar to download the package.
Method 2: Run the following command on the CLI to download the JAR package:
wget http://dlf-lib.oss-cn-hangzhou.aliyuncs.com/jars/glue-1.0-SNAPSHOT-jar-with-dependencies.jar
Step 2: Prepare a configuration file
Create a configuration file named
application.propertieson your on-premises machine. If the configuration file already exists, modify the configuration file.The configuration file contains the credentials that are required to access AWS and Alibaba Cloud E-MapReduce (EMR), and other necessary configuration information.
Upload the configuration file to a specified position. For example, you can upload the configuration file to your on-premises Hadoop Distributed File System (HDFS), Alibaba Cloud Object Storage Service (OSS), or Amazon S3.
In this example, upload the configuration file to Alibaba Cloud OSS. Example: oss://<bucket>/path/application.properties.
## The AccessKey ID and AccessKey secret that are used to access AWS. The AccessKey pair can be left empty if you run a job in an AWS EMR cluster. Otherwise, you must specify an AccessKey pair.
aws.accessKeyId=xxxxx
aws.secretAccessKey=xxxxxx
## The AWS region.
aws.region=eu-central-1
## (Required) The ID of AWS Glue Data Catalog. The default value is the ID of your AWS account.
aws.catalogId=xxxx
## (Optional) The names of the databases whose metadata you want to migrate. This parameter is used to filter databases. If this parameter is not configured, metadata of all databases is migrated.
aws.databases=db1,db2
## (Optional) The prefix in the names of the tables whose metadata you want to migrate. This parameter is used to filter tables. You can specify multiple table name prefixes and separate them with commas (,). No spaces are allowed between the prefixes.
aws.table.filter.prefix=ods_,adm_
## (Optional) The partitions whose metadata you want to migrate. This parameter is used to filter partitions. You can configure multiple partition filter conditions. If this parameter is not configured, metadata of all partitions of a specific table is migrated.
aws.partition.filter.<Database name>.<Table name>=dt>=20220101
## (Required) Use fixed values.
mode=increment
comparePartition=true
## (Required) The AccessKey ID and AccessKey secret of an Alibaba Cloud account. The Alibaba Cloud account must have the required permissions to access DLF.
aliyun.accessKeyId=xxxx
aliyun.secretAccessKey=xxxxxxx
aliyun.region=eu-central-1
aliyun.endpoint=dlf.eu-central-1.aliyuncs.com
aliyun.catalogId=xxxx (By default, the DLF catalog ID is the UID.)
## (Required) The rule for replacing the table location at the source with the table location at the destination. You can specify multiple key-value pairs.
location.convertMap={"s3://xxx-eu-central-1/glue-migrate/":"oss://xxx-eu-central-1/glue-migrate/"}
## (Optional) The storage path of output results. Detailed operation logs of a migration job are stored in the path.
result.output.path=oss://<bucket>/path1/Step 3: Submit a Spark job
You must submit a Spark job on a system for which a Spark environment is configured. You can submit a Spark job in AWS or Alibaba Cloud EMR. Make sure that you can access the Spark environment over the Internet. We recommend that you submit a Spark job in Spark 2.
In this example, submit a Spark job on the master node of an Alibaba Cloud EMR cluster. For information about how to create and log on to an Alibaba Cloud EMR cluster, see Create a cluster and Log on to a cluster. The following sample code provides an example on how to submit a Spark job:
spark-submit --name migrate --class com.aliyun.dlf.migrator.glue.GlueToDLFApplication --deploy-mode cluster --conf spark.executor.instances=10 glue-1.0-SNAPSHOT-jar-with-dependencies.jar oss://<bucket>/path/application.properties Parameters:
name: the name of the job. You can specify a custom name.class: Set the value to com.aliyun.dlf.migrator.glue.GlueToDLFApplication.deploy-mode: Set the value to cluster or client.spark.executor.instances: Configure this parameter based on your business requirements. If you increase the number of instances, the job running is accelerated.glue-1.0-SNAPSHOT-jar-with-dependencies.jar: the JAR package that you downloaded in Step 1.oss://<bucket>/path/application.properties: the path to which the configuration file is uploaded in Step 2. Replace the path based on your business requirements.
Step 4: View results
View the stdout log of the driver of the job on the web UI of YARN. For more information about how to access the web UI of YARN, see Access the web UIs of open source components in the EMR console.

The log contains the following information.
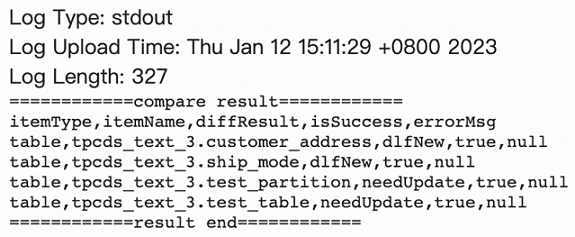
itemType: the metric type. Valid values:database,table,function, andpartition.itemName: the database name, table name, or partition name.diffResult: the difference type. Valid values:dlfNew: Metadata exists in Alibaba Cloud DLF, but does not exist in AWS Glue. In this case, you must call the delete operation in Alibaba Cloud DLF.glueNew: Metadata exists in AWS Glue, but does not exist in Alibaba Cloud DLF. In this case, you must call the create operation in Alibaba Cloud DLF.needUpdate: Metadata exists in AWS Glue and Alibaba Cloud DLF, but the metadata content is not the same. In this case, you must call the update operation to synchronize the metadata.
isSuccess: indicates whether the compensation operation is successful.errorMsg: displays error details if the compensation operation fails.