DataWorks provides Function Compute nodes that allow you to use custom code to implement different business requirements. Function Compute nodes support periodic scheduling. This facilitates the running of scheduled tasks. In addition, Function Compute nodes can work together with other types of nodes to help build a complete data processing process. This topic describes how to create and use a Function Compute node.
Prerequisites
Function Compute is activated.
You must activate Function Compute before you can use Function Compute nodes in DataWorks. We recommend that you learn the introduction to and features provided by Function Compute after you activate Function Compute to ensure smooth data development. For more information, see Activate Function Compute and What is Function Compute?
A service that is required for invoking functions is created.
A service is a basic unit for resource management in Function Compute. You can perform operations such as authorization, log configuration, and function creation at the service level. Before you can develop a function, you must create a service. For more information, see Create a service.
A function is created.
A function is the basic unit of resource scheduling and running and is the processing logic of a code snippet. To create a function in Function Compute, you must write code by using the function API provided by Function Compute and then deploy the code to Function Compute as a function. For more information about how to create a function, see Create a function.
Background information
Function Compute is an event-driven, fully-managed computing service. To use Function Compute, you need to only upload your code or images. This allows you to focus on coding without the need to purchase and manage infrastructure such as servers. You can manage services and functions in Function Compute. Function Compute supports the following types of functions:
Event function: This type of function applies to event-driven models in which functions are invoked based on events.
HTTP function: This type of function is suitable for building web applications in an efficient manner.
You can configure services and functions that you want to execute in a Function Compute node and deploy the Function Compute node to the production environment for periodic execution of the services and functions.
Limits
Limits on features
DataWorks allows you to invoke only event functions. If you want to periodically schedule an event processing function in DataWorks, you must create an event function rather than an HTTP function to process event requests in Function Compute. For information about more function types, see Function type selection.
Limits on regions
You can use the features provided by a Function Compute node only in the workspaces that reside in the following regions: China (Hangzhou), China (Shanghai), China (Beijing), China (Shenzhen), China (Chengdu), China (Hong Kong), Singapore, Malaysia (Kuala Lumpur), Indonesia (Jakarta), Germany (Frankfurt), UK (London), US (Silicon Valley), and US (Virginia).
Precautions
When you use a Function Compute node, you must invoke the event function to be executed based on the service that you created. You may not obtain the list of created services when you want to select a service. This issue may occur due to one of the following reasons:
Your current account has overdue payments. In this case, top up your account and refresh the node configuration page to try again.
Your account does not have the required permissions to obtain the service list. In this case, contact the Alibaba Cloud account to grant you the fc:ListServices permission or attach the AliyunFCFullAccess policy to your account. After the authorization is complete, refresh the node configuration page to try again. For more information about authorization, see Grant permissions to a RAM user.
When you invoke a function to run a Function Compute node in DataWorks, if the running duration of the node exceeds one hour, set the Invocation Method parameter to Asynchronous Invocation for the node. For more information about asynchronous invocation, see Overview.
If you develop a Function Compute node as a RAM user, the following system policies or custom policies must be attached to the RAM user.
Policy type
Description
System policy
Attach the
AliyunFCFullAccess,AliyunFCReadOnlyAccess, andAliyunFCInvocationAccesspolicies to the RAM user. For more information about system policies, see System policies.Custom policy
Grant the RAM user all the following permissions by using custom policies:
fc:GetAsyncTaskfc:StopAsyncTaskfc:GetServicefc:ListServicesfc:GetFunctionfc:InvokeFunctionfc:ListFunctionsfc:GetFunctionAsyncInvokeConfigfc:ListServiceVersionsfc:ListAliasesfc:GetAliasfc:ListFunctionAsyncInvokeConfigsfc:GetStatefulAsyncInvocationfc:StopStatefulAsyncInvocation
NoteFor information about more policies of Function Compute and sample policies, see the following topic or section:
1. Go to the entry point for creating a Function Compute node
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Data Development.
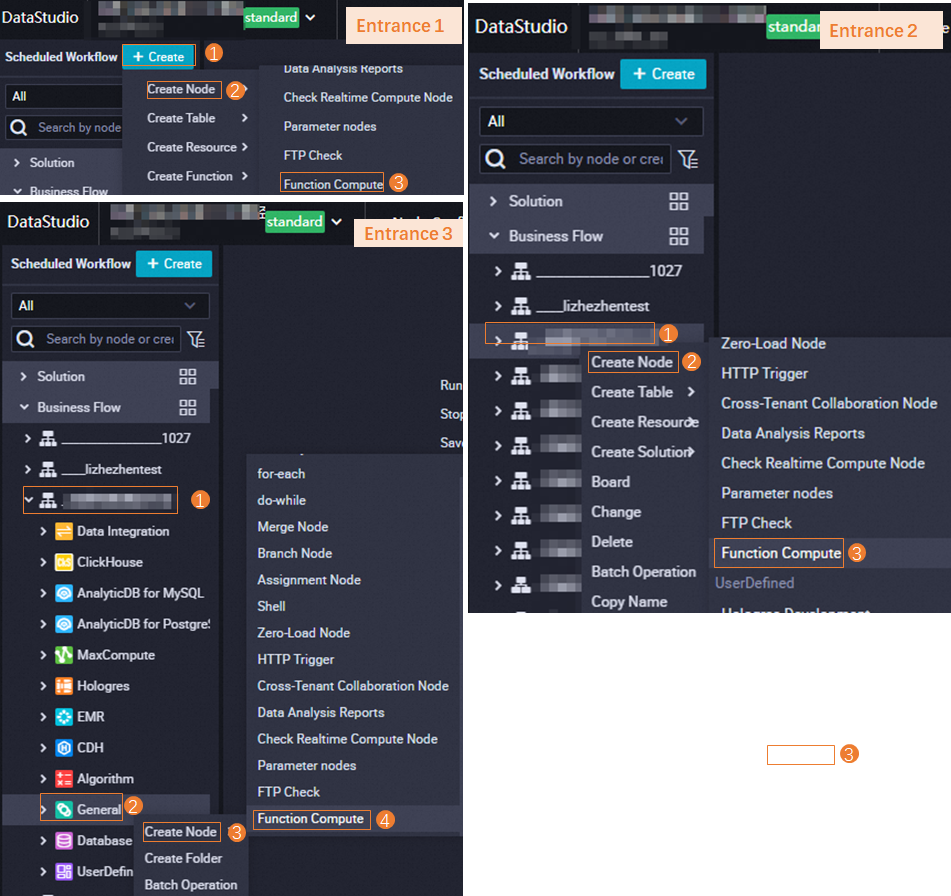
Go to the entry point for creating a Function Compute node.
On the DataStudio page, you can use one of the methods shown in the following figure to go to the entry point for creating a Function Compute node.
2. Create and configure a Function Compute node
Create a Function Compute node.
After you go to the entry point for creating a Function Compute node, configure basic information such as the node path and node name as prompted to create a Function Compute node.
Configure parameters for the Function Compute node.
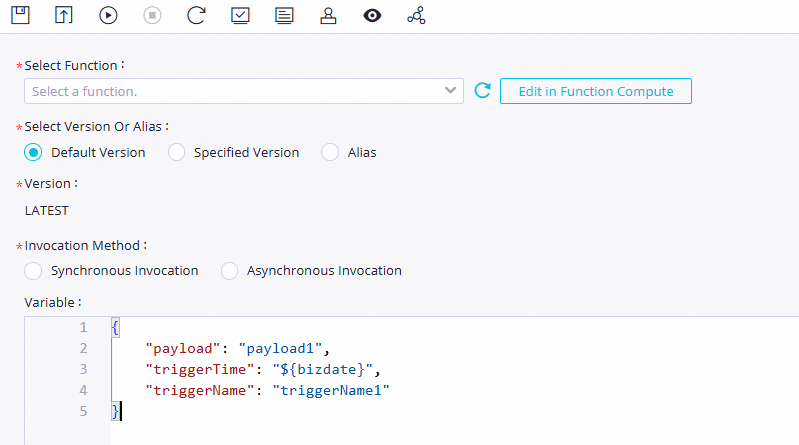
On the configuration tab of the Function Compute node, select the function that you want to invoke to run the node and specify the invocation method and variables based on your business requirements.
Parameter
Description
Select Function
Select a function that you want to invoke to run the Function Compute node. If no function is available, create a function. For more information, see Create a function.
NoteDataWorks allows you to invoke only event functions. If you want to periodically schedule an event processing function in DataWorks, you must create an event function rather than an HTTP function to process event requests in Function Compute. For information about more function types, see Function type selection.
In this example, the
para_service_01_by_time_triggersfunction is selected. When you create such a function, use the sample code for triggering a function at a scheduling time. Code logic:import json import logging logger = logging.getLogger() def handler(event, context): logger.info('event: %s', event) # Parse the json evt = json.loads(event) triggerName = evt["triggerName"] triggerTime = evt["triggerTime"] payload = evt["payload"] logger.info('triggerName: %s', triggerName) logger.info("triggerTime: %s", triggerTime) logger.info("payload: %s", payload) return 'Timer Payload: ' + payloadFor more information about the sample code of other functions, see Sample code.
Select Version Or Alias
Select the version or alias of the service that you want to use for subsequent function invocation. The default version is LATEST.
Service version
Function Compute provides the service-level versioning feature, which allows you to release one or more versions for a service. A version is similar to a service snapshot that contains the information such as the service settings, and the code and settings of functions that belong to the service. A version does not contain trigger information. When you release a version, the system generates a snapshot for the service and assigns a version number that is associated with the snapshot for future use. For more information about how to release a version, see Manage versions.
Version alias
Function Compute allows you to create an alias for a service version. An alias points to a specific version of a service. You can use an alias to perform version release, rollback, or canary release with ease. An alias is dependent on a service or a version. When you use an alias to access a service or function, Function Compute parses the alias into the version to which the alias points. This way, the invoker does not need to know the specific version to which the alias points. For information about how to create an alias, see Manage aliases.
Invocation Method
The method to invoke a function. Valid values:
Synchronous Invocation: When you synchronously invoke a function, an event directly triggers the function, and Function Compute executes the function and waits for a response. After the function is invoked, Function Compute returns the execution results of the function.
Asynchronous Invocation: When you asynchronously invoke a function, Function Compute immediately returns a response after the request is persisted instead of returning a response only after the request execution is complete.
If your function has the logic that is time-consuming, resource-consuming, or error-prone, you can use this method to allow your programs to respond to traffic spikes in an efficient and reliable manner.
We recommend that you use this method for Function Compute tasks of which the running duration exceeds one hour.
Variable
Assign values to the variables in the function based on your business requirements. The data in this field corresponds to the content on the Create New Test Event tab of the Configure Test Parameters panel for the function in the Function Compute console. To go to the Configure Test Parameters panel, go to the details page of the function in the Function Compute console and choose on the Code tab.
In this example, assign the following parameters to the variables as values in the
para_service_01_by_time_triggersfunction. The${}format is used to define thebizdatevariable. You need to assign a value to the variable in Step 4.{ "payload": "payload1", "triggerTime": "${bizdate}", "triggerName": "triggerName1" }Optional. Debug and run the Function Compute node.
After the Function Compute node is configured, you can click the
 icon to specify the resource group for running the node and assign constants to variables in the code to debug and run the node and test whether the code logic of the node is correct. The parameters that you configured to run the node are in the
icon to specify the resource group for running the node and assign constants to variables in the code to debug and run the node and test whether the code logic of the node is correct. The parameters that you configured to run the node are in the key=valueformat. If you configure multiple parameters, separate them with commas (,).NoteFor more information about node debugging, see Debugging procedure.
Configure scheduling properties for the node to schedule and run the node on a regular basis.
DataWorks provides scheduling parameters, which are used to implement dynamic parameter passing in node code in scheduling scenarios. After you define variables for a selected function on the configuration tab of the Function Compute node, you need to go to the Properties tab to assign values to the variables. In this example, $[yyyymmdd-1] is assigned to the
bizdatevariable. This way, DataWorks runs the Function Compute node at the time that is one day earlier than the scheduling time of the node. For more information about settings of scheduling parameters, see Supported formats of scheduling parameters.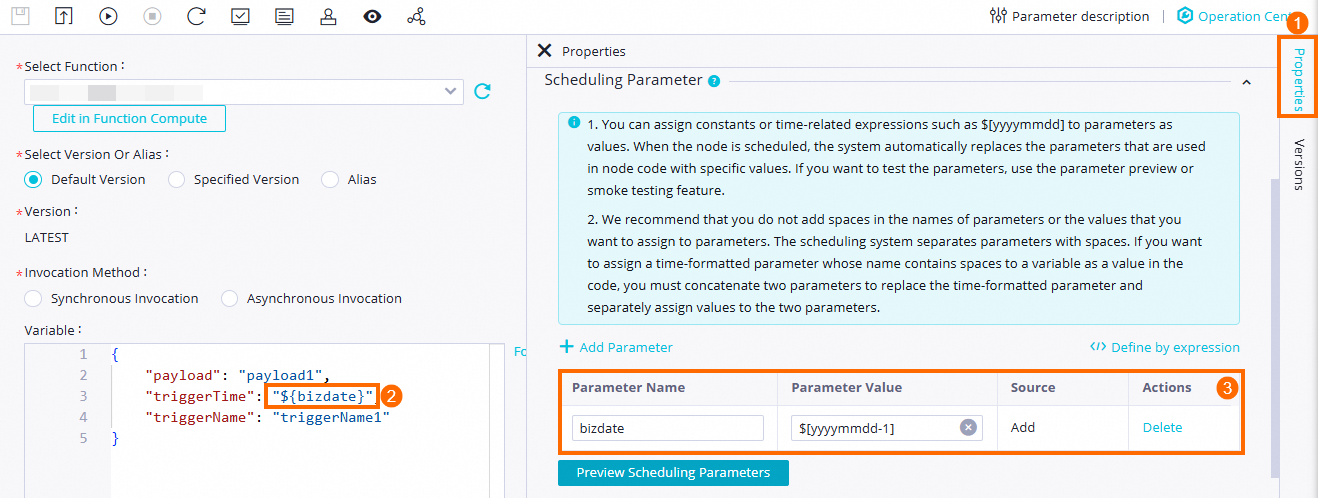 For more information about scheduling properties, see Overview.
For more information about scheduling properties, see Overview.
3. Commit and deploy the Function Compute node
Function Compute nodes can be automatically scheduled only after they are committed and deployed to the production environment.
Save and commit the Function Compute node.
Click the
 and
and  icons in the top toolbar on the configuration tab of the Function Compute node to save and commit the Function Compute node. When you commit a node, enter a change description as prompted and specify whether to perform code review and smoke testing. Note
icons in the top toolbar on the configuration tab of the Function Compute node to save and commit the Function Compute node. When you commit a node, enter a change description as prompted and specify whether to perform code review and smoke testing. NoteYou can commit the node only after you configure the Rerun and Parent Nodes parameters on the Properties tab.
If the code review feature is enabled, a node can be deployed only after the code of the node is approved by a specified reviewer. For more information, see Code review.
To ensure that the node you created can be run as expected, we recommend that you perform smoke testing before you deploy the node. For more information, see Perform smoke testing.
Optional. Deploy the Function Compute node.
If the workspace that you use is in standard mode, you must click Deploy in the upper-right corner to deploy the node after you commit it. For more information, see Differences between workspaces in basic mode and workspaces in standard mode and Deploy nodes.
What to do next
After you commit and deploy the Function Compute node to Operation Center in the production environment, you can perform O&M operations on the node in Operation Center. For more information, see Perform basic O&M operations on auto triggered nodes.
After you learn the basic steps of creating and using a Function Compute node, you can follow best practices to obtain an in-depth knowledge of Function Compute nodes. For more information, see Dynamically add watermarks to PDF files by using a Function Compute node in DataWorks.