This topic describes how to use Data Integration to synchronize data from LogHub data sources of Simple Log Service to destinations that are supported by Data Integration, such as MaxCompute, Object Storage Service (OSS), Tablestore, relational database management systems (RDBMSs), and DataHub. In this topic, a MaxCompute data source is used as a destination.
Prerequisites
A MaxCompute data source is added. For more information, see Associate a MaxCompute computing resource.
The source Logstore and the destination MaxCompute table are prepared.
Background information
You can synchronize data from a LogHub data source to a destination in the following scenarios:
Synchronize data from a LogHub data source to data sources, such as a MaxCompute data source, across regions.
Synchronize data from a LogHub data source to data sources, such as a MaxCompute data source, across Alibaba Cloud accounts.
Synchronize data from a LogHub data source to data sources, such as a MaxCompute data source, within the same Alibaba Cloud account.
Synchronize data from a LogHub data source to data sources, such as a MaxCompute data source, between the Alibaba Cloud public cloud and Alibaba Finance Cloud.
If you have Alibaba Cloud Accounts A and B, you can use Account B to create a synchronization task in Data Integration. Then, you can use the synchronization task to synchronize LogHub data within Account A to a MaxCompute data source within Account B. The following descriptions provide detailed information:
Use the AccessKey ID and AccessKey secret of Account A to add a LogHub data source.
You can use Account B to synchronize data in all Simple Log Service projects that are created by using Account A.
Use the AccessKey ID and AccessKey secret of RAM User A1 within Account A to add a LogHub data source.
Use Account A to attach the
AliyunLogFullAccessandAliyunLogReadOnlyAccesssystem policies to RAM User A1 to grant general permissions on Simple Log Service to RAM User A1. For more information, see Create a RAM user and grant permissions.NoteAfter the
AliyunLogFullAccessandAliyunLogReadOnlyAccesssystem policies are attached to RAM User A1, you can use RAM User A1 to access all Simple Log Service projects that are created by using Account A.Use Account A to grant custom permissions on Simple Log Service to RAM User A1.
Use Account A to log on to the RAM console. In the left-side navigation pane, choose . On the Policies page, click Create Policy.
For more information about RAM and how to grant custom permissions on Simple Log Service to a RAM user, see RAM overview and Overview.
If the following policy is attached to RAM User A1, you can use Account B to synchronize only data of project_name1 and project_name2 on which RAM User A1 has permissions in Simple Log Service.
{ "Version": "1", "Statement": [ { "Action": [ "log:Get*", "log:List*", "log:CreateConsumerGroup", "log:UpdateConsumerGroup", "log:DeleteConsumerGroup", "log:ListConsumerGroup", "log:ConsumerGroupUpdateCheckPoint", "log:ConsumerGroupHeartBeat", "log:GetConsumerGroupCheckPoint" ], "Resource": [ "acs:log:*:*:project/project_name1", "acs:log:*:*:project/project_name1/*", "acs:log:*:*:project/project_name2", "acs:log:*:*:project/project_name2/*" ], "Effect": "Allow" } ] }
Add a LogHub data source
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Data Integration.
In the left-side navigation pane of the Data Integration page, click Data Source.
On the Data source page, click Add Data Source.
In the Add Data Source dialog box, click LogHub.
In the Add LogHub Data Source dialog box, configure the parameters.
Parameter
Description
Data Source Name
The name of the data source. The name can contain only letters, digits, and underscores (_) and must start with a letter.
Data Source Description
The description of the data source. The description cannot exceed 80 characters in length.
LogHub Endpoint
The URL that is used to access the Simple Log Service project. The URL must be in the
http://example.comformat. example.com indicates the endpoint of the Simple Log Service project. For more information, see Endpoints.Project
The name of the Simple Log Service project.
AccessKey ID
The AccessKey ID of the Alibaba Cloud account that you use to connect to the Simple Log Service project. You can copy the AccessKey ID on the AccessKey Pair page.
AccessKey Secret
The AccessKey secret of the Alibaba Cloud account that you use to connect to the Simple Log Service project.
Find the resource group that you want to use and click Test Network Connectivity in the Connection Status (Production Environment) column.
If the connectivity test is successful, click Complete.
Create a batch synchronization task
On the Data Source page, click the
 icon in the upper-left corner and choose .
icon in the upper-left corner and choose . On the DataStudio page, move the pointer over the
 icon and select Create Workflow.
icon and select Create Workflow. In the Create Workflow dialog box, configure the Workflow Name and Description parameters and then click Create.
Click the name of the created workflow in the Scheduled Workflow pane, right-click Data Integration, and then choose .
In the Create Node dialog box, configure the Name parameter, and select a path from the Path drop-down list.
Click Confirm to go to the configuration tab of the batch synchronization task.
Configure the synchronization task by using the codeless UI
In the Configure Network Connections and Resource Group step, select the source and destination that you want to use.
Parameter
Description
Source
Select LogHub.
Data Source Name
Select the LogHub data source that you added.
Resource Group
Select the exclusive resource group for Data Integration that you want to use.
Destination
Select MaxCompute.
Data Source Name
Select the MaxCompute data source that you added.
Test the network connectivity between the exclusive resource group for Data Integration and the source and destination. If the network connectivity test is successful, click Next.
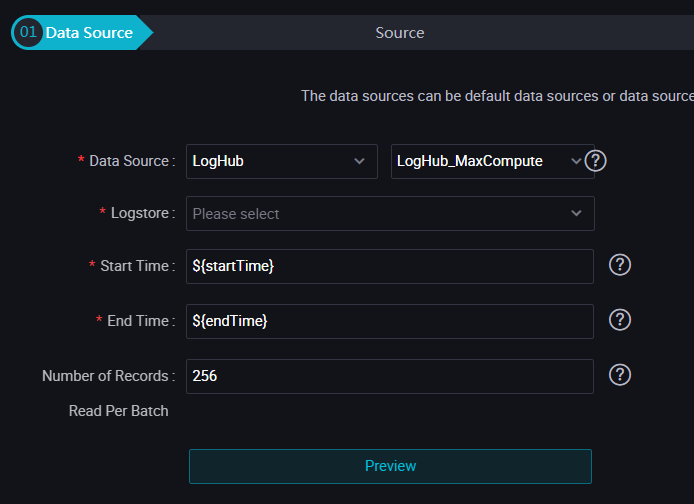
Configure information such as the source Logstore and the destination table.
The following table describes the parameters for the source.
Parameter
Description
Logstore
The name of the Logstore from which you want to read data.
Log start time
The start time of data consumption. This parameter defines the left boundary of a time range (left-closed and right-open) in the yyyyMMddHHmmss format. Example: 20180111013000. You can use this parameter together with the scheduling parameters in DataWorks.
Log end time
The end time of data consumption. This parameter defines the right boundary of a time range (left-closed and right-open) in the yyyyMMddHHmmss format. Example: 20180111013010. You can use this parameter together with the scheduling parameters in DataWorks.
Number of batches
The number of data records to read at a time. Default value: 256.
NoteYou can click Data preview to preview data. Only a small number of LogHub data records are displayed. The data records that are displayed may be different from the actual data to be synchronized due to the start time and end time that you specified.
In the Field Mapping section, configure mappings between source fields and destination fields.
In the Channel Control section, configure parameters such as Synchronization rate and Policy for Dirty Data Records.
In the right-side navigation pane of the configuration tab of the synchronization task, click Properties. On the Properties tab, configure settings such as rerun properties, a resource group for scheduling, and ancestor tasks for the synchronization task.
NoteWhen you configure ancestor tasks for the synchronization task, select Add Root Node.
Verify that the preceding configurations are correct, and click the
 icon in the top toolbar.
icon in the top toolbar. Run the batch synchronization task.
You can use one of the following methods to run the batch synchronization task:
Run the task only once.
Click the
 icon in the top toolbar to run the task on the configuration tab. Note
icon in the top toolbar to run the task on the configuration tab. NoteBefore you run the task, you must specify values for custom parameters that you configure for the task.
Enable the scheduling system to run the task based on scheduling properties.
Click the Properties tab in the right-side navigation pane of the configuration tab of the task and configure time properties such as the scheduling cycle for the task.
Then, click the
 and
and  icons in the top toolbar in sequence to commit the task to the scheduling system. The scheduling system periodically runs the task from the next day based on the properties configured for the task.
icons in the top toolbar in sequence to commit the task to the scheduling system. The scheduling system periodically runs the task from the next day based on the properties configured for the task.
Configure the batch synchronization task by using the code editor
On the configuration tab of the batch synchronization task, click the Conversion script icon in the top toolbar.

In the Tips message, click OK to switch to the code editor.
Click the Import Template icon in the top toolbar.
In the Import Template dialog box, configure the Source type, Data source, Target type, and Data source parameters and click Confirmation to apply the template.
Modify the code in the code editor based on your business requirements. Sample code:
{ "type": "job", "version": "1.0", "configuration": { "reader": { "plugin": "loghub", "parameter": { "datasource": "loghub_lzz",// The name of the LogHub data source from which you want to read data. The name must be the same as the name of the data source that you added. "logstore": "logstore-ut2",// The name of the Logstore from which you want to read data. A Logstore is a Simple Log Service unit for collecting, storing, and querying log data. "beginDateTime": "${startTime}",// The start time of data consumption. This parameter defines the left boundary of a time range (left-closed, right-open). "endDateTime": "${endTime}",// The end time of data consumption. This parameter defines the right boundary of a time range (left-closed, right-open). "batchSize": 256,// The number of data records to read at a time. Default value: 256. "splitPk": "", "column": [ "key1", "key2", "key3" ] } }, "writer": { "plugin": "odps", "parameter": { "datasource": "odps_source",// The name of the data source to which you want to write data. The name must be the same as the name of the data source that you added. "table": "test",// The name of the table to which you want to write data. "truncate": true, "partition": "",// The partition information in the destination table. "column": [// The names of the columns to which you want to write data. "key1", "key2", "key3" ] } }, "setting": { "speed": { "mbps": 8,// The maximum transmission rate. Unit: MB/s. "concurrent": 7// The maximum number of parallel threads. } } } }