This topic describes how to pass parameters between upstream and downstream nodes by defining and using input and output parameters.
Background
You define an output parameter and its value on an upstream node. You then define an input parameter on a downstream node that references the upstream output parameter. This allows the downstream node to retrieve and use the value passed from the upstream node.
Usage notes
Differences between parameter passing and passing query results:
Parameter passing: To pass parameters, you link an output parameter from the upstream node to an input parameter on the downstream node. Both are configured in their respective Input and Output Parameters sections.
Passing query results: To pass query results from an upstream node to a downstream node, link its assignment parameter to the downstream node's input parameter. Both are configured in the Input and Output Parameters section. Alternatively, you can use an assignment node.
NoteOnly specific node types, such as EMR Hive, EMR Spark SQL, ODPS Script, Hologres SQL, AnalyticDB for PostgreSQL, ClickHouse SQL, and MySQL nodes, support passing query results. Its usage is nearly identical to that of an assignment node. For more information, see Assignment node.
Limitations
The Add assignment parameter is available only in DataWorks Standard Edition and higher.
Access the parameter configuration section
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Data Development.
On the Data Studio page, double-click the node that you want to configure to open its editor.
In the right-side pane, click Properties. In the Input and Output Parameters section, click the
 icon.Note
icon.NoteFor information about how to configure scheduling parameters, see SQL-type nodes and offline synchronization nodes.
Configure output parameters
In the Input and Output Parameters section, you can configure output parameters for the current node.
Configure standard output parameters: Pass constant or variable output parameters from the current node to downstream nodes.
Configure assignment output parameters: Pass the query results of the current node as an output parameter to downstream nodes.
Configure standard output parameters
Configure a standard output parameter to pass a constant or variable from the current node to a downstream node.
Parameter | Description |
No. | The system automatically generates the sequence number. |
Parameter Name | Enter a custom name for the output parameter. |
Type | Supports Constant and Variable. |
Value | The value of the output parameter. This can be a constant or a variable:
|
Description | A brief description of the parameter. |
Add Method | The source of the parameter. Options include Added Automatically, Analyze Code, and Added Manually. |
Actions | Options to Save, Change, or Delete the parameter. Note The Change and Delete actions are not available if a downstream node depends on this parameter. Before a downstream node references this parameter, check the upstream output definition carefully to ensure it is correct. |
After you configure the parameters, click Save in the Actions column.
Configure assignment output parameters
Navigate to the section of the node.
Click Add assignment parameter to add the assignment output parameter.
When you click Add assignment parameter, the system configures the parameter to pass the query results of the current node to any downstream node that references it. If the node produces no results, the current node still runs successfully, but any downstream node that references the parameter might fail.
Downstream nodes must add this assignment parameter to their input parameters. The usage is identical to that of an assignment node. For more information, see Assignment node.
After you configure Output Parameters, you can find the output name in the . The Add Mode for this output is Added Automatically. Downstream nodes can use this output name to establish a dependency on the current node.
Configure input parameters
Configure input parameters in the Input and Output Parameters section to retrieve and use output parameters from an upstream node.
A node uses an input parameter to retrieve an output parameter from its upstream node. After you add an input parameter, you can reference it in the node's code using the same syntax as for scheduling parameters.
You must first establish a dependency on an upstream node before you can add its output as an input parameter for the current node.
Configure output parameters on the upstream node.
Configure the dependency.
On the editor page of the downstream node, click Properties in the right-side pane.
In the section, enter and select the output name that you configured for the output parameter on the upstream node.
Click Create.
Configure the input parameter on the downstream node.
In the Input and Output Parameters section, click Create to add an input parameter for the current node. Refer to the following table for parameter descriptions:
Parameter
Configuration description
No.
The system automatically generates the sequence number.
Parameter Name
Enter a custom name for the input parameter. You can use this name to reference the parameter passed from the upstream node.
Value Source
The value comes from the output parameter of an upstream node. The actual value is the output result of the upstream node.
Description
A brief description of the parameter.
Parent Node ID
The system automatically parses this value from the upstream node.
Add Method
The source of the parameter. Options include Added Automatically, Analyze Code, and Added Manually.
Actions
Options to Save, Change, or Delete the parameter.
After you configure the parameters, click Save in the Actions column.
Use the input parameter
To use an input parameter in a node, reference it using the format ${Input_Parameter_Name}. This format is the same as the one used for other system variables. The following example shows how to reference an input parameter in a Shell node.
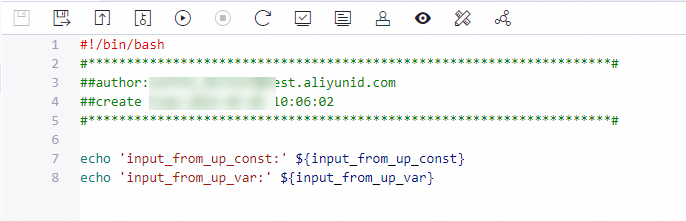
Run the entire workflow containing the nodes. Otherwise, the downstream node cannot resolve the input parameter, causing the run to fail.
System-supported global variables
System variables
System variable
Description
${projectId}
The project ID.
${projectName}
The MaxCompute project name.
${nodeId}
The node ID.
${gmtdate}
The scheduled run date of the instance, at 00:00:00. The format is
yyyy-MM-dd 00:00:00.${taskId}
The task instance ID.
${seq}
The sequence number of the task instance. This number indicates the instance's position among other instances of the same node on the same day.
${cyctime}
The scheduled time of the instance.
${status}
The status of the instance: SUCCESS or FAILURE.
${bizdate}
The business date.
${finishTime}
The instance completion time.
${taskType}
The run type of the instance: NORMAL, MANUAL, PAUSE, SKIP, UNCHOOSE, or SKIP_CYCLE.
${nodeName}
The node name.
For information about other parameter settings, see Supported formats of scheduling parameters.