When you synchronize data in an Oracle database to Hologres, you can refer to the operations in this topic to prepare configurations such as network environments and whitelists for data sources.
Prerequisites
- Prepare data sources: A source Oracle data source and a destination Hologres data source are created.
- Plan and prepare resources: An exclusive resource group for Data Integration is purchased and configured. For more information, see Plan and configure resources.
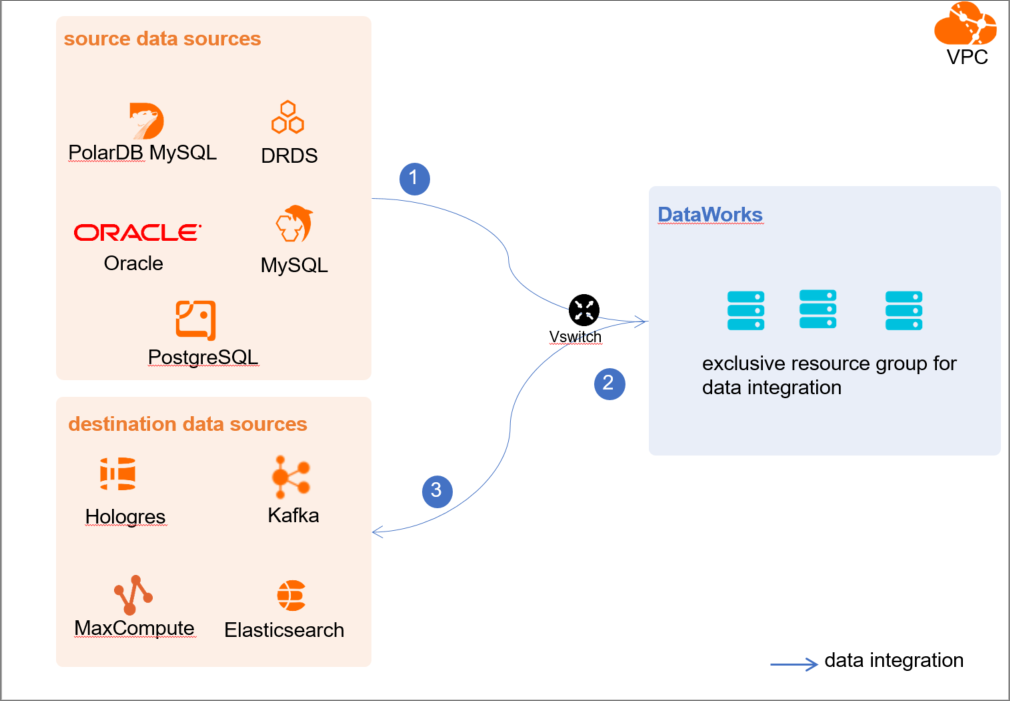
- Evaluate and plan the network environment: Before you perform data integration, you must select a network connection method based on your business requirements and use the method to connect the data sources to the exclusive resource group for Data Integration. After the data sources and the exclusive resource group for Data Integration are connected, you can refer to the operations described in this topic to configure access settings such as vSwitches and whitelists.
- If the data sources and the exclusive resource group for Data Integration reside in the same region and virtual private cloud (VPC), they are automatically connected.
- If the data sources and the exclusive resource group for Data Integration reside in different network environments, you must connect the data sources and the resource group by using methods such as a VPN gateway.
Background information
- Configure whitelists for the data sourcesIf the data sources and the exclusive resource group for Data Integration reside in the same VPC, you must add the CIDR block of the exclusive resource group for Data Integration to the whitelists of the data sources. This ensures that the exclusive resource group for Data Integration can be used to access the data sources.
- Create an account and grant permissions to the account
You must create an account that can be used to access the data sources, read data from the source, and write data to the destination during the data synchronization process.
- Check whether the version of the Oracle data source is available for creating real-time data synchronization nodes of Data Integration in DataWorks
Data synchronization from an Oracle data source in real time is implemented based on the Oracle LogMiner utility that is used to analyze log files. Only the Oracle
10g,11g,12c non-CDB,18c non-CDB, and19c non-CDBdatabases are supported by real-time data synchronization nodes in DataWorks. The Oracle12c CDB,18c CDB, and19c CDBdatabases are not supported. An Oracle database of Oracle 12c or a later version can serve as a CDB to host multiple PDBs.- You can execute one of the following statements to view the version of the Oracle database:
- Statement 1:
select * from v$version; - Statement 2:
select version from v$instance;
- Statement 1:
- If the version of the Oracle database is
12c,18c, or19c, you must execute the following statement to check whether the database can serve as aCDB. If the Oracle database can serve as aCDB, this Oracle database is not supported by real-time data synchronization nodes of Data Integration in DataWorks.select name,cdb,open_mode,con_id from v$database;
Note You must change the version of the Oracle database that is not supported by real-time data synchronization nodes of Data Integration in DataWorks. Otherwise, you cannot synchronize data from Oracle in real time by using Data Integration. - You can execute one of the following statements to view the version of the Oracle database:
- Enable the generation of database-level archived log files and redo log files and enable database-level supplemental loggingYou must enable the generation of database-level archived log files and redo log files and enable database-level supplemental logging for the Oracle database to be configured as a source data source.
- Archived log files: Oracle archives all redo log files as archived log files that are used to restore the database in the event of a failure.
- Redo log files: Oracle uses redo log files to ensure that database transactions can be re-executed. This way, data can be recovered in the case of a failure such as power outage.
- Supplemental logging: Supplemental logging is used to supplement the information recorded in redo log files. In Oracle, a redo log file is used to record the values of the fields that are modified. Supplemental logging is used to supplement the change history in the redo log file. This ensures that the redo log file contains complete information that describes data changes. If operations such as data recovery and data synchronization are performed, you can view complete statements and data updates. Some features of the Oracle database can be better implemented after supplemental logging is enabled. Therefore, you must enable supplemental logging for the database.
For example, if you do not enable supplemental logging, after you execute the UPDATE statement, the redo log file records only the values of the fields that are modified when the UPDATE statement is executed. If you enable supplemental logging, the redo log file records the values of fields before and after a modification. The conditions that are used to modify destination fields are also recorded. When an exception such as power outage occurs in the database, you can recover data based on the modification details.
We recommend that you enable supplemental logging for primary key columns or unique index columns.- After you enable supplemental logging for primary key columns, the columns that compose a primary key are recorded in logs if the database is updated.
- After you enable supplemental logging for unique index columns, the columns that compose a unique key or bitmap index are recorded in logs if a column is modified.
Before you synchronize data from an Oracle database in real time by using Data Integration in DataWorks, make sure that the generation of database-level archived log files and supplemental logging are enabled for the Oracle database. To check whether the generation of database-level archived log files and supplemental logging are enabled for the Oracle database, execute the following SQL statement:select log_mode, supplemental_log_data_pk, supplemental_log_data_ui from v$database;- The return value ARCHIVELOG of the
log_modeparameter indicates that the generation of database-level archived log files is enabled for the Oracle database. If the value ARCHIVELOG is not returned, you must enable the generation of database-level archived log files for the Oracle database. - The return value YES of the
supplemental_log_data_pkandsupplemental_log_data_uiparameters indicates that supplemental logging is enabled for the Oracle database. If the return value is FALSE, you must enable supplemental logging for the Oracle database.
- Check character encoding formats
You must make sure that the Oracle database contains only the character encoding formats that are supported by Data Integration to prevent a data synchronization failure. The following encoding formats are supported for data synchronization: UTF-8, AL32UTF8, AL16UTF16, and ZHS16GBK.
- Check data types
You must make sure that the Oracle database contains only the data types that are supported by Data Integration to prevent a data synchronization failure. The following data types are not supported for real-time data synchronization: LONG, BFILE, LONG RAW, and NCLOB.
Limits
- You can configure the supplemental logging feature only in a primary Oracle database. Supplemental logging can be enabled for a primary or secondary database.
- The following encoding formats are supported for data synchronization: UTF-8, AL32UTF8, AL16UTF16, and ZHS16GBK.
- The following data types are not supported for real-time data synchronization: LONG, BFILE, LONG RAW, and NCLOB. A maximum of 500 GB incremental data can be synchronized from an Oracle instance in real time every day.
- Only the Oracle
10g,11g,12c non-CDB,18c non-CDB, and19c non-CDBdatabases are supported by real-time data synchronization nodes in DataWorks. The Oracle12c CDB,18c CDB, and19c CDBdatabases are not supported. An Oracle database of Oracle 12c or a later version can serve as a CDB to host multiple PDBs.
Precautions
- For real-time data synchronization nodes of Data Integration, you can subscribe to online redo log files only in primary Oracle databases. You can subscribe to only archived log files in secondary Oracle databases. If you have a high requirement on the timeliness of your real-time data synchronization nodes, we recommend that you subscribe to real-time incremental change logs in primary Oracle databases. If you subscribe to archived log files in a secondary Oracle database, the minimum latency between the generation and the reception of archived logs is determined by the interval at which Oracle automatically switches between two archived log files. In this case, the timeliness of real-time data synchronization nodes cannot be ensured.
- We recommend that you retain the archived log files of your Oracle database for three days. When a large amount of data is written to an Oracle database, the speed of real-time data synchronization may be slower than that of log generation. This provides sufficient time for you to trace data when issues occur during data synchronization. You can analyze archive log files to troubleshoot issues and recover data.
- Real-time data synchronization nodes of Data Integration cannot perform
truncateoperations on tables without a primary key in an Oracle database. A real-time data synchronization node analyzes logs of a table without a primary key by performing alogmineroperation. In this process, the real-time data synchronization node usesrowidto find rows. Iftruncateoperations are performed, therowidvalues in the table are changed. This causes an error in the running of real-time data synchronization nodes. - When you run real-time data synchronization nodes on a DataWorks server with the configurations of
24 vCPUs and 192 GiB memory, the utilization of a single CPU core on an Oracle database server varies based on the status of logs in the database. If most logs are notupdatelogs and the synchronization nodes can process about 30 to 50 thousand data records every second, the utilization of a single CPU core can be 25% to 35%. If most logs areupdatelogs, the DataWorks server may encounter a performance bottleneck during real-time data synchronization, and the utilization of a single CPU core on the Oracle database server is only 1% to 5%.
Procedure
- Configure a whitelist for an Oracle database. Add the CIDR block of the VPC where the exclusive resource group resides to the whitelist of the Oracle database.
- Create an account and grant the required permissions to the account. You must create an account to log on to the database. The account must have the required permissions on the Oracle database.
- Enable the generation of archived log files and supplemental logging, and switch a redo log file. Log on to the primary database and perform the following steps:
- Execute the following SQL statements to enable the generation of archived log files:
shutdown immediate; startup mount; alter database archivelog; alter database open; - Enable supplemental logging.
SQL statements:
alter database add supplemental log data(primary key) columns; // Enable supplemental logging for primary key columns. alter database add supplemental log data(unique) columns; // Enable supplemental logging for unique index columns. - Switch a redo log file. After you enable supplemental logging, you must execute the following statement multiple times to switch a redo log file. We recommend that you execute the following statement for five times:
alter system switch logfile;Note This ensures that data can be written to the next log file after the current log file is full. Data about historical operations will not be lost. This facilitates data recovery.
- Execute the following SQL statements to enable the generation of archived log files:
- Check character encoding formats of the database. Execute the following statement to check character encoding formats of the database:
select * from v$nls_parameters where PARAMETER IN ('NLS_CHARACTERSET', 'NLS_NCHAR_CHARACTERSET');- v$nls_parameters stores values of parameters in the database.
- NLS_CHARACTERSET indicates a database character set. NLS_NCHAR_CHARACTERSET indicates a national character set. These two sets are used to store data of the character type.
The following encoding formats are supported for data synchronization: UTF-8, AL32UTF8, AL16UTF16, and ZHS16GBK. If the database contains the character encoding formats that are not supported for data synchronization, change the formats before you synchronize data. - Check the data types of tables in the database. You can execute the SELECT statement to query the data types of tables in the database. Sample statement that is executed to query the data types of the 'tablename' table:
select COLUMN_NAME,DATA_TYPE from all_tab_columns where TABLE_NAME='tablename';- COLUMN_NAME: the name of the column.
- DATA_TYPE: the data type of the column.
- all_tab_columns: the view that stores information about all columns in tables of the database.
- TABLE_NAME: the name of the table for a query. When you execute the preceding statement, replace 'tablename' with the name of the table for a query.
select * from 'tablename';statement to query the information about the desired table and obtain data types.The following data types are not supported for real-time data synchronization: LONG, BFILE, LONG RAW, and NCLOB. If a table contains one of these data types, remove the table from the real-time synchronization solution list or change the data type before you synchronize data.
What to do next
After the data sources are configured, the source, destination, and exclusive resource group for Data Integration are connected. Then, the exclusive resource group for Data Integration can be used to access the data sources. You can add the source and destination to DataWorks, and associate them with a data synchronization solution when you create the solution.
For more information about how to add a data source, see Add a data source.