The QuotaSchedulingPolicy CustomResourceDefinition (CRD) provided by the Service Mesh (ASM) traffic scheduling suite supports priority-based request scheduling after the specified request call quota is reached. When the rate of requests being processed in the system exceeds the specified quota, subsequent requests will be queued and requests with higher priorities will be processed faster. This topic describes how to use QuotaSchedulingPolicy provided by the traffic scheduling suite to implement request call quota management.
Background information
QuotaSchedulingPolicy uses the token bucket algorithm to control the rate of requests to call a specified service and queues requests when the rate exceeds the specified quota. QuotaSchedulingPolicy works in the following way:
A rate limiter that uses the token bucket algorithm is used to limit the request rate. For more information about the algorithm implementation of the rate limiter, see the Background information section in Use RateLimitingPolicy to implement user-specific throttling.
After the request rate exceeds the quota limit, subsequent requests are queued and sent to the destination service after the previous requests are processed. This ensures that the request rate is always maintained at the specified value. In addition, high-priority requests have a greater chance of being taken out of the queue and sent to the destination service.
Different from the throttling scenario, when you use QuotaSchedulingPolicy, if the request rate exceeds the quota limit, QuotaSchedulingPolicy does not directly reject requests but puts them in a priority queue. QuotaSchedulingPolicy schedules requests based on their priorities while ensuring that the request rate is within the quota limit.
Prerequisites
A Container Service for Kubernetes (ACK) managed cluster is added to your ASM instance, and the version of your ASM instance is V1.21.6.95 or later. For more information, see Add a cluster to an ASM instance.
You have connected to the ACK cluster by using kubectl. For more information, see Obtain the kubeconfig file of a cluster and use kubectl to connect to the cluster.
The ASM traffic scheduling suite is enabled. For more information, see Enable the ASM traffic scheduling suite.
Automatic sidecar proxy injection is enabled for the default namespace in the ACK cluster. For more information, see Manage global namespaces.
An ASM ingress gateway named ingressgateway is created and port 80 is enabled. For more information, see Create an ingress gateway.
The HTTPBin application is deployed and can be accessed over a gateway. For more information, see Deploy the HTTPBin application.
Step 1: Create QuotaSchedulingPolicy
Use kubectl to connect to the ASM instance. For more information, see Use kubectl on the control plane to access Istio resources.
Create a quotaschedulingpolicy.yaml file that contains the following content:
apiVersion: istio.alibabacloud.com/v1 kind: QuotaSchedulingPolicy metadata: name: quotascheduling namespace: istio-system spec: quota_scheduler: bucket_capacity: 10 fill_amount: 10 rate_limiter: interval: 1s scheduler: workloads: - label_matcher: match_labels: http.request.header.user_type: guest parameters: priority: 50.0 name: guest - label_matcher: match_labels: http.request.header.user_type: subscriber parameters: priority: 200.0 name: subscriber selectors: - service: httpbin.default.svc.cluster.localThe following table describes some of the fields. For more information about the related fields, see Description of QuotaSchedulingPolicy fields.
Field
Description
fill_amount
The number of tokens to be added within the time interval specified by the interval field. In this example, the value is 10, which indicates that the token bucket is filled with 10 tokens after each interval specified by the interval field.
interval
The interval at which tokens are added to the token bucket. In this example, the value is 1s, which indicates that the token bucket is filled with 10 tokens every 1 second.
bucket_capacity
The maximum number of tokens in the token bucket. When the request rate is lower than the token bucket filling rate, the number of tokens in the token bucket will continue to increase until the maximum number,
bucket_capacity, is reached.bucket_capacityis used to allow a certain degree of burst traffic. In this example, the value is 10, which is the same as the value of thefill_amountfield. In this case, no burst traffic is allowed.workloads
Two types of requests are defined based on
user_typein the request headers:guestandsubscriber. The priority of a request of theguesttype is 50, and that of a request of thesubscribertype is 200.selectors
The services to which the throttling policy is applied. In this example, the httpbin.default.svc.cluster.local service is used, which indicates that concurrency limiting is performed on the httpbin.default.svc.cluster.local service.
Run the following command to create QuotaSchedulingPolicy:
kubectl apply -f quotaschedulingpolicy.yamlStep 2: Verify whether QuotaSchedulingPolicy takes effect
In this example, the stress testing tool Fortio is used. For more information, see the Installation section of Fortio on the GitHub website.
Open two terminals and run the following two stress testing commands at the same time to start testing. During the entire testing, make sure that the two terminals work as expected. In the tests on the two terminals, 10 concurrent requests are sent to the service and the queries per second (QPS) is 10,000, which significantly exceeds the concurrent requests that the service can bear.
fortio load -c 10 -qps 10000 -H "user_type:guest" -t 30s -timeout 60s -a http://${IP address of the ASM ingress gateway}/status/201fortio load -c 10 -qps 10000 -H "user_type:subscriber" -t 30s -timeout 60s -a http://${IP address of the ASM ingress gateway}/status/202NoteReplace
${IP address of the ASM ingress gateway}in the preceding commands with the IP address of your ASM ingress gateway. For more information about how to obtain the IP address of the ASM ingress gateway, see substep 1 of Step 3 in the Use Istio resources to route traffic to different versions of a service topic.Expected output from test 1:
... # target 50% 4.83333 # target 75% 5.20763 # target 90% 5.38203 # target 99% 5.48668 # target 99.9% 5.49714 Sockets used: 10 (for perfect keepalive, would be 10) Uniform: false, Jitter: false Code 201 : 70 (100.0 %) Response Header Sizes : count 70 avg 249.94286 +/- 0.2871 min 248 max 250 sum 17496 Response Body/Total Sizes : count 70 avg 249.94286 +/- 0.2871 min 248 max 250 sum 17496 All done 70 calls (plus 10 warmup) 4566.839 ms avg, 2.1 qps Successfully wrote 4693 bytes of Json data to 2024-07-26-232250_114_55_5_155_status_201_iZbp1cz9ur77robaiv085tZ.jsonExpected output from test 2:
fortio load -c 10 -qps 10000 -H "user_type:subscriber" -t 30s -timeout 60s -a http://114.55.xx.xx/status/202 ... # target 50% 0.253333 # target 75% 1.875 # target 90% 4.26635 # target 99% 4.47301 # target 99.9% 4.49367 Sockets used: 10 (for perfect keepalive, would be 10) Uniform: false, Jitter: false Code 202 : 250 (100.0 %) Response Header Sizes : count 250 avg 250.264 +/- 0.4408 min 250 max 251 sum 62566 Response Body/Total Sizes : count 250 avg 250.264 +/- 0.4408 min 250 max 251 sum 62566 All done 250 calls (plus 10 warmup) 1226.657 ms avg, 8.0 qps Successfully wrote 4509 bytes of Json data to 2024-07-26-232250_114_55_5_155_status_202_iZbp1cz9ur77robaiv085tZ.jsonThe preceding outputs show that the average request latency of test 2 is about 1/4 times that of test 1, and the QPS is about four times that of test 1. This is because in the previously defined policy, the priority of the requests of the subscriber type is four times that of requests of the guest type. A total of 320 requests are processed within 30 seconds in two tests. Excluding the 20 requests used for warm-up, the request rate received by the service is exactly 10 requests per second. This proves that the requests received by the service are always within the given limit.
References
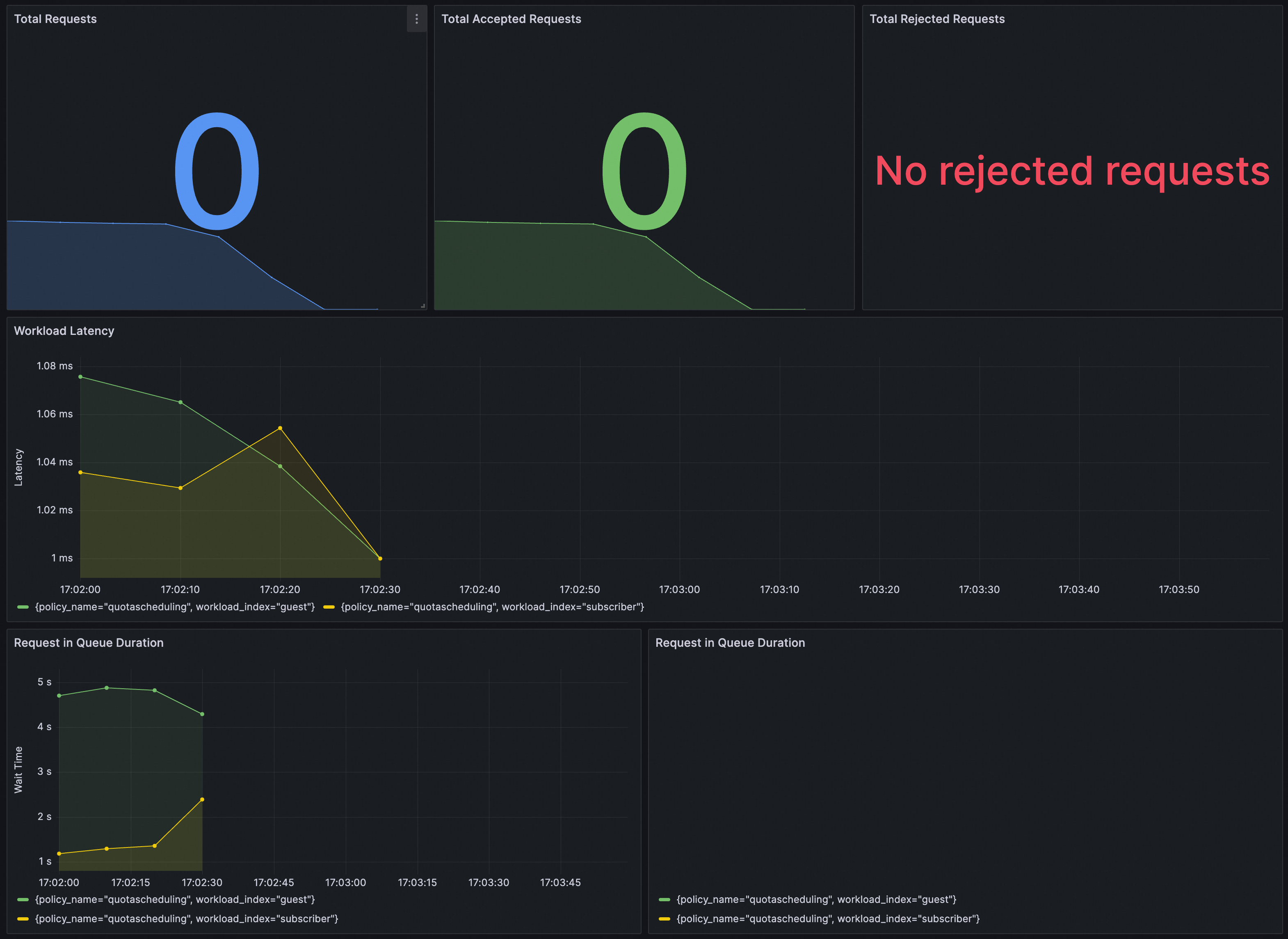
You can verify whether QuotaSchedulingPolicy takes effect on Grafana. You need to ensure that the Prometheus instance for Grafana has been configured with ASM traffic scheduling suite.
You can import the following content into Grafana to create a dashboard for QuotaSchedulingPolicy.
The dashboard is as follows.