If a table is partitioned, the system scans only the partitions that meet specified query conditions, instead of scanning the full table. This improves query performance.
Use partitioned tables
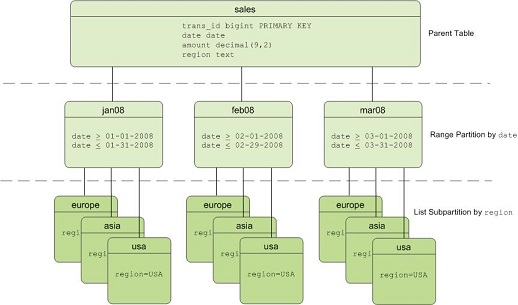
AnalyticDB for PostgreSQL supports range, list, and multi-level partitioned tables. The following figure shows a multi-level partitioned table that has date-based range partitions and region-based list partitions.
Use scenarios
Take note of the following items when you decide whether to partition a table:
Data volumes: We recommend that you use partitioning on tables that contain large volumes of data, such as a fact table that has 10 million data rows. The standard varies based on your experience and query performance.
Partition columns: If a table has a large volume of data and an appropriate partition column such as day or month, you can use partitioning.
Data lifecycle: In most cases, data must be managed in data warehouses based on data lifecycle. You can use partitioned tables to facilitate data management such as deletion of old data.
Query statements: When a table is partitioned, its query performance can be improved only when its partition column is contained in query statements. If query statements that involve no partition columns are executed on the partitioned table, the queries may require a longer period of time to complete because all partitions are scanned.
Create a range partitioned table
You can use AnalyticDB for PostgreSQL to generate partitions by specifying a START value, an END value, and an EVERY clause that defines the partition increment value. By default, START values are inclusive and END values are exclusive. Example:
CREATE TABLE sales (id int, date date, amt decimal(10,2))
DISTRIBUTED BY (id)
PARTITION BY RANGE (date)
( START (date '2016-01-01') INCLUSIVE
END (date '2017-01-01') EXCLUSIVE
EVERY (INTERVAL '1 day') );You can also create a range partitioned table that uses a column of a numeric data type as the partition key. Example:
CREATE TABLE rank (id int, rank int, year int, gender char(1), count int)
DISTRIBUTED BY (id)
PARTITION BY RANGE (year)
( START (2006) END (2016) EVERY (1),
DEFAULT PARTITION extra ); Create a list partitioned table
A list partitioned table can use a column of any data type that allows equality comparisons as the partition key. For list partitions, you must declare a partition specification for each partition (list value) that you want to create. Example:
CREATE TABLE rank (id int, rank int, year int, gender
char(1), count int )
DISTRIBUTED BY (id)
PARTITION BY LIST (gender)
( PARTITION girls VALUES ('F'),
PARTITION boys VALUES ('M'),
DEFAULT PARTITION other );Create a multi-level partitioned table
You can create a table that has multi-level partitions. The following sample statement shows how to create a three-level partitioning table. Data in range partitions is partitioned by month, and data in list partitions is partitioned by region.
CREATE TABLE sales
(id int, year int, month int, day int, region text)
DISTRIBUTED BY (id)
PARTITION BY RANGE (month)
SUBPARTITION BY LIST (region)
SUBPARTITION TEMPLATE (
SUBPARTITION usa VALUES ('usa'),
SUBPARTITION europe VALUES ('europe'),
SUBPARTITION asia VALUES ('asia'),
DEFAULT SUBPARTITION other_regions)
(START (1) END (13) EVERY (1),
DEFAULT PARTITION other_months );Optimize partitioned table queries
Partition granularity
For a table partitioned by time, the granularity can be a day, week, or month. A finer granularity produces a smaller amount of data in each partition but a larger number of partitions. The number of partitions is not measured by an absolute standard. Typically, the number of partitions is considered quite large at around 200. A large number of partitions have a significant impact on database performance. For example, the query optimizer may take a longer time to generate execution plans, and maintenance operations such as VACUUM may slow down.
In a multi-level partitioned table, the number of partitioning files may increase sharply. For example, if a table is partitioned by month and city in a scenario that contains 24 months and 100 cities, the total number of table partitions is 2,400. If the table is a column-oriented table that stores each column in a physical table and the table contains 100 columns, the system must manage more than 100,000 files for the table. You must estimate the number of partitions that are needed when you determine the partitioning method.
Partition pruning
AnalyticDB for PostgreSQL supports partition pruning for partitioned tables. For more information, see Partition pruning.
Maintain partitioned tables
In partitioned tables, partitions can be managed by using various SQL statements. Examples:
Create a partition
If a default partition exists, you cannot create partitions. However, you can split the default partition.
ALTER TABLE test_partition_range ADD partition p2 start ('2017-02-01') end ('2017-02-28');Delete a partition and its subpartitions
ALTER TABLE test_partition_range DROP partition p2;Rename a partition
ALTER TABLE test_partition_range RENAME PARTITION p2 TO Feb17;Clear a partition
ALTER TABLE test_range_partition TRUNCATE PARTITION p1;Exchange a partition
ALTER TABLE test_range_partition EXCHANGE PARTITION p2 WITH TABLE {cos_table_name} ;Split a partition
-- Split the p2 partition into two partitions with the boundary value set to 2017-02-20. ALTER TABLE test_partition_range SPLIT partition p2 at ('2017-02-20') into (partition p2, partition p3);