This topic describes the high availability of Classic Load Balancer (CLB). CLB is designed to deliver highly available services. You can use CLB in concert with Alibaba Cloud DNS to implement cross-region disaster recovery. CLB is designed to offer a multi-zone service availability of 99.95% and a single-zone service availability of 99.90%.
High availability architecture
CLB instances are deployed in clusters to synchronize sessions and mitigate the effects of single points of failure (SPOFs). This improves redundancy and ensures service stability. Layer 4 CLB uses the open source Linux Virtual Server (LVS) software and Keepalived framework to balance loads, whereas Layer 7 CLB uses Tengine to balance loads. Tengine is a web server project developed by Taobao. Built on top of NGINX, Tengine provides various advanced features that are designed for high-traffic websites.
Requests from the Internet are routed to an LVS cluster based on the Equal-cost Multi-path (ECMP) mechanism. Each physical server in an LVS cluster uses multicast packets to synchronize sessions across the cluster. Furthermore, the LVS cluster performs constant health checks on the Tengine cluster and removes unhealthy servers from the Tengine cluster to ensure the availability of Layer 7 CLB.
Best practice:
Session synchronization is a suitable solution to prevent persistent connections from being affected by server failures. However, this solution does not solve this issue for short-lived connections. Such incidents also happen when a connection does not trigger the session synchronization mechanism because the three-way handshake fails. To prevent session interruptions caused by server failures within a cluster, you can add a retry mechanism to your CLB instances. This reduces the impact of server failures on user access.
Single CLB instance
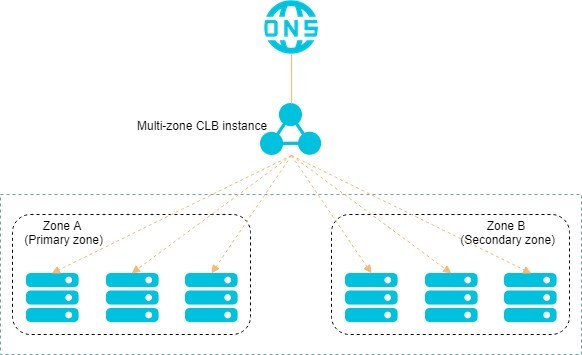
To provide more stable and reliable load balancing services, CLB supports cross-zone deployment in most regions to achieve cross-data-center disaster recovery. You can deploy a CLB instance across two zones within the same region whereby one zone functions as the primary zone and the other functions as the secondary zone. When the primary zone fails or has no healthy ECS instances, the CLB instance can automatically fail over services to the secondary zone within 30 seconds. When the primary zone recovers, the CLB instance automatically switches services back to the primary zone.
Zone-disaster recovery is implemented between primary and secondary zones. CLB implements failovers only when the entire CLB cluster within the primary zone is completely unavailable. These situations may arise due to factors such as power outages or lost connectivity to the primary zone. A failover is not triggered when a single instance in the primary zone fails.
Best practice:
We recommend that you create CLB instances in regions that support primary/secondary zone deployment to improve the disaster tolerance of your applications.
You can determine the primary and secondary zones for a CLB instance based on the distribution of Elastic Compute Service (ECS) instances. Select the zone where most ECS instances are deployed as the primary zone to minimize access latency.
However, we recommend that you do not deploy all ECS instances in the primary zone, but instead deploy a small number of ECS instances in the secondary zone. This way, requests can be redirected to ECS instances in the secondary zone when the primary zone fails.
Multiple CLB instances
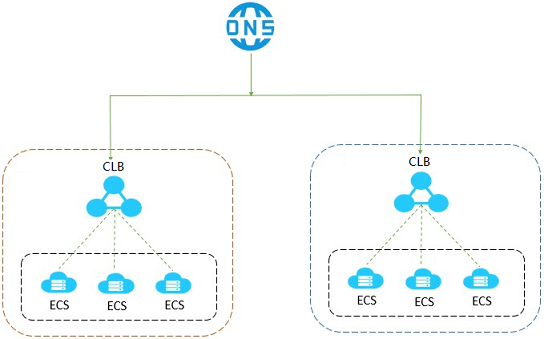
If availability is a crucial component of your business, we recommend that you deploy multiple CLB instances. In cases where a CLB instance becomes unavailable due to network attacks or improper configurations, failovers cannot be triggered because the CLB instance is no longer available. To avoid such incidents, you can create multiple CLB instances. Then, use Alibaba Cloud DNS to schedule requests to achieve cross-region backup and disaster recovery.
Best practice:
You can deploy CLB instances and ECS instances in multiple zones within a region or across multiple regions, and schedule requests by using Alibaba Cloud DNS.
High availability of backend ECS instances
CLB performs health checks to monitor the availability of backend ECS instances. The health check feature improves service availability and reduces the impact of backend server failures on the availability of your applications.
When the health check feature is enabled, CLB distributes new requests to healthy ECS instances whenever unhealthy instances are detected. After the unhealthy instances recover, CLB automatically resumes sending requests to the instances. For more information, see Health check overview.
Best practice:
To perform health checks, you must make sure that the health check feature is enabled and properly configured. For more information, see Configure and manage health checks.