JindoFS is a Hadoop-compatible file system (HCFS) built for open source big data ecosystems based on Alibaba Cloud Object Storage Service (OSS). JindoFS provides three storage modes to store data in OSS: client-only mode (SDK), cache mode, and block storage mode. JindoFS in client-only mode or cache mode optimizes the access to OSS from computing engines of Hadoop and Spark ecosystems. JindoFS in block storage mode provides a tremendous storage capacity by using OSS as the storage backend and supports efficient metadata queries.
Client-only mode (SDK)
Cache mode
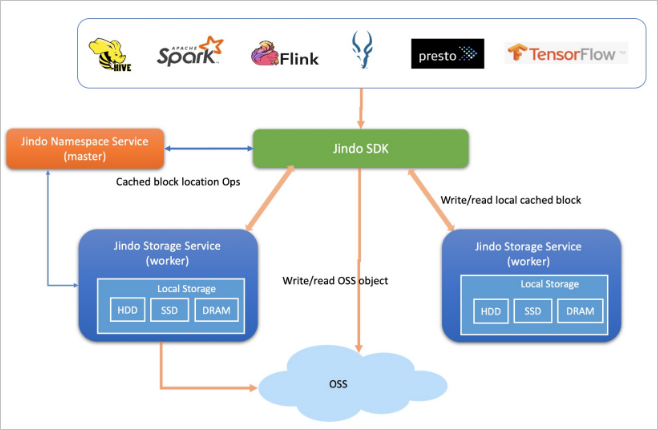
Block storage mode
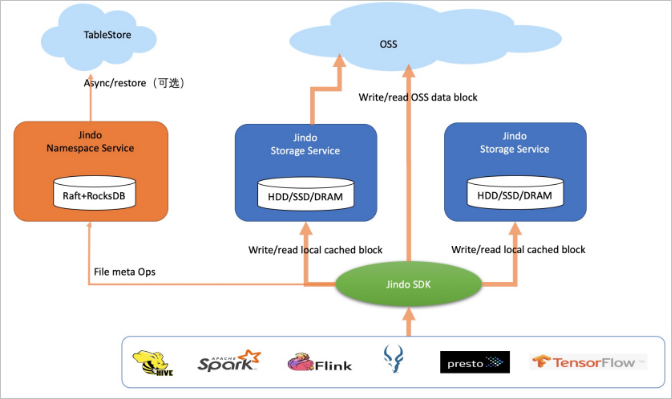
Comparison between the cache mode and block storage mode
Both modes allow JindoFS to store data in OSS and determine whether to cache the data in local clusters to accelerate data access based on the usage of local storage space.
The essential difference between the two modes lies in the file storage methods in OSS. JindoFS in block storage mode manages directories and file metadata and stores files as blocks in OSS. JindoFS in cache mode stores files as objects in OSS.
Comparison among the three modes
The following table describes the three modes in multiple dimensions.
| Dimension | Client-only mode (SDK) | Cache mode | Block storage mode |
|---|---|---|---|
| Storage cost |
|
|
|
| Scalability | High | Relatively high | Medium |
| Throughput | Depends on the bandwidth occupied by OSS. | Depends on the bandwidth occupied by OSS and the bandwidth consumed for caching hot data. | Depends on the bandwidth occupied by OSS and the bandwidth consumed for caching warm data and hot data. |
| Metadata |
|
|
|
| Maintenance workload | Low | Medium
Requires the O&M of the cache system. |
Relatively high
Requires the O&M of the Namespace Service and Storage Service. |
| Security |
|
|
|
| Usage | Only allows you to specify an OSS directory in the oss://<oss_bucket>/<oss_dir>/ format to access files. Cross-service access to the OSS directory is supported. |
Note For more information about how to use JindoFS in cache mode, see the documentation
of JindoFS in cache mode.
|
Only allows you to specify a JindoFS directory in the jfs://<your_namespace>/<path_of_file> format for one of the deployed namespaces to access data. Cross-service access to
the JindoFS directory is not supported. The caching feature can be enabled.
Note For more information about how to use JindoFS in block storage mode, see the documentation
of JindoFS in block storage mode.
|
FAQ
- Q: What mode is recommended for typical data lake scenarios?
A: The client-only mode (SDK) and the cache mode are fully compatible with object storage semantics of OSS and provide complete compute-storage separation and flexible scalability. We recommend that you use the client-only mode (SDK) or the cache mode for big data analysis and AI training acceleration in typical data lake scenarios.
- Q: Why does JindoFS in block storage mode provide higher performance than HDFS?
A:
- JindoFS in block storage mode can process more than 1 billion files. However, HDFS can process only a maximum of 0.4 billion files. In addition, the performance of JindoFS in block storage mode is more stable at peak hours of cluster business.
- JindoFS in block storage mode has no limits on on-heap memory in Java and memory usage and can process data at a larger scale than HDFS. HDFS has limits on on-heap memory in Java.
- JindoFS in block storage mode requires lightweight O&M. You do not need to worry about damaged disks or anomalous nodes. Data has one backup on OSS, and nodes can be connected or disconnected.
- JindoFS in block storage mode can transparently compress and archive cold data. It uses various means to optimize costs and connects to OSS to support exabytes of data.
- JindoFS in block storage mode supports some important features of HDFS, such as HDFS AuditLog, integration with Ranger, and data encryption.
- Q: What are the special advantages of JindoFS in block storage mode?
A:
- JindoFS in block storage mode can manage file metadata and organize file data. Therefore, it can fully meet the requirements of various big data engines on storage interfaces. These interfaces include but are not limited to the interface to implement the atomicity and transaction processing of rename operations, the interface to implement high-performance local data writing, the interface to implement transparent compression, and the truncate, append, flush, sync, and snapshot interfaces. These high-level storage interfaces are required to achieve complete POSIX and are used to connect more big data engines, such as Flink, HBase, Kafka, and Kudu, to OSS. JindoFS in client-only mode (SDK) or JindoFS in cache mode can also use some interfaces to access OSS. However, the capabilities and advantages of these two modes are insufficient.
- The block storage mode is more cost-effective than the other two modes. This is because in block storage mode, warm data and hot data, which account for 60% of the total amount of data, are cached in local clusters. Therefore, you can read a large amount of data from your local cluster instead of OSS.