Synchronize data to MaxCompute
Preparations
1.Create a MaxCompute table
DataHub allows you to synchronize data to MaxCompute tables. Both partitioned and non-partitioned tables are supported. To facilitate data processing in MaxCompute, we recommend that you synchronize data to partitioned tables.
DataHub allows you to synchronize data from the topics of the TUPLE or BLOB type to MaxCompute tables.
(1) If you want to synchronize data from topics of the TUPLE type, data types in MaxCompute tables must match data types in the DataHub topics. The following table describes the data type mappings.
MaxCompute | DataHub |
BIGINT | BIGINT |
STRING | STRING |
BOOLEAN | BOOLEAN |
DOUBLE | DOUBLE |
DATETIME | TIMESTAMP |
DECIMAL | DECIMAL |
TINYINT | TINIINT |
SMALLINT | SMALLINT |
INT | INTEGER |
FLOAT | FLOAT |
MAP | Not supported |
ARRAY | Not supported |
DataHub does not support all data types in MaxCompute. We recommend that you create a MaxCompute schema based on data types supported by DataHub.
(2) If you want to synchronize data from topics of the BLOB type, the MaxCompute schema needs to contain only one field of the STRING type. By default, DataHub synchronizes data to this field.
DataHub | MaxCompute |
BLOB | STRING |
(3) To facilitate data tracking and troubleshooting, we recommend that you add the __rowkey__ field of the SRTING type when you create a MaxCompute schema. DataHub automatically synchronizes the trace information of the synchronized data in DataHub to this field to facilitate subsequent data troubleshooting.
2.Prepare an account for data synchronization that is granted required permissions
(1) When you create a DataConnector to synchronize data to MaxCompute, you must manually enter the account information that is used to access the MaxCompute table. Make sure that the entered account information is valid. In most cases, you can use a RAM user for MaxCompute.
(2) You must grant the account the required permissions on the MaxCompute table. The permissions include the CreateInstance, Describe, Alter, and Update permissions.
You can manage the permissions on MaxCompute tables in the DataWorks console. For more information, see Configure MaxCompute. You can also use the command-line tool of MaxCompute for authorization.
3.Determine the value of the TimestampUnit parameter.
(1) The TimestampUnit parameter specifies the unit in which the data of the TIMESTAMP type is converted and written to the fields of the DATETIME type in MaxCompute.
(2) If you want the fields of the TIMESTAMP type to be written to MaxCompute in the unit of seconds, select SECOND from the TimestampUnit drop-down list when you create a DataConnector. If you want the fields of the TIMESTAMP type to be written to MaxCompute in the unit of milliseconds, select MILLISECOND. If you want the fields of the TIMESTAMP type to be written to MaxCompute in the unit of microseconds, select MICROSECOND.
Usage notes
More partitions cause slower data synchronization from DataHub due to the current writing standards of MaxCompute. When you create a DataConnector to synchronize data to MaxCompute, we recommend that you limit the number of partitions, especially in
USER_DEFINEmode.Make sure that the timestamps of the records in a shard and the shards are as continuous as possible.
Do not create excessive partitions when you create partitions in all partition modes.
Create a DataConnector
In the left-side navigation pane of the DataHub console, click Project Manager. On the Project List page, find a project and click View in the Actions column. On the details page of the project, find a topic and click View in the Actions column.
Click the synchronization button
+Connectorin the upper right corner to create a synchronization task
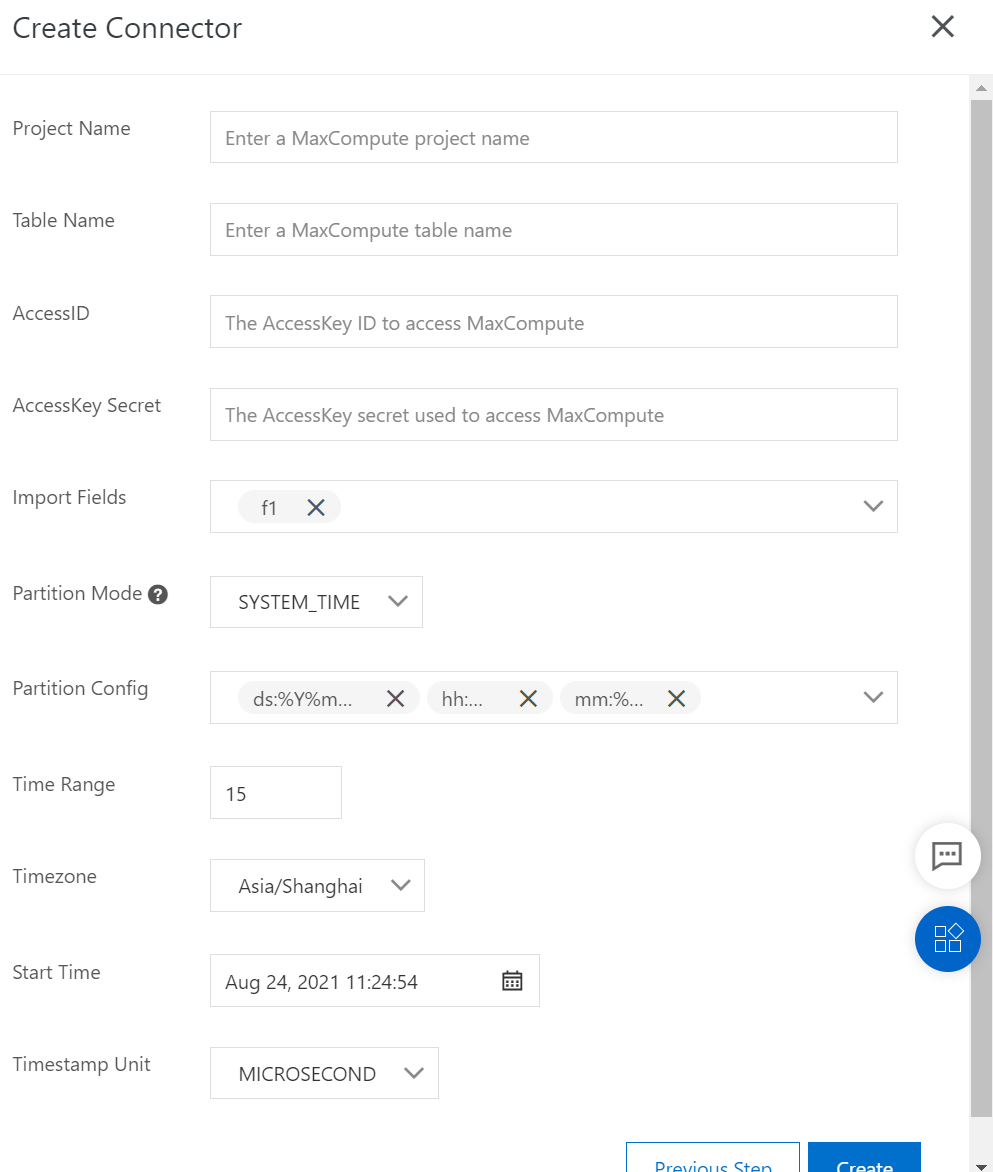
In the Create Connector panel, click MaxCompute, as shown in the following figure.
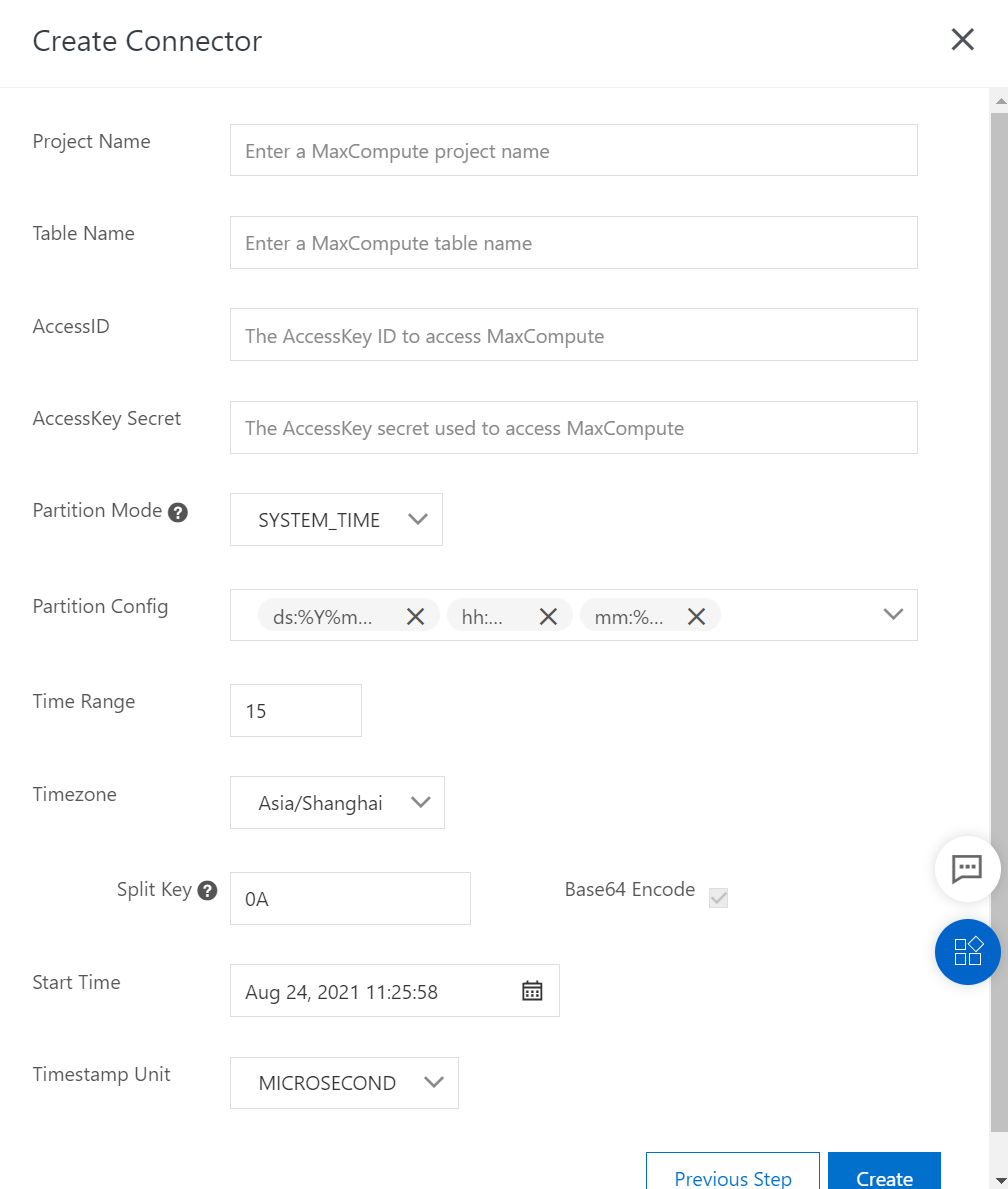
(2) Synchronize data from a topic of the BLOB type
Description of a few parameters:
The following part describes a few parameters that are used to create a DataConnector in the DataHub console. For more information about synchronization configurations, see the descriptions of DataHub SDKs.
Import Fields
DataHub can synchronize the values of specific fields to MaxCompute tables based on your settings.
Partition Mode
The partition mode determines to which partition in MaxCompute data is written. The following table describes the partition modes supported by DataHub.
Partition mode | Partition basis | Supported data type of a topic | Description |
USER_DEFINE | Value of the partition field that has the same name as the partition field in MaxCompute in the record | TUPLE | (1). The DataHub schema must contain the partition field in MaxCompute. (2) The value of this field must be a |
SYSTEM_TIME | Time when the record is written to DataHub | TUPLE or BLOB | (1). Set the time format for MaxCompute partitions in the partition configurations. (2) Specify the time zone. |
EVENT_TIME | Value of the | TUPLE | (1). Set the time format for MaxCompute partitions in the partition configurations. (2) Specify the time zone. |
META_TIME | Value of the | TUPLE / BLOB | (1). Set the time format for MaxCompute partitions in the partition configurations. (2) Specify the time zone. |
SYSTEM_TIME, EVENT_TIME, and META_TIME are the partition modes in which data to be synchronized is partitioned based on the timestamp and time zone configurations. The default unit is microseconds.
Partition Config: the timestamp configurations based on which data to be synchronized is partitioned. DataHub supports the fixed time formats in MaxCompute. The following table describes the fixed time formats and corresponding partitions.
Partition | Time format | Description |
ds | %Y%m%d | day |
hh | %H | hour |
mm | %M | minute |
Time Range: the interval of a partition when the data is partitioned based on the timestamps. Valid values:
15 to 1440. Unit: minutes. A value of 1440 indicates one day. The step size of the parameter is15 minutes.Timezone: the time zone of the timestamps based on which data is partitioned and written to MaxCompute.
Split Key: When you create a DataConnector to synchronize data of the BLOB type, you can specify a hexadecimal delimiter to split the data of the BLOB type and synchronize the data to MaxCompute. For example,
0Aindicates aline feed (\n)Base64 Encode: By default, data of the BLOB type in DataHub is binary data, and the mapped field in MaxCompute is of the STRING type. Therefore, when you create a DataConnector in the DataHub console, Base64 encoding is performed before synchronization by default. You can use DataHub SDKs to meet more customization requirements.
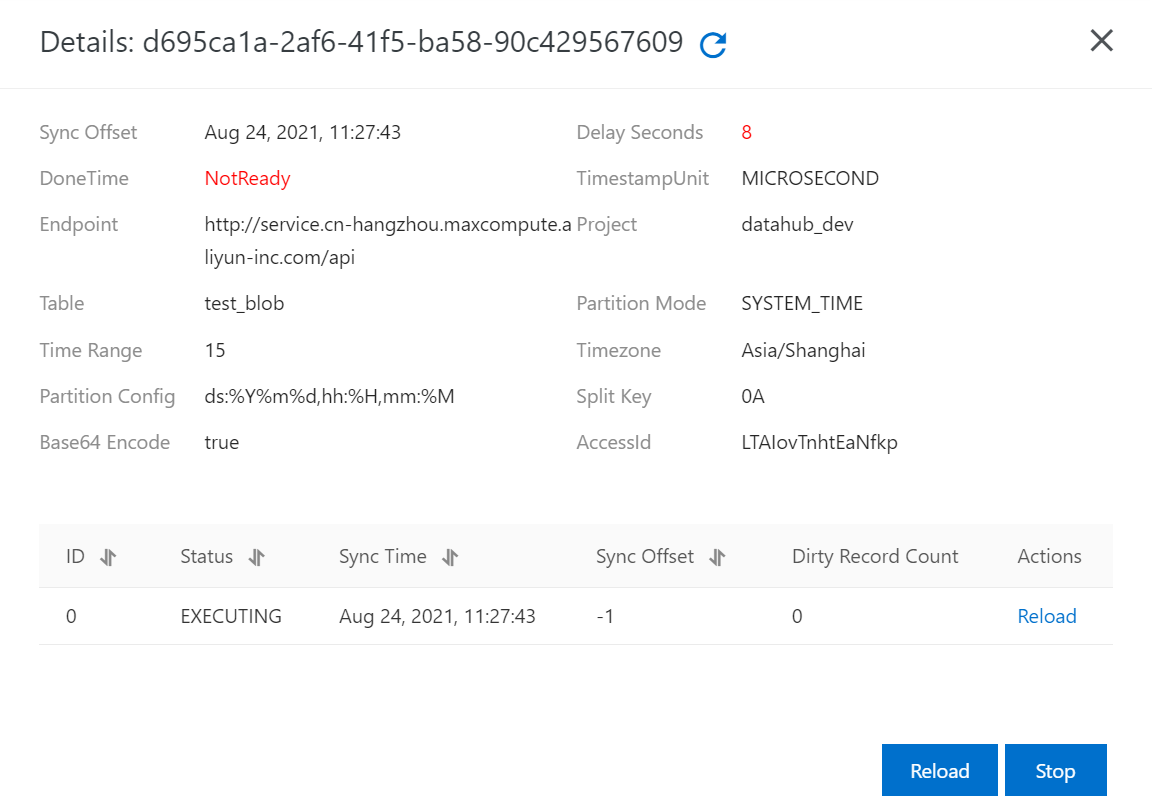
View a DataConnector
Exa
mple
1. USER_DEFINE mode
Create a DataHub topic.
Note: The schema of the topic must contain the partition fields in MaxCompute, and the fields are of the STRING type, as shown in the following figure.
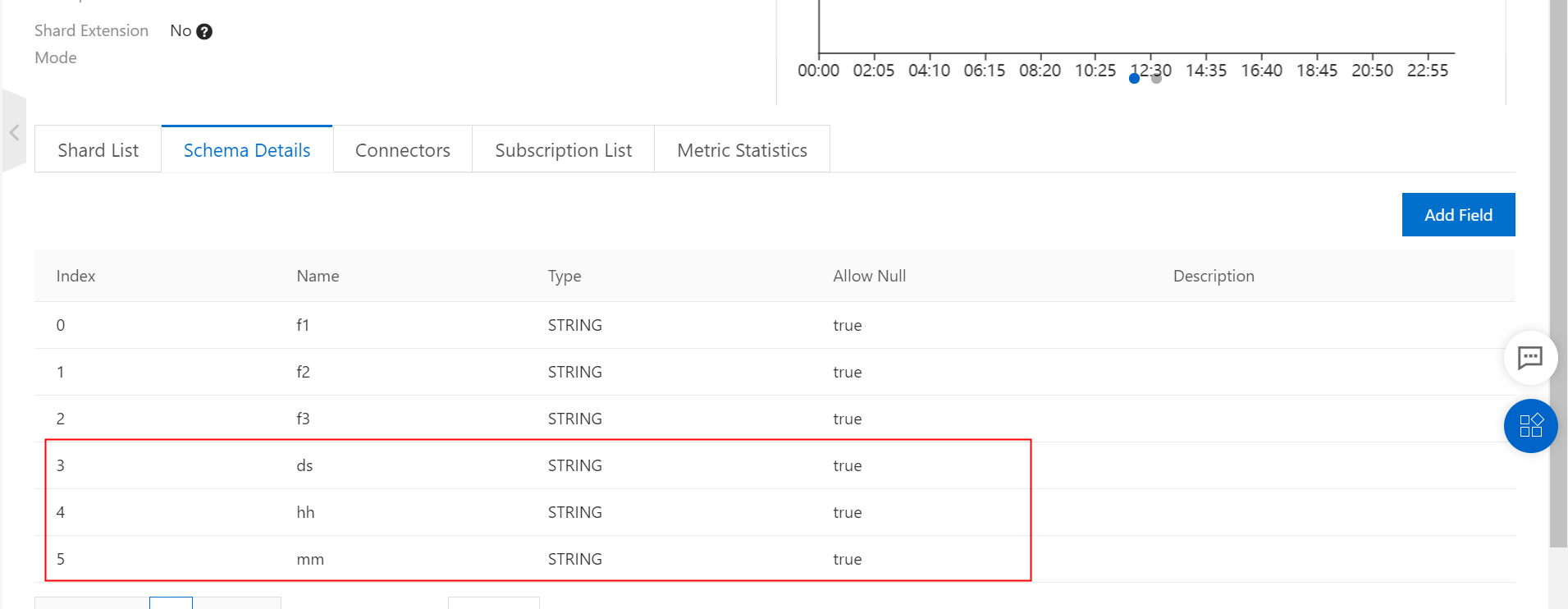
Write data to the DataHub topic. You can use a DataHub SDK to write the data.
During the test, use a DataHub SDK to write multiple records. The values of [ds,hh,mm] are [20210304,01,15] and [20210304,02,15]. The following figure shows the records.
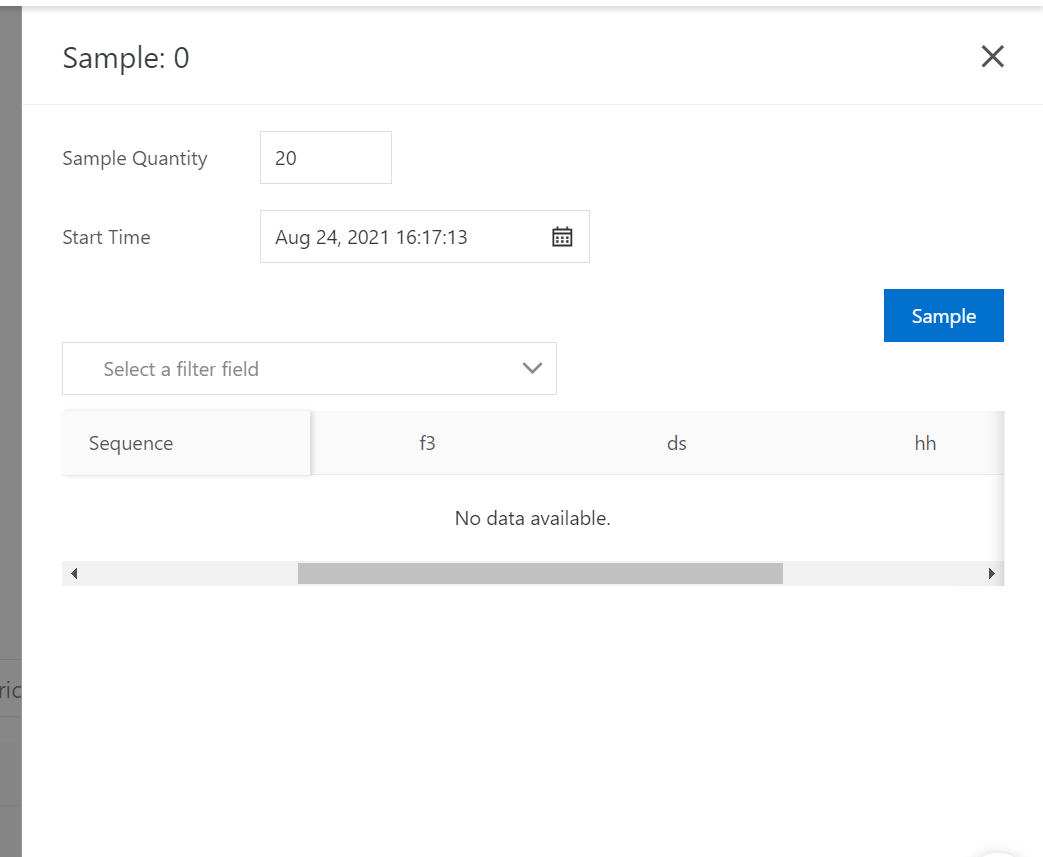
3. Create a DataConnector.
In USER_DEFINE mode, you can configure the partition fields when you create a DataConnector. If no available MaxCompute table exists, a table is automatically created.
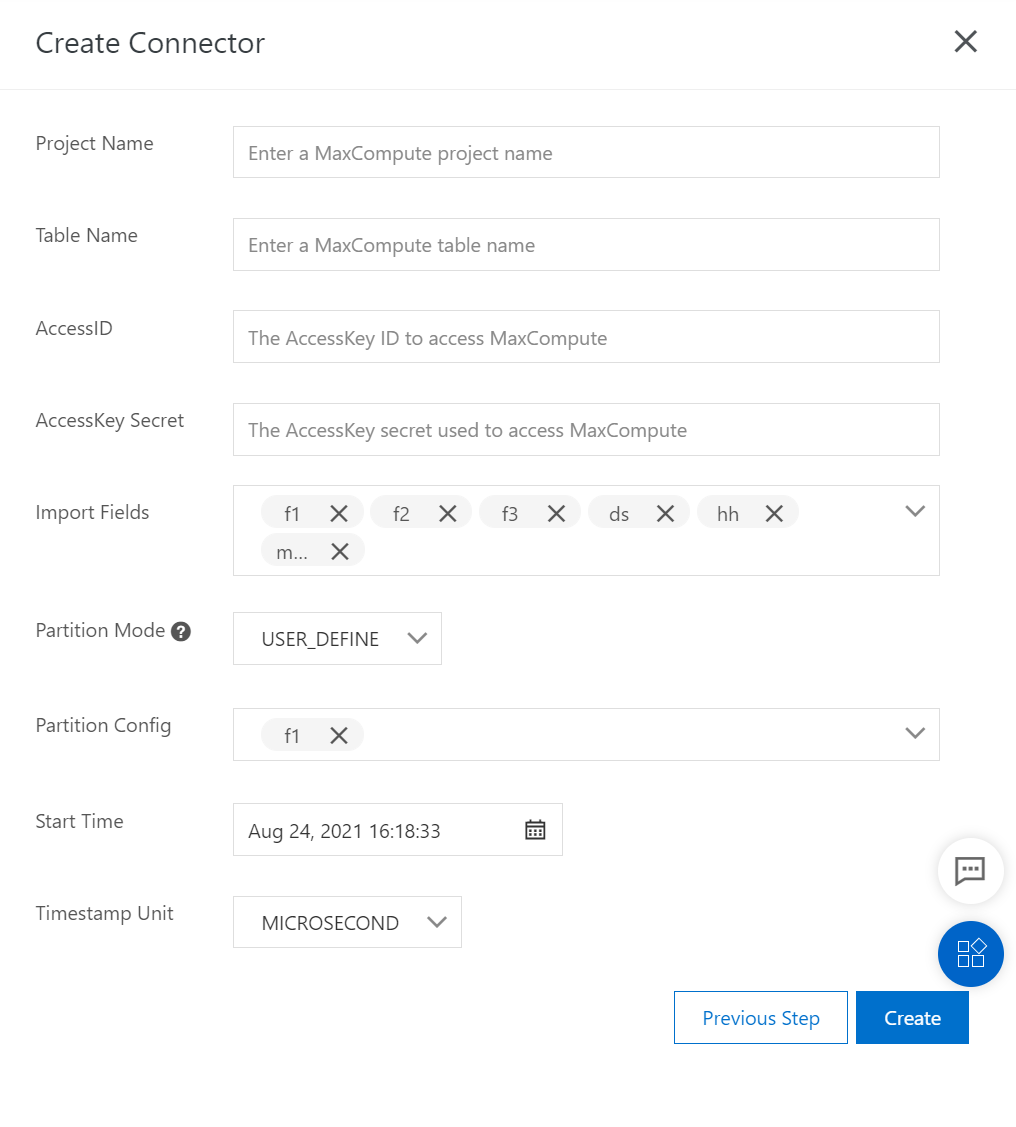
In this example, the fields to be imported are the f1 and f2 fields. The f3 field is not synchronized.
4. Verify the synchronized data.
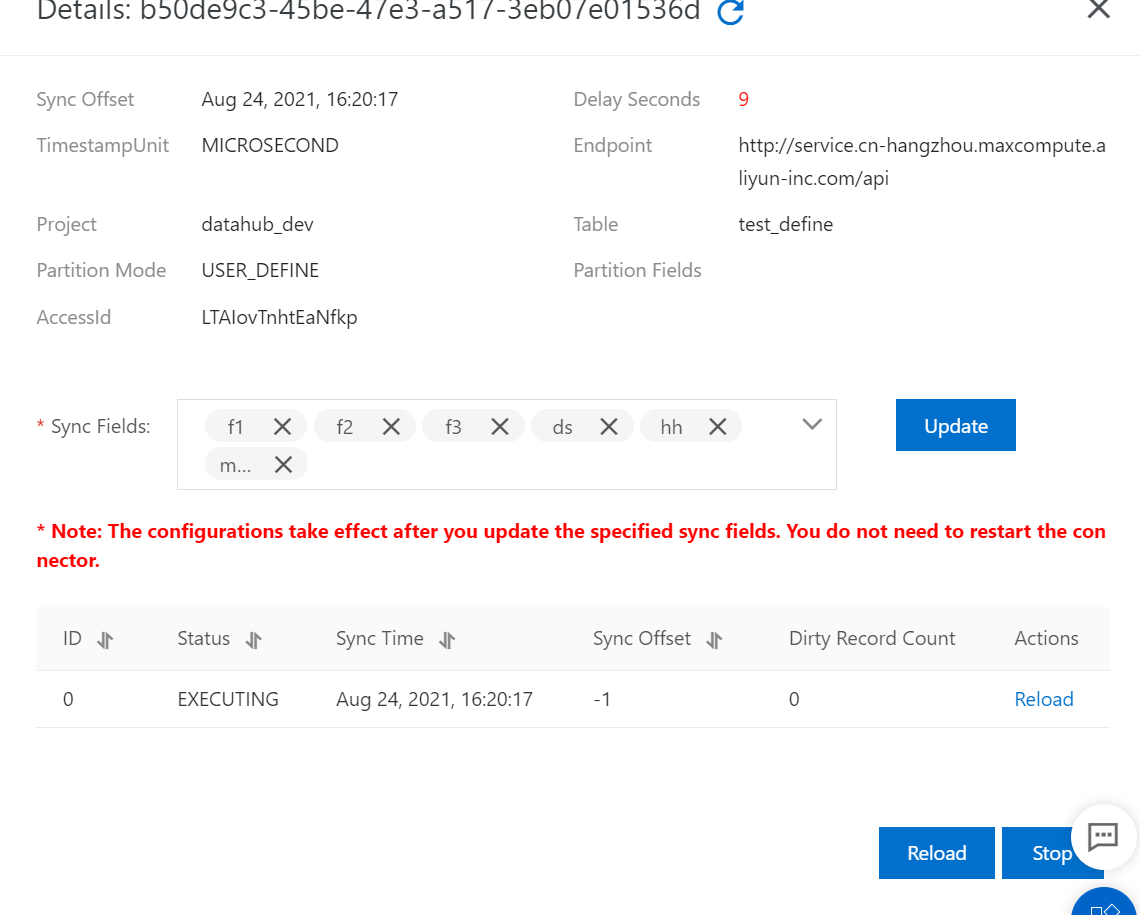
Query data in the MaxCompute table. The following figure shows the query result.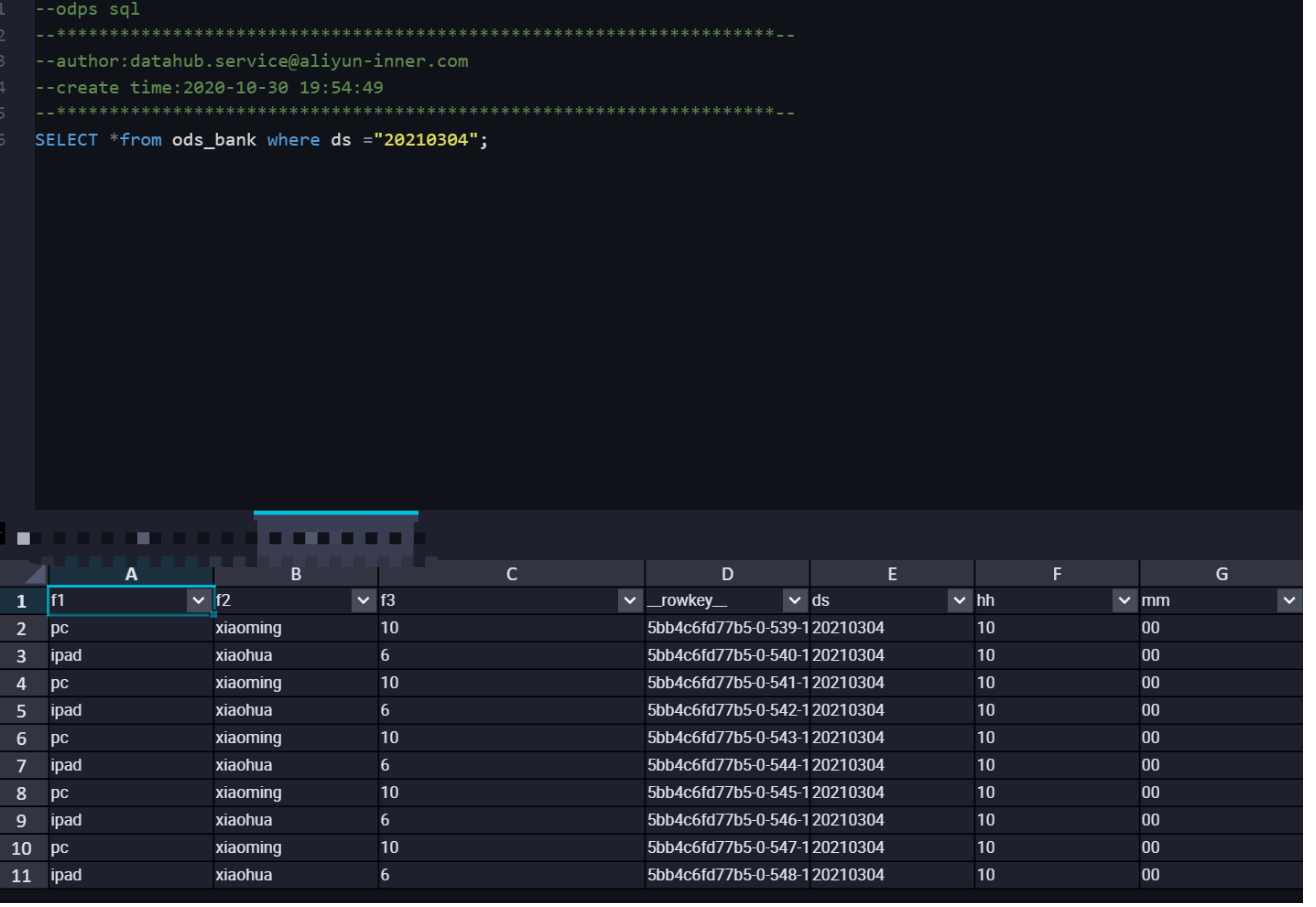
In USER_DEFINE mode, DataHub synchronizes data from DataHub to the corresponding partition based on the value of the partition field in MaxCompute.
2. SYSTEM_TIME mode
Create a DataHub topic.
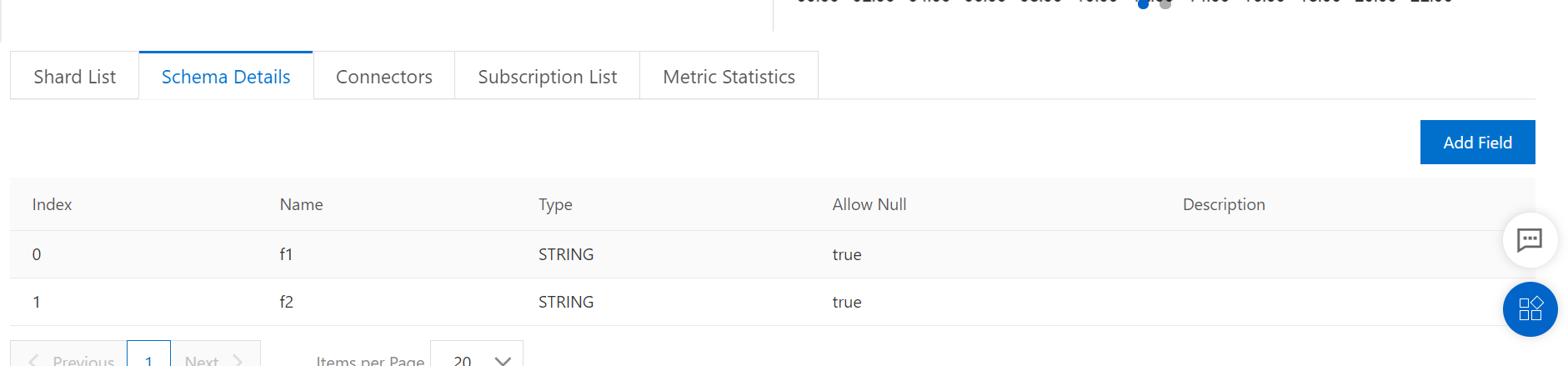
Note: The partition to which data is written is determined based on the time when data is written to DataHub. Therefore, the topic schema needs to contain only data fields and does not need to contain partition fields, as shown in the following figure.
Write data to the DataHub topic. You can use a DataHub SDK to write the data.
During the test, use a DataHub SDK to write multiple records. The time when the data is written to DataHub is
2021-03-04 14:02:45. The following figure shows the records.
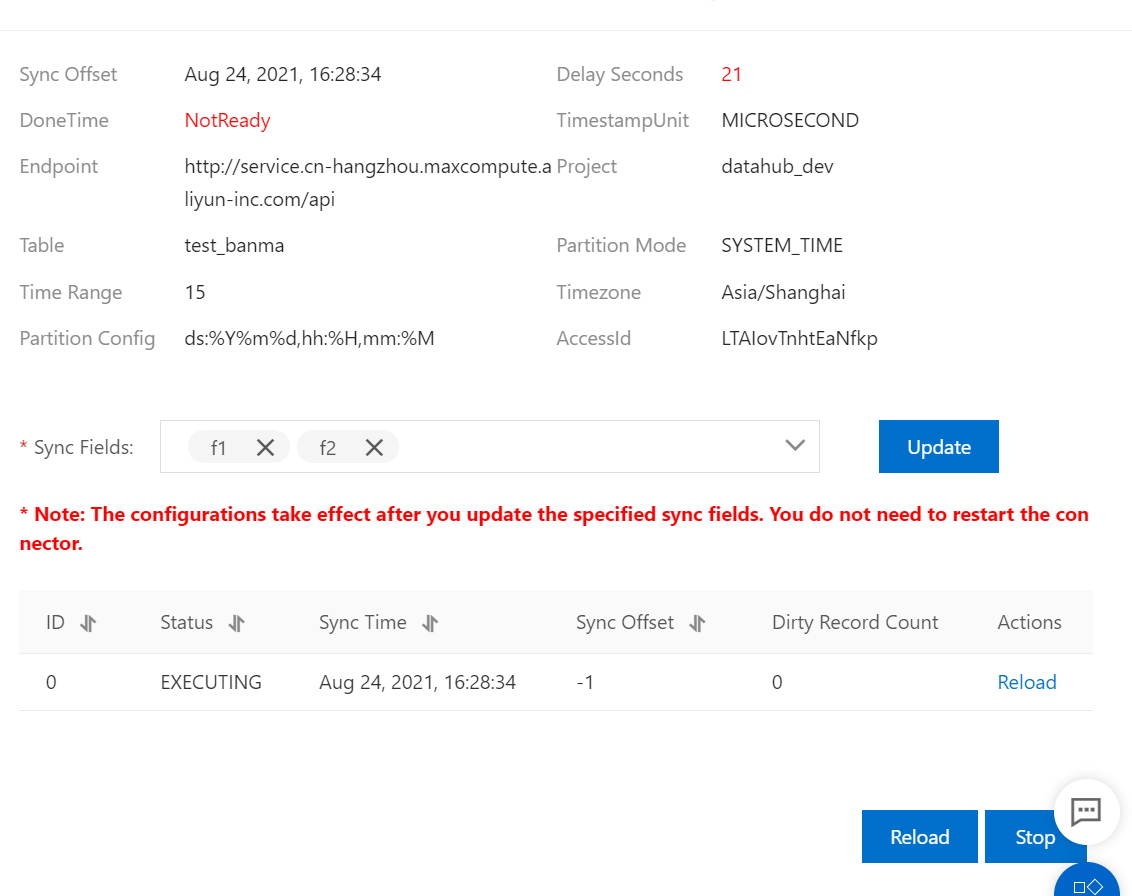
Create a DataConnector.
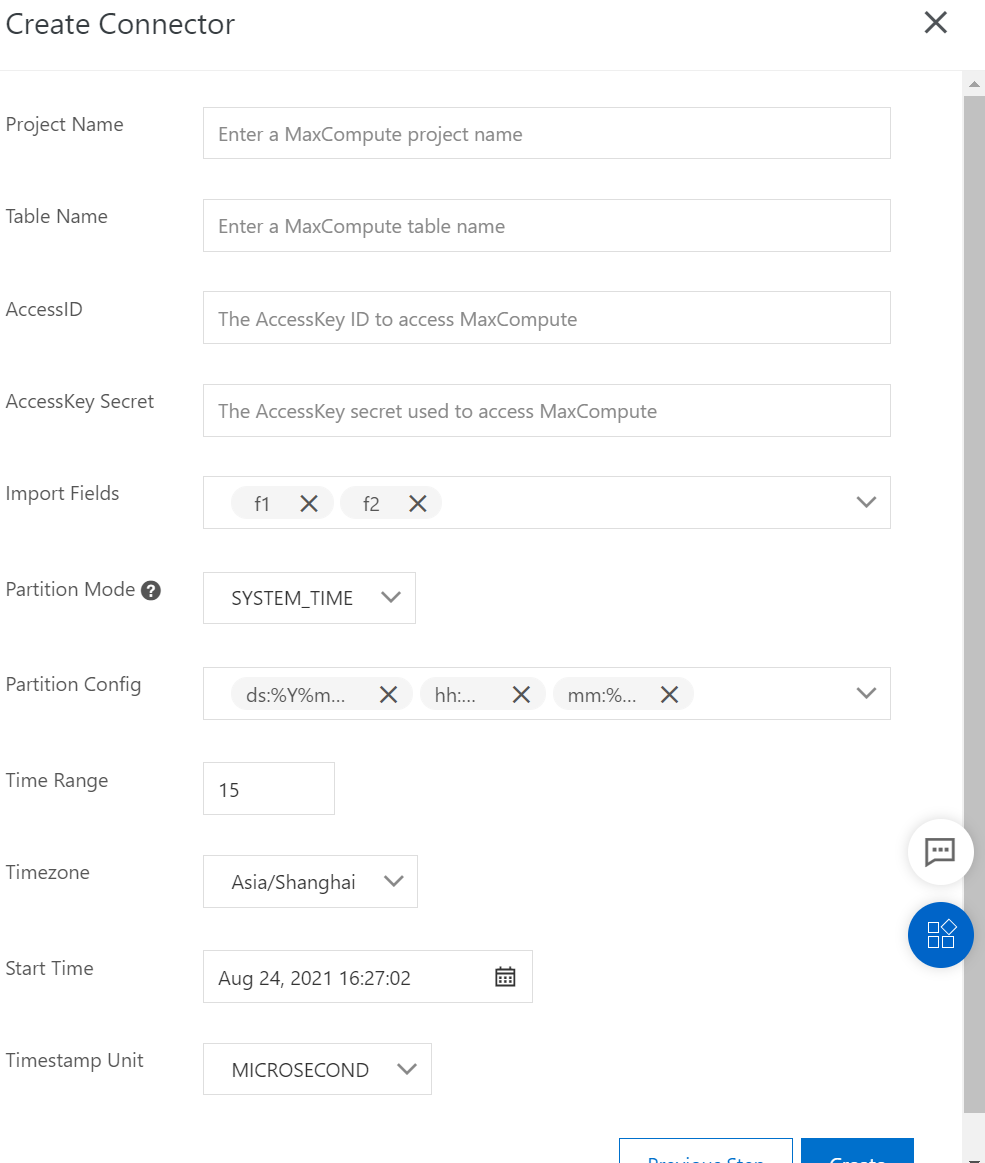
4. Verify the synchronized data.
You can view the synchronization information of the DataConnector in the DataHub console, such as DoneTime.
Query data in the MaxCompute table. The following figure shows the query result.
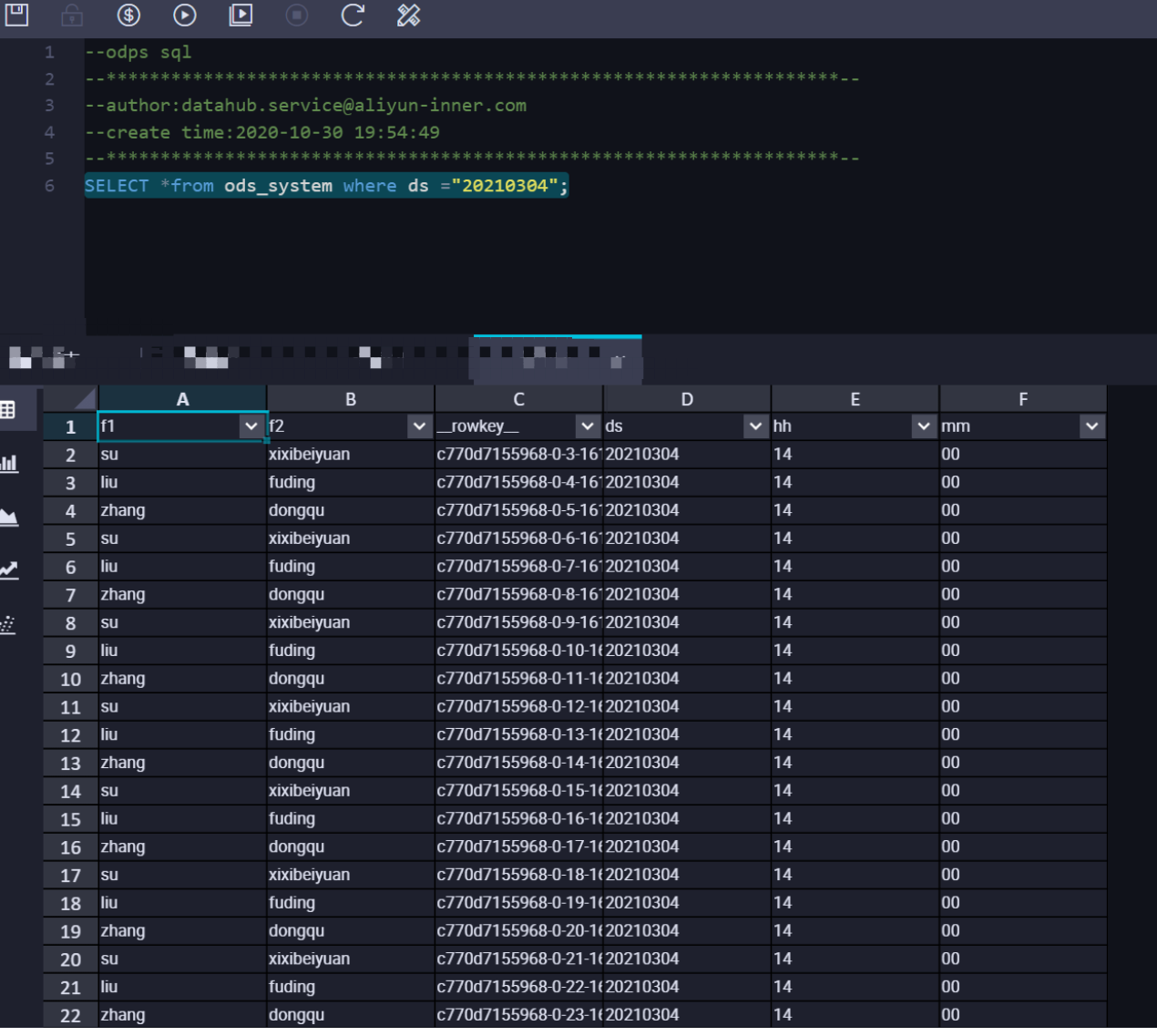
In SYSTEM_TIME mode, DataHub synchronizes data from DataHub to the corresponding partition based on the time when data was written to DataHub.
FAQ
Issue: The timestamp for data synchronization to MaxCompute changes to 1970-01-19.
Cause: The default unit of the timestamp for data synchronization from DataHub to MaxCompute is microseconds, and the unit of the timestamp when data was written to DataHub is milliseconds. Solution: Use microseconds for the unit of the timestamp when data is written to DataHub.