This article introduces the Data Integration function of Dataworks to realize the Data Transport from OpenTSDB to TSDB.
Background information
This topic describes how to migrate data from OpenTSDB to Time Series Database (TSDB) by using the Data Integration service of DataWorks.
DataWorks is an important platform as a service (PaaS) of Alibaba Cloud. It offers a wide range of services, including data Aggregation, data development, dataService studio, DataAnalysis, and data governance. DataWorks also provides a one-stop data development and management console, which helps enterprises implement data mining and unlock the full potential of valuable data. The data development service of DataWorks is used in the data migration process in this topic. If you are new to DataWorks, see the DataWorks documentation for more information.
Currently, DataWorks supports migrating data from the following types of data sources to TSDB: TSDB, OpenTSDB, Prometheus, InfluxDB, and MySQL.
Quick Start
Step 1: Ingress
Log on to the DataWorks console. If no workspaces are available in the console, you must create a workspace.
Step 2: Create a sync node on the DataStudio page
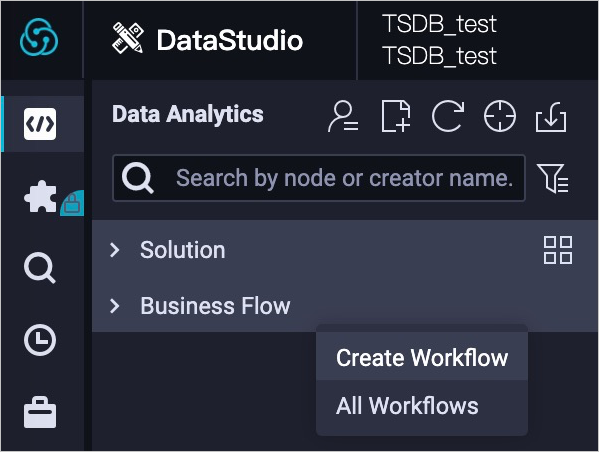
In the upper-left corner of the page, right-click Business Flow, and then click Create Workflow. Figure 1 shows the position of the Create Workflow option.
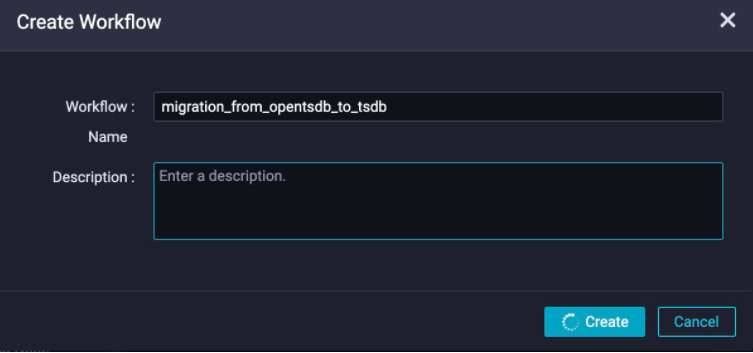
 In the dialog box that appears, enter a workflow name, for example,
In the dialog box that appears, enter a workflow name, for example, migration_from_opentsdb_to_tsdb. Figure 2 shows the dialog box where you can create a workflow.
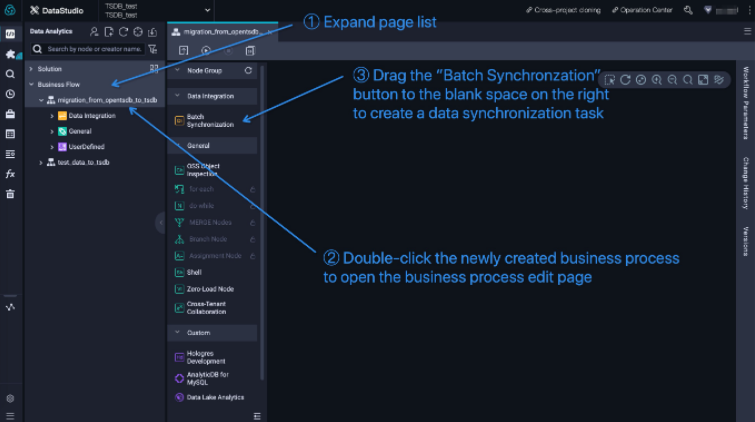
 Follow the three steps in Figure 3 to create the data synchronization task:
Follow the three steps in Figure 3 to create the data synchronization task:
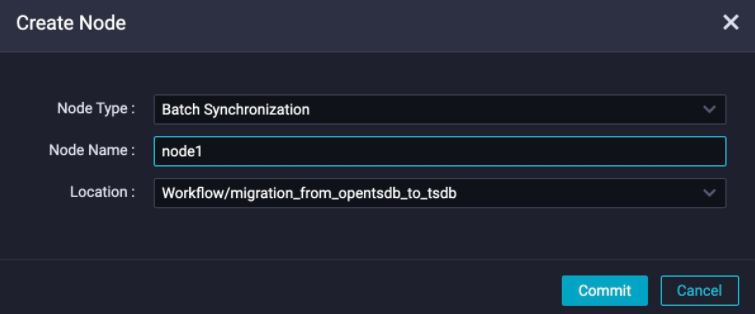
 In the dialog box that appears, enter a name for the sync node, for example,
In the dialog box that appears, enter a name for the sync node, for example, node1. Figure 4 shows the dialog box where you can create a node.
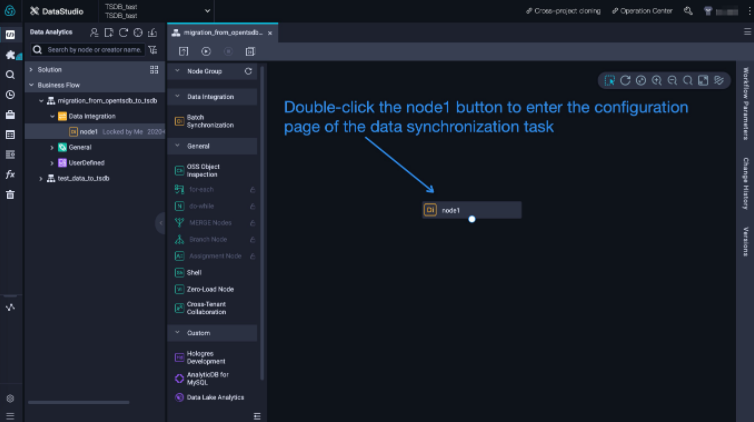
 After the sync node is created,
After the sync node is created, node1 is displayed in the blank section on the right of the page. Double-click node1. On the page that appears, configure the sync node. Figure 5 shows the page where the node is displayed.
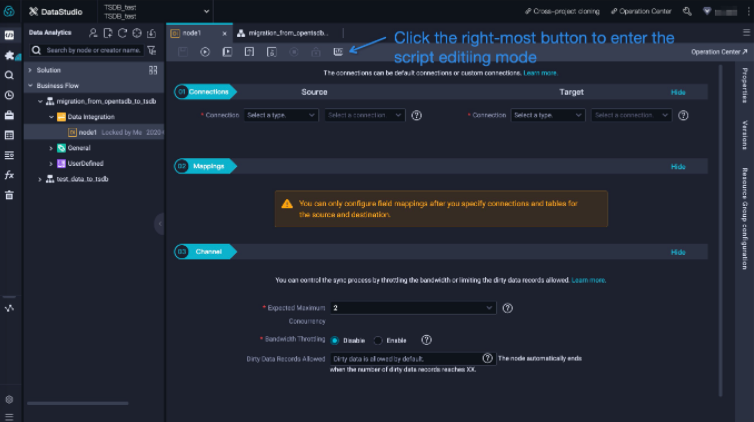
 By default, the sync node
By default, the sync node node1 is configured based on the codeless UI. If you want to configure the node by using the code editor, you can click the rightmost icon in the top toolbar. Figure 6 shows the page where you can configure the node.
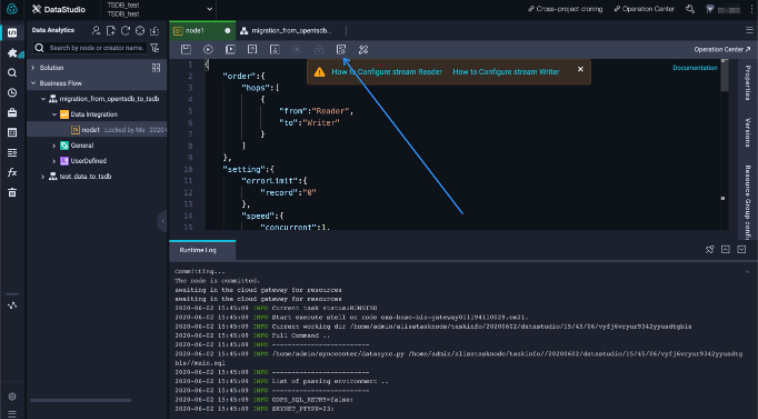
 The default sync node synchronizes data from Stream Reader to Stream Writer. Stream Reader is the source that generates random strings, and Stream Writer is the target that receives and prints the generated random strings. For more information about how to configure Stream Reader and Stream Writer, click the corresponding topics at the top of the page.
The default sync node synchronizes data from Stream Reader to Stream Writer. Stream Reader is the source that generates random strings, and Stream Writer is the target that receives and prints the generated random strings. For more information about how to configure Stream Reader and Stream Writer, click the corresponding topics at the top of the page.
Stream Reader and Stream Writer can synchronize data without depending on external resources. To run the sync node, you can click the Run icon in the upper-left corner. Then, you can view the execution process in the section that appears at the bottom of the page.
Step 3: Modify the configuration
Change the configurations of the default sync node to migrate data from OpenTSDB to TSDB.
Click ![]() to import a configuration template. Figure 7 shows the position of the icon that you must click.
to import a configuration template. Figure 7 shows the position of the icon that you must click.
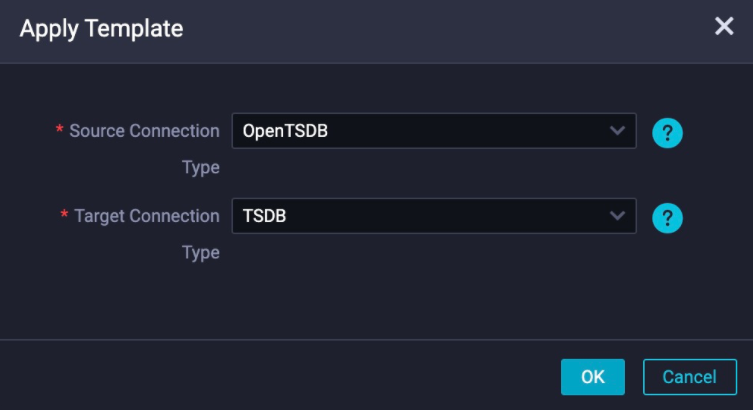
 In the dialog box that appears, set the source connection type to
In the dialog box that appears, set the source connection type to OpenTSDB and the target connection type to TSDB. Figure 8 shows the dialog box where you can configure the template.
 Click OK. Then, the values for the
Click OK. Then, the values for the stepType parameters are changed to opentsdb and tsdb. Other configuration items are also automatically changed to migrate data from OpenTSDB to TSDB. In addition, the topic names in the help documentation are also changed. You can click the new topic names to obtain details about how to configure “OpenTSDB Reader” and “TSDB Writer”. Figure 9 shows the new topic names.
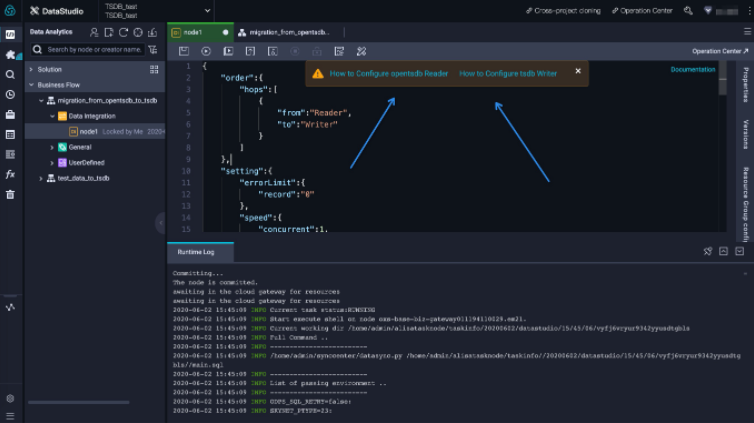 Then, modify the configurations based on the help documentation. You must specify the following five parameters: endpoint, column, beginDateTime, endDateTime, and endpoint. The first endpoint parameter specifies the OpenTSDB endpoint, and the second endpoint parameter specifies the TSDB endpoint. The column parameter determines the metrics that are to be migrated. The beginDateTime and endDateTime parameters determine the time range during which the data is to be migrated. The sample code is described as follows:
Then, modify the configurations based on the help documentation. You must specify the following five parameters: endpoint, column, beginDateTime, endDateTime, and endpoint. The first endpoint parameter specifies the OpenTSDB endpoint, and the second endpoint parameter specifies the TSDB endpoint. The column parameter determines the metrics that are to be migrated. The beginDateTime and endDateTime parameters determine the time range during which the data is to be migrated. The sample code is described as follows:
{ "type":"job", "steps":[ { "stepType":"opentsdb", "parameter":{ "endpoint":"http://host:4242", "column":[ "m" ], "beginDateTime":"20190101000000", "endDateTime":"20190101030000" }, "name":"Reader", "category":"reader" }, { "stepType":"tsdb", "parameter":{ "endpoint":"http://host:8242" }, "name":"Writer", "category":"writer" } ], "version":"2.0", "order":{ "hops":[ { "from":"Reader", "to":"Writer" } ] }, "setting":{ "errorLimit":{ "record":"0" }, "speed":{ "throttle":false, "concurrent":1, "dmu":1 } } }Step 4: Modify the whitelist
To use the default resource group of DataWorks, you must add the CIDR block of the region to the whitelist. For example, to migrate data from OpenTSDB to TSDB, you must configure a whitelist for OpenTSDB and TSDB, respectively.
Find the CIDR blocks that must be added to the whitelist based on the region where the DataWorks workspace resides. For more information, you can navigate through User Guide > Data Integration > Common configurations > Configure a whitelist in the DataWorks V2.0 documentation. The China (Shanghai) region is used as an example to describe how to configure the whitelist.
If your user-created OpenTSDB instances are hosted on an ECS instance, add the corresponding CIDR blocks to the security groups of the ECS instance. The added CIDR blocks must include those for the HBase nodes and TSD nodes. HBase is the underlying data storage system for OpenTSDB.
Then, add the corresponding CIDR blocks to the whitelist of the TSDB instance that runs on the cloud. For more information, you can navigate through Quick Start > Set the IP address whitelist in the TSDB documentation.
Step 5: Synchronize data
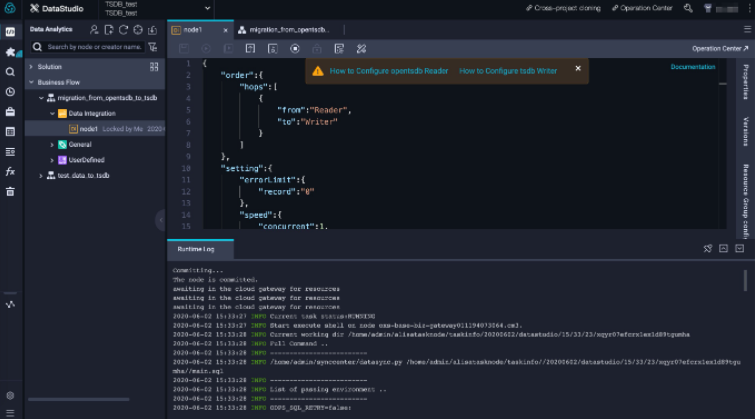
Click the Run icon to run the sync node. Figure 10 shows an example of the execution process.
 Step 6: Create exclusive resource groups
Step 6: Create exclusive resource groups
By default, shared resource groups of DataWorks are used to run nodes. The shared resources may be preempted, and the performance for data migration may be negatively affected. If you have high requirements for the performance, we recommend that you create exclusive resource groups.