Elastic Algorithm Service (EAS) allows you to quickly deploy trained models as online inference services or AI web applications. EAS supports heterogeneous resources and integrates automatic scaling, one-click stress testing, canary releases, and real-time monitoring to ensure service stability in high-concurrency scenarios at a lower cost.
Service architecture
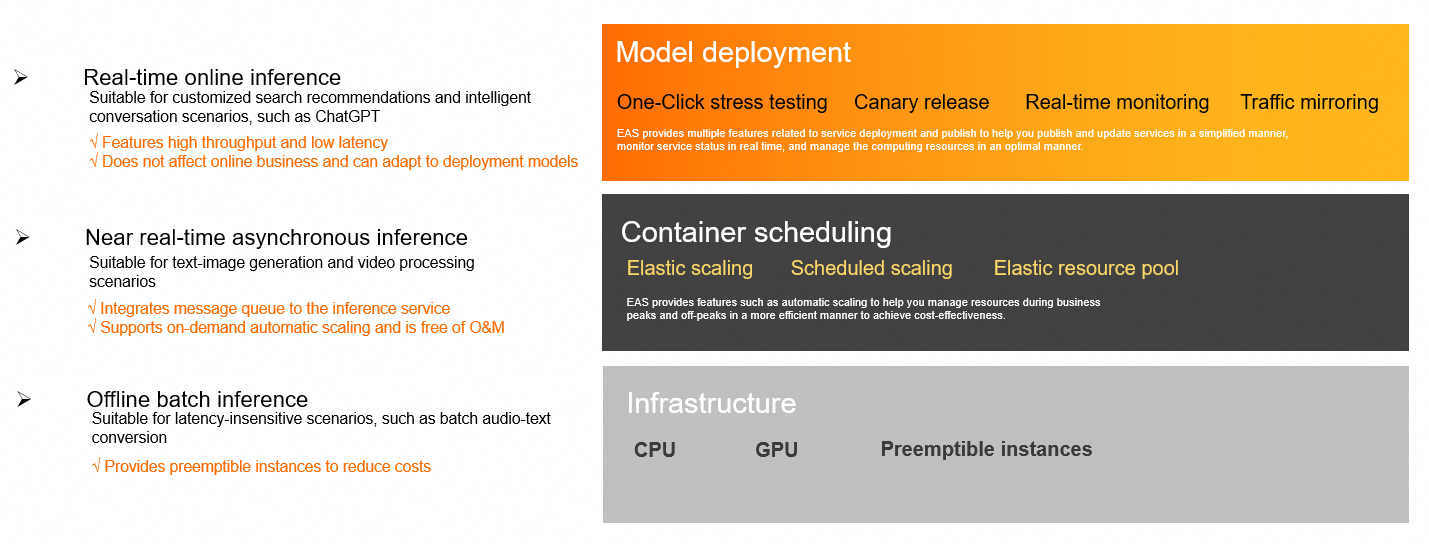
Core capabilities
EAS provides end-to-end capabilities spanning resource management, model deployment, and service O&M to ensure stable and efficient business operations.
Flexible resource and cost management
Heterogeneous hardware support: EAS supports CPUs, GPUs, and specialized AI accelerator instances to meet the performance needs of different models.
Cost optimization: You can use preemptible instances to significantly reduce computing costs. The scheduled scaling feature lets you set policies in advance based on business cycles to precisely control resource allocation.
Elastic resource pools: When a dedicated resource group reaches capacity, new instances are automatically scheduled to a public resource group. This maintains service stability while keeping costs under control.
Comprehensive stability and high availability
Elastic scaling: Automatically adjusts the number of service replicas based on real-time load. This helps handle unpredictable traffic spikes and prevents resource idling or service overload.
High-availability mechanism: An automatic fault recovery mechanism ensures service continuity. Dedicated resources are physically isolated, which eliminates the risk of resource contention.
Safe releases: EAS supports canary releases, which allow you to allocate a percentage of traffic to a new version for validation. It also supports traffic mirroring. You can copy online traffic to a test service for reliability verification without affecting real user requests.
Efficient deployment and O&M
One-click stress testing: Supports dynamic pressure increases and automatically detects service performance limits. You can view second-level monitoring data and stress test reports in real time to quickly evaluate service capabilities.
Real-time monitoring: Provides real-time monitoring for key metrics such as queries per second (QPS), response time, and CPU utilization. You can also enable service monitoring alerts to stay informed about service status.
Multiple deployment methods: You can deploy services using a runtime image (recommended) or a processor. This meets the needs of different technology stacks.
Diverse inference modes
Real-time synchronous inference: This mode features high throughput and low latency. It is suitable for scenarios sensitive to response delays, such as search and recommendation or chatbots.
Near real-time asynchronous inference: This mode has a built-in message queue and is suitable for time-consuming tasks such as text-to-image generation and video processing. It supports automatic scaling based on the queue backlog to prevent request pile-ups.
Offline batch inference: This mode is suitable for batch processing scenarios that are not sensitive to response times, such as batch conversion of voice data. It also supports preemptible instances to control costs.
How it works (runtime image deployment)
An EAS service runs in one or more isolated container instances. The service startup process involves the following core elements:
Runtime image: A read-only template that contains an operating system, base libraries such as CUDA, a language environment such as Python, and necessary dependencies. You can use an official image provided by PAI or create a custom image to meet specific business needs.
Code and model: Your business logic code and model files. Storing them in Object Storage Service (OSS) or File Storage NAS decouples the code and model from the environment. This allows you to update your business code and models without rebuilding the runtime image.
Storage mounting: When an EAS service starts, it mounts the external storage path you specify to a local directory in the container. This allows the code inside the container to access files on the external storage as if they were local files.
Run command: The first command to execute after the container starts. This command is typically used to start an HTTP service to receive inference requests.
The process is as follows:
The service pulls the specified runtime image to create a container.
It then mounts the external storage to the specified path in the container.
It then executes the run command inside the container.
After the command runs successfully, the service listens on the specified port and processes inference requests.

EAS supports two deployment methods: runtime image deployment and processor deployment. We recommend runtime image deployment because it offers greater flexibility and maintainability. In contrast, processor deployment has known limitations regarding environments and frameworks.
Usage flow
Step 1: Preparations
Prepare inference resources: Select an appropriate EAS resource type based on your model size, concurrency requirements, and budget. For guidance on resource selection and purchase configuration, see Overview of EAS deployment resources.
NoteYou must purchase dedicated EAS resources or Lingjun resources before you can use them.
Prepare files: Upload your trained model, code files, and dependencies to a cloud storage service such as OSS. You can then access these files in your service by using storage mounting.
Step 2: Deploy the service
You can deploy and manage services using the console, the EASCMD command line, or an SDK.
Console: Provides custom deployment and scenario-based deployment methods. The console is easy to use and suitable for beginners.
EASCMD command line: Supports operations such as creating, updating, and viewing services. Suitable for algorithm engineers who are familiar with EAS deployment.
SDK: Suitable for large-scale, unified scheduling and O&M.
Step 3: Invoke and stress test the service
Web application: If you deploy your service as an AI-Web application, you can open the interactive page directly in a browser to test it.
API service: Use the online debugging feature to verify the service's functionality. You can also make synchronous or asynchronous invocations through the API. For more information, see Service invocation.
Service stress testing: Use the built-in one-click stress testing tool to test the service's performance under pressure. For more information, see Service stress testing.
Step 4: Monitor and manage the service
Monitoring and alerts: View the running status of your service in the Inference Services list. Enable service monitoring alerts to track service health in real time.
Elastic scaling: Configure automatic scaling or scheduled scaling policies based on your business needs to dynamically manage compute resources.
Service updates: In the Actions column, click Update to deploy a new version. After the update is complete, you can view the version information or switch between versions.
WarningThe service is temporarily interrupted during updates, which may cause dependent requests to fail. Proceed with caution.
Important notes
If an EAS service remains in a non-Running state for 180 consecutive days, the system automatically deletes the service.
For information about the regions where EAS is available, see Regions and zones.
Billing
For more information, see Billing of Elastic Algorithm Service (EAS).
Quick Start
For more information, see Quick Start for Elastic Algorithm Service (EAS).
Scenarios
FAQ
Q: What is the difference between dedicated resources and public resources?
Public resources: Suitable for development, testing, or small-scale applications that are cost-sensitive and can tolerate performance fluctuations. Public resources are low-cost but may experience resource contention during peak hours.
Dedicated resources: Suitable for core services in a production environment that require high service stability and performance. Dedicated resources are physically isolated, which eliminates the risk of preemption. The elastic resource pool feature allows traffic to automatically overflow to public resources when dedicated resources are fully utilized. This balances cost with business stability during peak hours. To reserve instance types that have limited inventory, you must purchase them as dedicated resources.
Q: What are the advantages of EAS compared to self-managed services?
EAS provides managed O&M. It automatically handles resource scheduling, fault recovery, and monitoring. It also provides standardized features such as elastic scaling and canary releases. This allows developers to focus on model development, which reduces O&M costs and accelerates time to market.