

Overview
The development of machine learning technology for AI services relies on data, algorithms, and computing power. Alibaba Cloud AI Acceleration solution leverages leading dataset and GPU accelerators to orchestrate data-intensive applications, optimize utilization of GPU instances, and speed up AI model training and inference tasks. You can also use Alibaba Cloud's customizable cloud-native AI training platform to tailor to your business needs and improve the efficiency for AI infrastructure and daily O&M.
Download WhitepaperSolution Highlights
-

Cost-effective Atomic Acceleration
Speed up AI model training and inferences with the fastest GPU Accelerator, AIACC, according to Stanford DAWN Deep Learning Benchmark to accelerate AI training models by 70% and inference by 2-3 times and reduce cost
-
Highly Efficient GPU Usage
Improve the utilization rate of all GPUs in the cluster with GPU cluster scheduling that shares the resources of the same GPU, and eradicate interference between applications with the GPU isolation mechanism
-

CNCF-Recognized Dataset Accelerator
Resolve high access latency, complex parallel access of multiple data sources, and weak data isolation during AI training with Fluid, the Distributed Dataset Orchestrator and Accelerator for data-intensive applications
-

Customizable AI Training Platform
Build and customize your cloud-native AI training platform with a console for development and O&M by using Alibaba Cloud-Native AI Suite to improve AI engineering efficiency in all stages of deep learning
How It Works
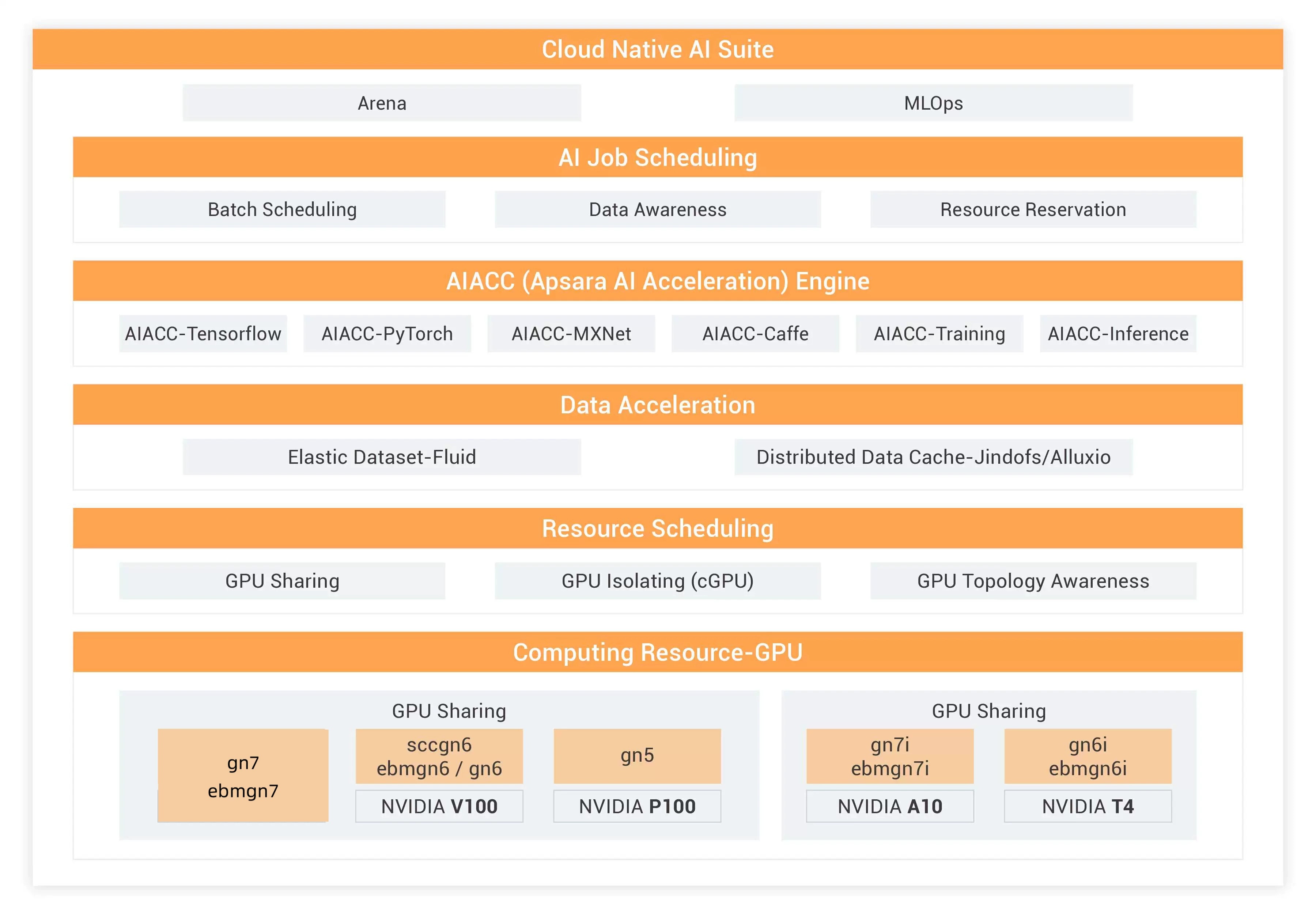
Alibaba AI Acceleration solution include the Cloud-Native AI Suite layer, AI Job Scheduling layer, AI Data Acceleration layer, AI Computing Acceleration Engine layer, Resource Scheduling layer, and Computing Resource layer. Each layer offers specific acceleration solutions based on AI application characteristics in various scenarios.
Cloud-Native AI Suite: Simplify operations with underlying services and components, monitor GPU resource utilization, and collect and analyze logs of AI jobs. You can use command lines to submit AI jobs and check the schedule of model training.
AI Job Scheduling: Schedule AI jobs to accelerate models training, increase GPU utilization, and save costs.
AIACC: Leverage deep learning frameworks such as Tensoflow, PyTorch, MXNet, and Caffe to categorize images and achieve image recognition, Click-Through Rate prediction, Neuro-Linguistic Programming, speech recognition, face recognition, etc.
Data Acceleration: Adopt the architecture with separated storage and computing resources with data stored in different devices from on-premises and model training executed on Alibaba Cloud. Data are stored in small files and warmed up before model training to improve transmission and training efficiency.
Resource Scheduling: Increase GPU utilization and save costs by sharing GPU resources with multiple AI jobs and running single AI jobs on multiple GPUs for distributed model training.
Computing Resources-GPU: Manage and schedule GPU memory and computing power as containers with cGPU to accelerate AI training and inference.
High GPU Utilization with cGPU
Maximize GPU utilization efficiency and save costs by managing and scheduling GPU memory and computing power as containers
Learn MoreUse Cases
Image Recognition
MXNet + SyncBN Distribution training. Performance increased by 50%.

NLP
Natural language processing distribution training. Performance increased 6 times.

Speech Recognition
Speech transform to words. Text sent to students and shown on screen when students are speaking.

CTR (Click-Through Rate)
Distribution training. Performance increased 6.6 times.
Special Offers
Elastic GPU Service
Powerful parallel computing capabilities based on GPU technology

15% OFF
• Deep Learning
• Video Processing
• Scientific Computing
File Storage NAS
Simple, scalable, on-demand and reliable network attached storage for use with ECS instances, HPC and Container Service.
25% OFF
• Pay-as-you-go
• Capacity NAS file systems
• Performance NAS file systems
Container Registry
An enterprise-class platform that provides secure management and efficient distribution of container images
• ACR EE Advanced Edition
• Enterprise-Level Security
• Accelerated Global Distribution
Platform for AI
An end-to-end platform for data mining and analysis
• Visualized Interface
• 100+ Algorithm Components
• Powerful Computing Capability
Security and Compliance
-
 CSA STAR
CSA STAR -
 ISO 27001
ISO 27001 -
 SOC2 Type II Report
SOC2 Type II Report -
 C5
C5 -
 MLPS 2.0
MLPS 2.0 -
 MTCS
MTCS
Customer Success Stories

"Sina Weibo is continuously saving costs by using Function Compute to process image files. We do not need to reserve a large number of idle machine resources to handle traffic surges during peak hours any more. Our engineers do not need to waste time on infrastructure management, such as monitoring server status. Instead, they can focus on working with our product teams to increase business value."
Sina Weibo is a social media platform that is aimed at helping users build better connections. It provides a simple and unprecedented way for users to create posts in real time. Users can interact with each other and connect with people all over the world through viral yet informative content.
Related Resources
Whitepaper
AI Acceleration Whitepaper
This whitepaper is a complete guide on the mechanism of the AI infrastructure layer and how it supports AI acceleration.
Learn More >Best Practice
cGPU (GPU Sharing) for AI Inference
This document introduces the process about how to deploy the cGPU component in the ACK environment.
Learn More >Best Practice
AI Acceleration Demo - AIACC + ACK (Tensorflow)
This demo helps you train ImageNet data with Tensorflow 2.4 by leveraging AIACC, an AI acceleration engine running on ACK (K8s) to speed up your AI training.
Learn More >Best Practice
AI Acceleration Demo - AIACC (TensorFlow)
This solution helps you train ImageNet with TensorFlow 2.4 by leveraging AIACC an AI Acceleration Engine, to speed up your AI training.
Learn More >Best Practice
AI Acceleration Demo - AIACC + ACK (Pytorch)
This solution helps you train ImageNet data with Pytorch 1.9 by leveraging AIACC, an AI Acceleration Engine running on ACK (K8s), to speed up your AI training.
Learn More >Online Course
Accelerating Deep Learning Tasks With AIACC
This demo shows how 18%-74% can be achieved without changes to existing TensorFlow code and demonstrate the power of AIACC using both the standard MNIST handwritten digit dataset, as well as sample COVID-19 chest X-rays.
Learn More >